


Target detection is a very important basic task in computer vision. Different from common image classification/recognition tasks, target detection requires the model to further give the location and location of the target on top of the given target category. Size information plays a key role in the three major tasks of CV (identification, detection, and segmentation).
The currently popular multi-modal GPT-4 only has the ability of target recognition in terms of visual capabilities, and is unable to complete more difficult target detection tasks. Recognizing the category, location and size information of objects in images or videos is the key to many artificial intelligence applications in real production, such as pedestrian and vehicle recognition in autonomous driving, face locking in security monitoring applications, and medical image analysis. Tumor localization, etc.
Existing target detection methods such as YOLO series, R-CNN series and other target detection algorithms have achieved high target detection accuracy and efficiency due to the continuous efforts of scientific researchers. However, due to Existing methods need to define the set of targets to be detected (closed set) before model training, making them unable to detect targets outside the training set. For example, a model trained to detect faces cannot be used to detect vehicles; In addition, existing methods highly rely on manually labeled data. When the target categories to be detected need to be added or modified, on the one hand, the training data needs to be re-labeled, and on the other hand, the model needs to be re-trained, which is time-consuming and laborious.
A possible solution is to collect massive images and manually label Box information and semantic information, but this will require extremely high labeling costs and use massive data to test the model. Training also poses serious challenges to scientific researchers. Factors such as the long-tail distribution of data and the unstable quality of manual annotation will affect the performance of the detection model.
The article OVR-CNN [1] published in CVPR 2021 proposes a new target detection paradigm: Open-Vocabulary Detection (OVD, also known as Open world target detection) to deal with the problems mentioned above, that is, detection scenarios for unknown objects in the open world.
OVD has attracted continuous attention from academia and industry since it was proposed due to its ability to identify and locate any number and category of targets without manually expanding the amount of annotated data. It also brings new vitality and new challenges to the classic target detection task, and is expected to become a new paradigm for target detection in the future.
Specifically, OVD technology does not require manual annotation of massive images to enhance the detection ability of the detection model for unknown categories, but by converting class-free (class- agnostic) region detector is combined with a cross-modal model trained on massive unlabeled data to expand the target detection model's ability to understand open-world targets through cross-modal alignment of image region features and descriptive text of the target to be detected.
