Researchers from Cambridge, NAIST and Tencent AI Lab recently released a research result called PandaGPT, which is a method to align and bind large language models with different modalities to achieve cross-modality Techniques for command-following abilities. PandaGPT can accomplish complex tasks such as generating detailed image descriptions, writing stories from videos, and answering questions about audio. It can receive multi-modal inputs simultaneously and combine their semantics naturally.

- ## Project homepage: https://panda-gpt.github.io/
- Code: https://github.com/yxuansu/PandaGPT
- ##Paper: http ://arxiv.org/abs/2305.16355
- Online Demo display: https://huggingface.co/spaces/GMFTBY/PandaGPT
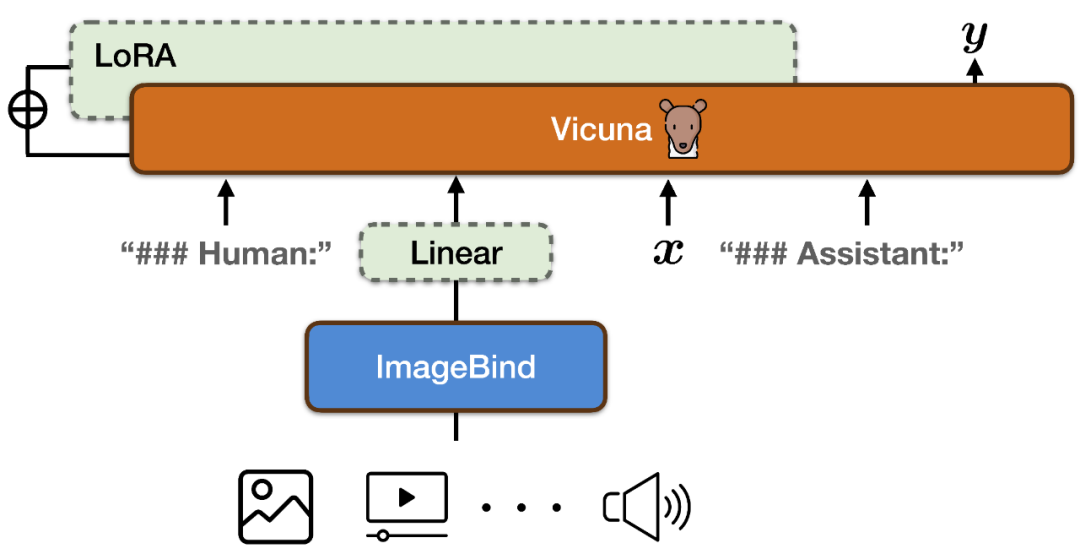
#In order to realize image & video, text, audio, heat map , depth map, IMU readings, command following capabilities in six modalities, PandaGPT combines ImageBind's multi-modal encoder with the Vicuna large language model (as shown in the figure above).
To align the feature spaces of ImageBind's multi-modal encoder and Vicuna's large language model, PandaGPT uses a total of 160k image-based language instructions released by combining LLaVa and Mini-GPT4 Follow the data as training data. Each training instance consists of an image and a corresponding set of dialogue rounds.
In order to avoid destroying the multi-modal alignment nature of ImageBind itself and reduce training costs, PandaGPT only updated the following modules:
Add a linear projection matrix to the encoding result of ImageBind, convert the representation generated by ImageBind and insert it into Vicuna's input sequence;
-
Added additional information to Vicuna's attention module LoRA weight. The total number of parameters of the two accounts for about 0.4% of Vicuna parameters. The training function is a traditional language modeling objective. It is worth noting that during the training process, only the weight of the corresponding part of the model output is updated, and the user input part is not calculated. The entire training process takes about 7 hours to complete on 8×A100 (40G) GPUs.
In the experiment, the author demonstrated PandaGPT's ability to understand different modalities, including image/video-based question and answer, image/video-based creative writing, visual and auditory information-based Reasoning and more, here are some examples:
Image:

Audio:

