


Redis is usually an important component in our business system, such as cache, account login information, rankings, etc.
Once the Redis request delay increases, it may cause an "avalanche" of the business system.
I work for a single matchmaker-type Internet company. During Double Eleven, I launched a campaign to give my girlfriend a gift when I place an order.
Who would have thought that after 12 o'clock in the morning, the number of users increased sharply, and there was a technical glitch that prevented users from placing orders. At that time, the old fire broke out!
After searching, I found that Redis reported Could not get a resource from the pool.
Unable to obtain connection resources, and the number of connections to a single Redis in the cluster is very high.
A large amount of traffic lost the cached response of Redis and hit MySQL directly. In the end, the database also went down...
So various changes were made to the maximum number of connections and the number of connection waits, although error messages were reported. The frequency has eased, but the error still continues.
Later, after offline testing, it was found that the character data stored in Redis was very large, and it took an average of 1s to return the data.
It can be found that once the Redis delay is too high, it will cause various problems.
Today, let’s analyze how to determine whether Redis has performance problems and solutions.
The maximum delay is the time from the client issuing a command to the client receiving the response to the command. Under normal circumstances, the processing time of Redis is very short, at the microsecond level.
When the performance of Redis fluctuates, for example, it reaches a few seconds to more than ten seconds, it is obvious that we can conclude that the performance of Redis has slowed down.
Some hardware configurations are relatively high. When the delay is 0.6ms, we may consider it to be slow. If the hardware is poor, it may take 3 ms before we think there is a problem.
So how do we define whether Redis is really slow?
So, we need to measure the Redis baseline performance of the current environment, which is the basic performance of a system under low pressure and no interference.
When you find that the latency of Redis runtime is more than 2 times the baseline performance, you can determine that Redis performance is slowing down.
Latency baseline measurement
The redis-cli command provides the –intrinsic-latency option to monitor and count the maximum latency during the test period (in milliseconds) , this delay can be used as the baseline performance of Redis.
redis-cli --latency -h `host` -p `port`
For example, execute the following command:
redis-cli --intrinsic-latency 100 Max latency so far: 4 microseconds. Max latency so far: 18 microseconds. Max latency so far: 41 microseconds. Max latency so far: 57 microseconds. Max latency so far: 78 microseconds. Max latency so far: 170 microseconds. Max latency so far: 342 microseconds. Max latency so far: 3079 microseconds. 45026981 total runs (avg latency: 2.2209 microseconds / 2220.89 nanoseconds per run). Worst run took 1386x longer than the average latency.
Note: Parameter 100 is the number of seconds the test will be executed. The longer we run the test, the more likely we are to find latency spikes.
Usually running for 100 seconds is usually appropriate, which is enough to detect latency problems. Of course, we can choose to run several times at different times to avoid errors.
The maximum latency running is 3079 microseconds, so the baseline performance is 3079 (3 milliseconds) microseconds.
It should be noted that we need to run on the Redis server, not the client. In this way, network impact on baseline performance can be avoided.
You can connect to the server through -h host -p port . If you want to monitor the impact of the network on Redis performance, you can use Iperf to measure the network delay from the client to the server.
If the network delay reaches several hundred milliseconds, it may indicate that other high-traffic programs are running, causing network congestion. You need to contact operation and maintenance personnel to coordinate network traffic distribution.
How to determine whether it is a slow instruction?
See if the operation complexity is O(N). The official documentation introduces the complexity of each command. Use O(1) and O(log N) commands as much as possible.
The complexity involving set operations is generally O(N), such as full set query HGETALL, SMEMBERS, and set aggregation operations: SORT, LREM, SUNION, etc.
Is there monitoring data that can be observed? I didn't write the code. I don't know if anyone has used slow instructions.
There are two ways to check:
Use the Redis slow log function to detect slow commands;
latency-monitor tool.
Also, you can use yourself (top, htop, prstat, etc.) to quickly check the CPU consumption of the Redis main process. If CPU usage is high but traffic is low, it usually indicates that slow commands are being used.
Slow log function
The slowlog command in Redis allows us to quickly locate slow commands that exceed the specified execution time. By default, if the command execution time exceeds 10ms will be recorded in the log.
slowlog only records the execution time of the command, excluding IO round-trip operations and slow response caused by network delays.
We can customize the slow command standard based on the baseline performance (configured to 2 times the maximum delay of the baseline performance) and adjust the threshold that triggers the recording of slow commands.
You can enter the following command in redis-cli to configure the command to record for more than 6 milliseconds:
redis-cli CONFIG SET slowlog-log-slower-than 6000
It can also be set in the Redis.config configuration file, in microseconds.