The recent development of cross-modal and multi-modal large model work is very rapid, such as CLIP [2], ALIGN [3] and R2D2 [4], etc., and their development is also It promoted the birth of OVD and the rapid iteration and evolution of related work in the OVD field.
OVD technology involves the solution of two key issues: 1) How to improve the adaptation between region information and cross-modal large models; 2) How to improve pan-category targets The detector's ability to generalize to new categories. From these two perspectives, some related work in the field of OVD will be introduced in detail below.
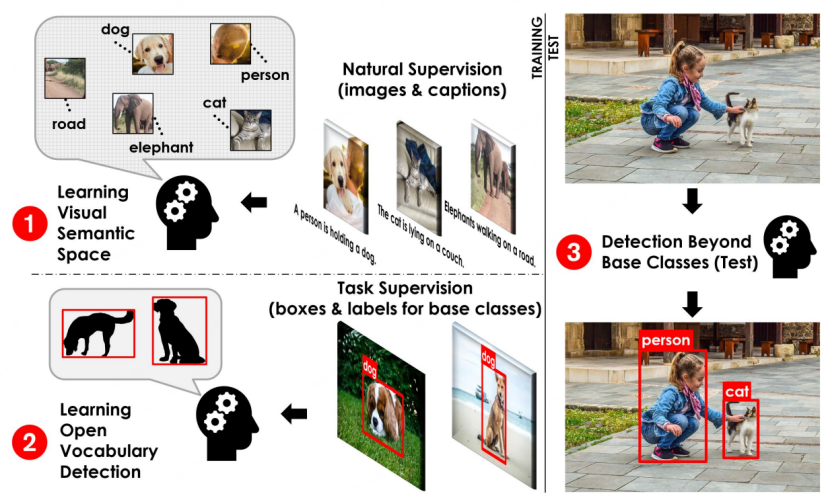
OVD basic process diagram[1]
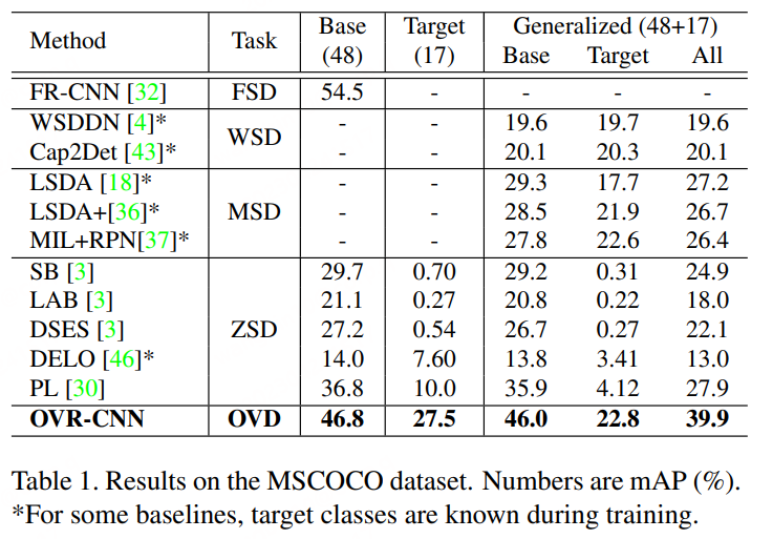
Basic concept of OVD: The use of OVD mainly involves two categories of scenarios: few-shot and zero-shot. few-shot refers to the target category with a small number of manually labeled training samples, and zero-shot It refers to the target category that does not have any manually labeled training samples. On the commonly used academic evaluation data sets COCO and LVIS, the data set is divided into Base class and Novel class, where the Base class corresponds to the few-shot scenario and the Novel class corresponds to the zero-shot scenario. For example, the COCO data set contains 65 categories, and a common evaluation setting is that the Base set contains 48 categories, and only these 48 categories are used in few-shot training. The Novel set contains 17 categories, which are completely invisible during training. The test indicators mainly refer to the AP50 value of the Novel class for comparison.
Paper 1: Open-Vocabulary Object Detection Using Captions

OVR-CNN is the Oral-Paper of CVPR 2021 and a pioneering work in the OVD field. Its two-stage training paradigm has influenced many subsequent OVD works. As shown in the figure below, the first stage mainly uses image-caption pairs to pre-train the visual encoder, in which BERT (fixed parameters) is used to generate word masks, and weakly supervised Grounding matching is performed with ResNet50 loaded with ImageNet pre-trained weights. , the author believes that weak supervision will cause matching to fall into local optimality, so a multi-modal Transformer is added for word mask prediction to increase robustness.
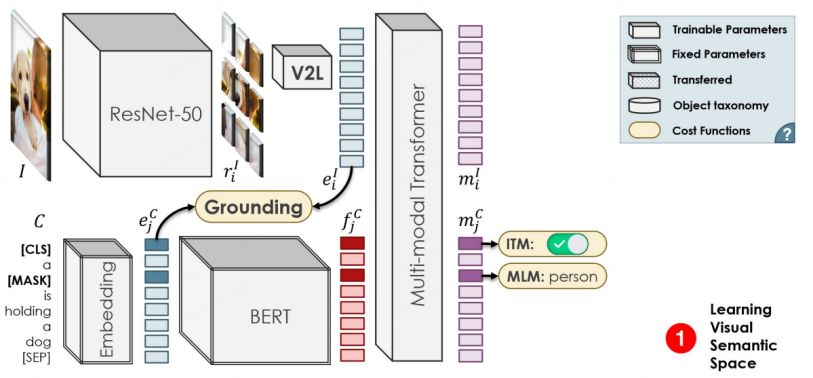
The training process of the second stage is similar to Faster-RCNN. The difference is that the Backbone of feature extraction comes from the The 1-3 layers of ResNet50 obtained in the first stage of pre-training are still used for feature processing after RPN, and the features are then used for Box regression and classification prediction respectively. Classification prediction is the key sign that the OVD task is different from conventional detection. In OVR-CNN, the features are input into the V2L module (graph vector to word vector module with fixed parameters) obtained by one-stage training to obtain a picture and text vector, which is then combined with the label word vector. Match and predict categories. In the second-stage training, the Base class is mainly used to perform box regression training and category matching training on the detector model. Since the V2L module is always fixed, it cooperates with the target detection model's positioning capabilities to migrate to new categories, allowing the detection model to identify and locate targets of a new category.