##Video:
Compared with other multi-modal language models, the most outstanding feature of PandaGPT is its ability to understand and naturally combine information from different modalities.
Video audio:
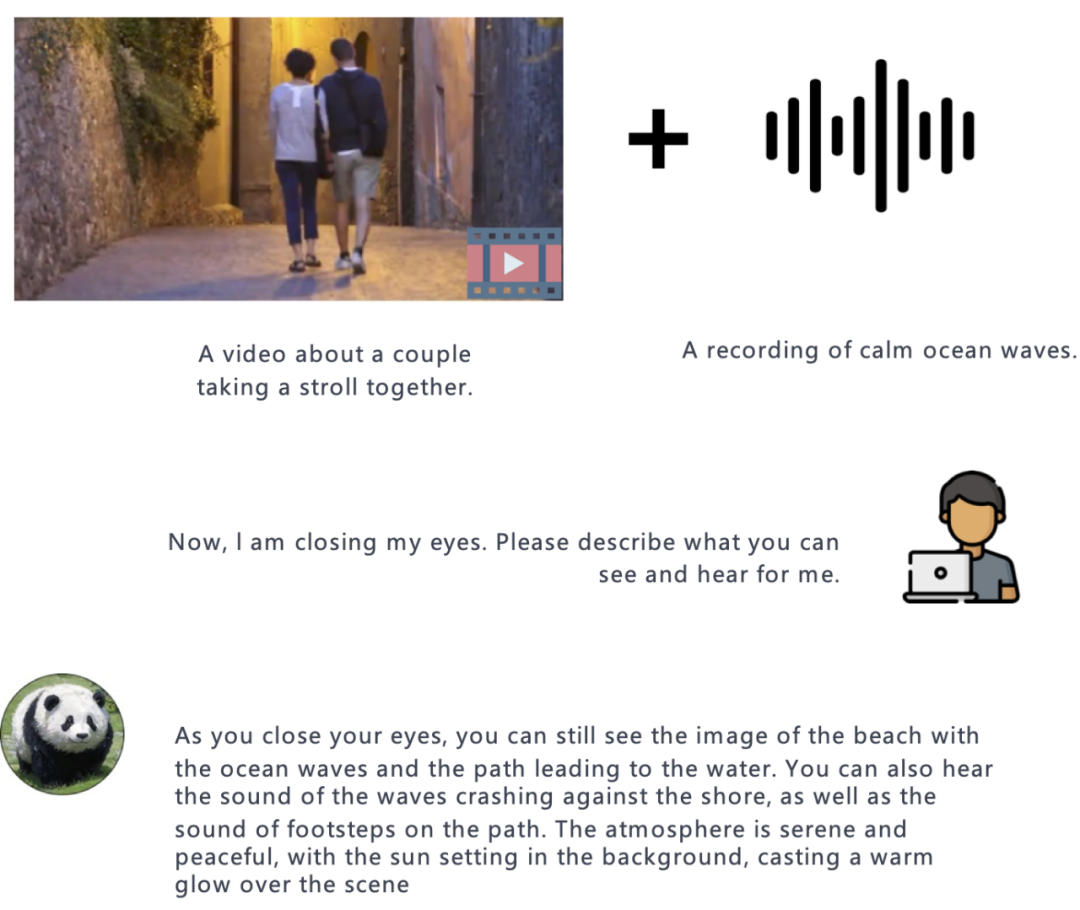
##Image Audio:

##Summary
The authors also summarized the many current problems of PandaGPT and its future development directions. Although PandaGPT has an amazing ability to handle multiple modalities and their combinations, there are still many ways to greatly improve the performance of PandaGPT.
PandaGPT can further improve the understanding of modalities other than images by using other modal alignment data, such as using ASR and TTS data for audio-text modalities. State-of-the-art understanding and ability to follow instructions.
Finally, the authors emphasize that PandaGPT is only a research prototype and is not yet sufficient for direct application in a production environment.
The above is the detailed content of Cambridge, Tencent AI Lab and others proposed the large language model PandaGPT: one model unifies six modalities. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