想要查看所有执行时间比较慢的命令,可以通过使用 Redis-cli 工具,输入 slowlog get 命令查看,返回结果的第三个字段以微秒位单位显示命令的执行时间。
假如只需要查看最后 2 个慢命令,输入 slowlog get 2 即可。
示例:获取最近2个慢查询命令
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"以第一个 HGET 命令为例分析,每个 slowlog 实体共 4 个字段:
字段 1:1 个整数,表示这个 slowlog 出现的序号,server 启动后递增,当前为 6。
字段 2:表示查询执行时的 Unix 时间戳。
字段 3:表示查询执行微秒数,当前是 74372 微秒,约 74ms。
字段4表示查询命令及其参数,如果参数数量较多或较大,则只显示部分参数。hgetall max.dsp.blacklist是当前正在执行的命令。
Latency Monitoring
Redis 在 2.8.13 版本引入了 Latency Monitoring 功能,用于以秒为粒度监控各种事件的发生频率。
启用延迟监视器的第一步是设置延迟阈值(单位毫秒)。只有超过该阈值的时间才会被记录,比如我们根据基线性能(3ms)的 3 倍设置阈值为 9 ms。
可以用 redis-cli 设置也可以在 Redis.config 中设置;
CONFIG SET latency-monitor-threshold 9
工具记录的相关事件的详情可查看官方文档:https://redis.io/topics/latency-monitor
如获取最近的 latency
127.0.0.1:6379> debug sleep 2 OK (2.00s) 127.0.0.1:6379> latency latest 1) 1) "command" 2) (integer) 1645330616 3) (integer) 2003 4) (integer) 2003
事件的名称;
事件发生的最新延迟的 Unix 时间戳;
毫秒为单位的时间延迟;
该事件的最大延迟。
Redis 的数据读写由单线程执行,如果主线程执行的操作时间太长,就会导致主线程阻塞。
一起分析下都有哪些操作会阻塞主线程,我们又该如何解决?
网络通信导致的延迟
客户端使用 TCP/IP 连接或 Unix 域连接连接到 Redis。1 Gbit/s 网络的典型延迟约为 200 us。
redis 客户端执行一条命令分 4 个过程:
发送命令-〉 命令排队 -〉 命令执行-〉 返回结果
这个过程称为 Round trip time(简称 RTT, 往返时间),mget mset 有效节约了 RTT,但大部分命令(如 hgetall,并没有 mhgetall)不支持批量操作,需要消耗 N 次 RTT ,这个时候需要 pipeline 来解决这个问题。
Redis pipeline 将多个命令连接在一起来减少网络响应往返次数。
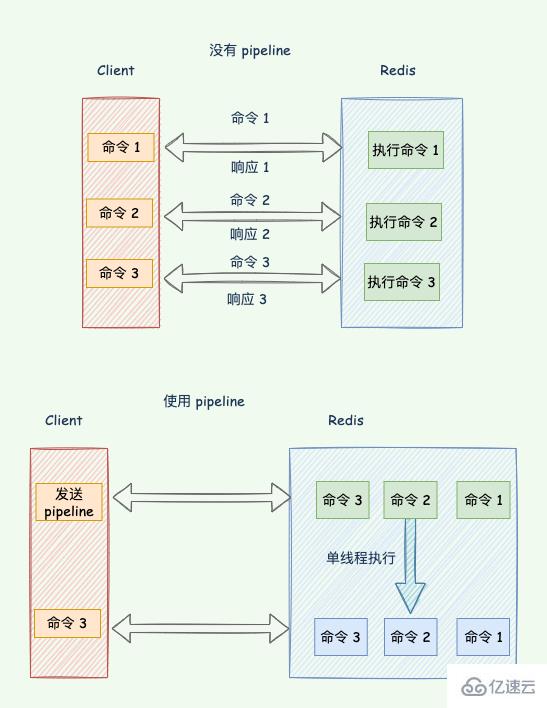
redis-pipeline
慢指令导致的延迟
根据上文的慢指令监控查询文档,查询到慢查询指令。可以通过以下两种方式解决:
在 Cluster 集群中,聚合运算等 O(N) 操作可以在 slave 节点上运行,也可以在客户端端完成。
使用高效的命令代替。采用增量迭代的方法查询数据,避免一次性查询大量数据,在此可参考SCAN、SSCAN、HSCAN和ZSCAN命令。
除此之外,生产中禁用KEYS 命令,它只适用于调试。因为它会遍历所有的键值对,所以操作延时高。
Fork 生成 RDB 导致的延迟
生成 RDB 快照,Redis 必须 fork 后台进程。fork 操作(在主线程中运行)本身会导致延迟。
Redis 使用操作系统的多进程写时复制技术 COW(Copy On Write) 来实现快照持久化,减少内存占用。

写时复制技术保证快照期间数据可修改
但 fork 会涉及到复制大量链接对象,一个 24 GB 的大型 Redis 实例需要 24 GB / 4 kB * 8 = 48 MB 的页表。
执行 bgsave 时,这将涉及分配和复制 48 MB 内存。
此外,从库加载 RDB 期间无法提供读写服务,所以主库的数据量大小控制在 2~4G 左右,让从库快速的加载完成。
内存大页(transparent huge pages)
常规的内存页是按照 4 KB 来分配,Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配。
Redis 使用了 fork 生成 RDB 做持久化提供了数据可靠性保证。
当生成 RDB 快照的过程中,Redis 采用**写时复制**技术使得主线程依然可以接收客户端的写请求。
也就是当数据被修改的时候,Redis 会复制一份这个数据,再进行修改。
采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。
使用以下指令禁用 Linux 内存大页即可:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
swap:操作系统分页
当物理内存(内存条)不够用的时候,将部分内存上的数据交换到 swap 空间上,以便让系统不会因内存不够用而导致 oom 或者更致命的情况出现。
当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在 SWAP 分区中,这个过程称为 SWAP OUT。
当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 SWAP 分区中的数据交换回物理内存中,这个过程称为 SWAP IN。
内存 swap 是操作系统里将内存数据在内存和磁盘间来回换入和换出的机制,涉及到磁盘的读写。
触发 swap 的情况有哪些呢?