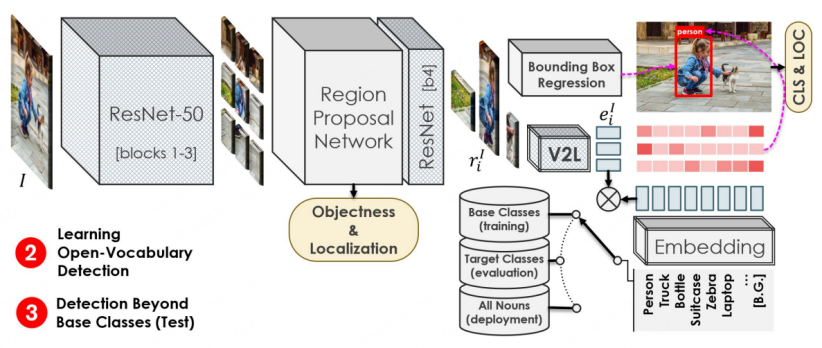
As shown in the figure below, the performance of OVR-CNN on the COCO data set far exceeds the previous Zero-shot target detection algorithm.
##Paper 2: RegionCLIP: Region-based Language-Image Pretraining


1. Extract the words that originally existed in the long text to form a Concept Pool, and further form a set of simple descriptions about the Region for training.
2. Use the RPN based on LVIS pre-training to extract Proposal Regions, and use the original CLIP to match and classify the extracted different Regions with the prepared descriptions, and further assemble them into forged semantic labels. 3. Perform Region-text comparative learning on the new CLIP model using the prepared Proposal Regions and semantic labels, and then obtain a CLIP model that specializes in Region information. 4. In pre-training, the new CLIP model will also learn the classification ability of the original CLIP through the distillation strategy, and perform image-text comparison learning at the full image level to maintain the new The CLIP model has the ability to express the complete image. In the second stage, the obtained pre-trained model is transferred to the detection model for transfer learning. 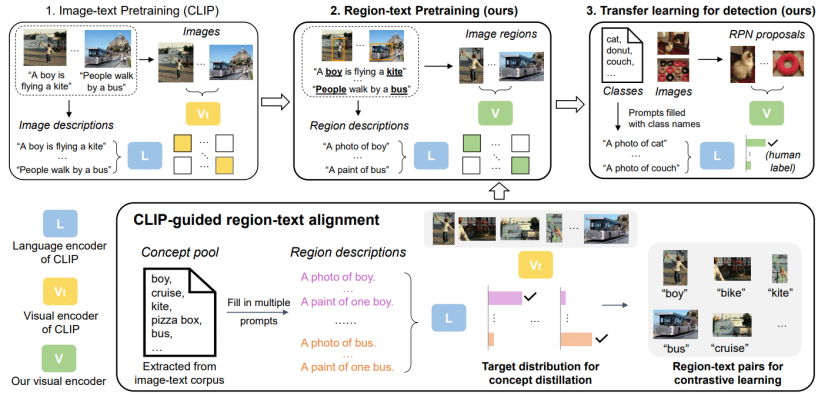
RegionCLIP further expands the representation capabilities of existing large cross-modal models on conventional detection models, thereby achieving Better performance, as shown in the figure below, RegionCLIP has achieved greater improvement in the Novel category compared to OVR-CNN. RegionCLIP effectively improves the adaptability between region information and multi-modal large models through one-stage pre-training. However, CORA believes that when it uses a larger cross-modal large model with larger parameter scale for one-stage training, Training costs will be very high.
