


According to news on June 8, the domestic multi-modal large language model TigerBot was officially released recently, including two versions of 7 billion parameters and 180 billion parameters. It is now open source on GitHub.
▲ Picture source TigerBot’s GitHub page
It is reported that the innovation brought by TigerBot mainly lies in:
In addition, this model also makes more suitable optimizations from the tokenizer to the training algorithm for the more irregular distribution of the Chinese language.
Researcher Chen Ye said on the official website of Hubo Technology: "This model can quickly understand what type of questions humans have asked using only a small number of parameters. According to the OpenAI InstructGPT paper on the public NLP data set According to the automatic evaluation, TigerBot-7B has reached 96% of the comprehensive performance of OpenAI models of the same size."
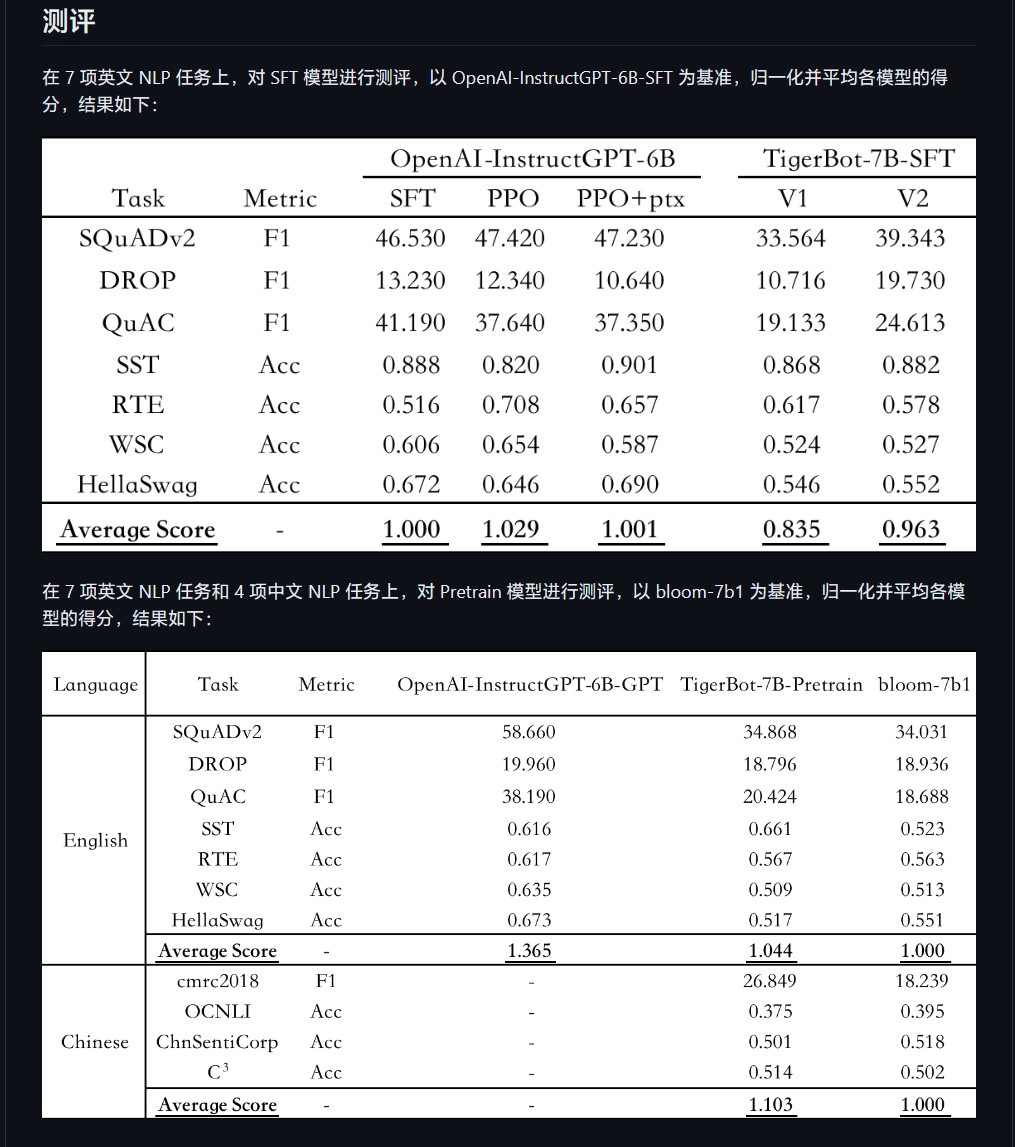
▲ Picture source TigerBot's GitHub page
According to According to the report, the performance of TigerBot-7B-base is "better than that of OpenAI's comparable models." The open source code includes basic training and inference code, and the quantification and inference code of the dual-card inference 180B model. The data includes 100G pre-training data and 1G or 1 million pieces of data for supervised fine-tuning.
IT House friends canfind GitHub’s open source projects here.
The above is the detailed content of The effect can reach 96% of the equivalent model of OpanAI, and the domestic open source AI language model TigerBot is released. For more information, please follow other related articles on the PHP Chinese website!
 What to do if you can't delete files on your computer
What to do if you can't delete files on your computer
 vcruntime140.dll cannot be found and code execution cannot continue
vcruntime140.dll cannot be found and code execution cannot continue
 How to use cloud storage
How to use cloud storage
 How to lock screen on oppo11
How to lock screen on oppo11
 Network cable is unplugged
Network cable is unplugged
 Tutorial on adjusting line spacing in word documents
Tutorial on adjusting line spacing in word documents
 resample function usage
resample function usage
 Digital currency quantitative trading platform
Digital currency quantitative trading platform








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