Paper 3: CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching

CORA [6] has been included in CVPR 2023. In order to overcome the two obstacles faced by the current OVD tasks proposed by it, a DETR-like OVD model is designed. As shown in the title of the article, the model mainly includes two strategies: Region Prompting and Anchor Pre-Matching. The former uses Prompt technology to optimize the regional features extracted by the CLIP-based regional classifier, thereby alleviating the distribution gap between the whole and the region. The latter uses the anchor point pre-matching strategy in the DETR detection method to improve the OVD model's ability to position new types of objects. generalizability.
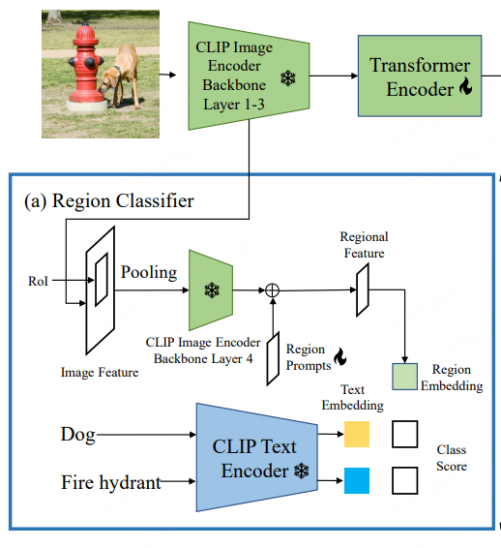
CLIP There is a distribution gap between the overall image features and regional features of the original visual encoder, which in turn causes the detector to The classification accuracy is low (this is similar to the starting point of RegionCLIP). Therefore, CORA proposes Region Prompting to adapt to the CLIP image encoder and improve the classification performance of regional information. Specifically, the entire image is first encoded into a feature map through the first 3 layers of the CLIP encoder, and then anchor boxes or prediction boxes are generated by RoI Align and merged into regional features. This is then encoded by the fourth layer of the CLIP image encoder. In order to alleviate the distribution gap between the full-image feature map and regional features of the CLIP image encoder, learnable Region Prompts are set up and combined with the features output by the fourth layer to generate the final regional features for use with text features. For matching, the matching loss uses a naive cross-entropy loss, and the parameter models related to CLIP are all frozen during the training process.
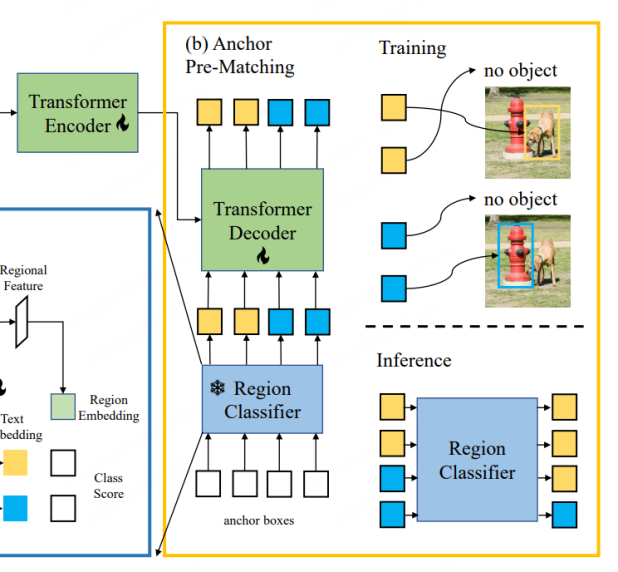
CORA is a DETR-like detector model, similar to DETR, which also uses the anchor pre-matching strategy to generate candidate frames in advance for frame regression training. Specifically, anchor pre-matching matches each label box with the closest set of anchor boxes to determine which anchor boxes should be considered positive samples and which should be considered negative samples. This matching process is usually based on IoU (intersection-over-union ratio). If the IoU between the anchor box and the label box exceeds a predefined threshold, it is regarded as a positive sample, otherwise it is regarded as a negative sample. CORA shows that this strategy can effectively improve the generalization of localization ability to new categories.
However, using the anchor pre-matching mechanism will also bring some problems. For example, training can only be performed normally when at least one anchor box matches the label box. Otherwise, the label box will be ignored, preventing model convergence. Furthermore, even if the label box obtains a more accurate anchor point box, due to the limited recognition accuracy of the Region Classifier, the label box may still be ignored, that is, the category information corresponding to the label box is not aligned with the Region Classifier based on CLIP training. Therefore, CORA uses CLIP-Aligned technology to leverage the semantic recognition capabilities of CLIP and the positioning capabilities of pre-trained ROI to re-label the images in the training data set with less manpower. Using this technology, the model can be trained during training Match more tag boxes.
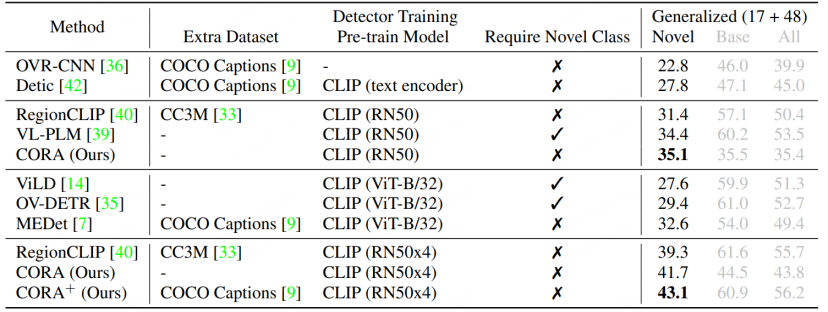
Compared with RegionCLIP, CORA further improves the AP50 value by 2.4 on the COCO data set.
OVD technology is not only closely related to the development of the currently popular cross/multimodal large models, but also inherits the goals of past scientific researchers. The accumulation of technology in the detection field is a successful connection between traditional AI technology and general AI capability research. OVD is a new target detection technology facing the future. It can be expected that OVD's ability to detect and locate any target will in turn promote the further development of multi-modal large models, and is expected to become a multi-modal AGI important cornerstone in development. At present, the training data source of multi-modal large models is a large number of rough information pairs on the Internet, that is, text-image pairs or text-speech pairs. If OVD technology is used to accurately locate the original rough image information and assist in predicting the semantic information of the image to filter the corpus, the quality of the large model pre-training data will be further improved, thereby optimizing the representation and understanding capabilities of the large model.
A good example is SAM (Segment Anything)[7]. SAM not only allows scientific researchers to see the future direction of general visual large models, but also triggers a lot of thinking. It is worth noting that OVD technology can be well connected to SAM to enhance the semantic understanding ability of SAM and automatically generate the box information required by SAM, thereby further liberating manpower. Similarly for AIGC (artificial intelligence generated content), OVD technology can also enhance the ability to interact with users. For example, when the user needs to specify a certain target in a picture to change, or generate a description of the target, they can Utilize OVD's language understanding capabilities and OVD's ability to detect unknown targets to accurately locate the objects described by users, thereby achieving higher quality content generation. Relevant research in the field of OVD is currently booming, and the changes that OVD technology can bring to future general AI large models are worth looking forward to.
The above is the detailed content of Without the need to label massive data, the new paradigm of target detection OVD takes multi-modal AGI a step further. For more information, please follow other related articles on the PHP Chinese website!
 How to bind data in dropdownlist
How to bind data in dropdownlist
 What skills are needed to work in the PHP industry?
What skills are needed to work in the PHP industry?
 Why does my phone keep restarting?
Why does my phone keep restarting?
 The difference between win10 home version and professional version
The difference between win10 home version and professional version
 What are the gsm encryption algorithms?
What are the gsm encryption algorithms?
 The difference between large function and max function
The difference between large function and max function
 Is the speed of php8.0 improved?
Is the speed of php8.0 improved?
 js method to get array length
js method to get array length








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