对于 Redis 而言,有两种常见的情况:
Redis 使用了比可用内存更多的内存;
与 Redis 在同一机器运行的其他进程在执行大量的文件读写 I/O 操作(包括生成大文件的 RDB 文件和 AOF 后台线程),文件读写占用内存,导致 Redis 获得的内存减少,触发了 swap。
我要如何排查是否因为 swap 导致的性能变慢呢?
Linux 提供了很好的工具来排查这个问题,所以当怀疑由于交换导致的延迟时,只需按照以下步骤排查。
获取 Redis 实例 pid
$ redis-cli info | grep process_id process_id:13160
进入此进程的 /proc 文件系统目录:
cd /proc/13160
在这里有一个 smaps 的文件,该文件描述了 Redis 进程的内存布局,运行以下指令,用 grep 查找所有文件中的 Swap 字段。
$ cat smaps | egrep '^(Swap|Size)' Size: 316 kB Swap: 0 kB Size: 4 kB Swap: 0 kB Size: 8 kB Swap: 0 kB Size: 40 kB Swap: 0 kB Size: 132 kB Swap: 0 kB Size: 720896 kB Swap: 12 kB
每行 Size 表示 Redis 实例所用的一块内存大小,和 Size 下方的 Swap 对应这块 Size 大小的内存区域有多少数据已经被换出到磁盘上了。
如果 Size == Swap 则说明数据被完全换出了。
可以看到有一个 720896 kB 的内存大小有 12 kb 被换出到了磁盘上(仅交换了 12 kB),这就没什么问题。
Redis 本身会使用很多大小不一的内存块,所以,你可以看到有很多 Size 行,有的很小,就是 4KB,而有的很大,例如 720896KB。不同内存块被换出到磁盘上的大小也不一样。
敲重点了
如果 Swap 一切都是 0 kb,或者零星的 4k ,那么一切正常。
当出现百 MB,甚至 GB 级别的 swap 大小时,就表明,此时,Redis 实例的内存压力很大,很有可能会变慢。
解决方案
增加机器内存;
将 Redis 放在单独的机器上运行,避免在同一机器上运行需要大量内存的进程,从而满足 Redis 的内存需求;
增加 Cluster 集群的数量分担数据量,减少每个实例所需的内存。
AOF 和磁盘 I/O 导致的延迟
为了保证数据可靠性,Redis 使用 AOF 和 RDB 快照实现快速恢复和持久化。
可以使用 appendfsync 配置将 AOF 配置为以三种不同的方式在磁盘上执行 write 或者 fsync (可以在运行时使用 CONFIG SET命令修改此设置,比如:redis-cli CONFIG SET appendfsync no)。
no:Redis 不执行 fsync,唯一的延迟来自于 write 调用,write 只需要把日志记录写到内核缓冲区就可以返回。
everysec:Redis 每秒执行一次 fsync。使用后台子线程异步完成 fsync 操作。最多丢失 1s 的数据。
always:每次写入操作都会执行 fsync,然后用 OK 代码回复客户端(实际上 Redis 会尝试将同时执行的许多命令聚集到单个 fsync 中),没有数据丢失。建议使用能够快速执行 fsync 并搭配快速的磁盘的文件系统实现,因为在这种模式下性能通常非常低。
我们通常将 Redis 用于缓存,数据丢失完全恶意从数据获取,并不需要很高的数据可靠性,建议设置成 no 或者 everysec。
除此之外,避免 AOF 文件过大, Redis 会进行 AOF 重写,生成缩小的 AOF 文件。
可以把配置项 no-appendfsync-on-rewrite设置为 yes,表示在 AOF 重写时,不进行 fsync 操作。
也就是说,Redis 实例把写命令写到内存后,不调用后台线程进行 fsync 操作,就直接返回了。
expires 淘汰过期数据
Redis 有两种方式淘汰过期数据:
惰性删除:当接收请求的时候发现 key 已经过期,才执行删除;
定时删除:每 100 毫秒删除一些过期的 key。
定时删除的算法如下:
随机采样 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的 key,删除所有过期的 key;
如果发现还有超过 25% 的 key 已过期,则执行步骤一。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP默认设置为 20,每秒执行 10 次,删除 200 个 key 问题不大。
If the second item is triggered, it will cause Redis to consistently delete expired data to release memory. And deletion is blocking.
What are the trigger conditions?
That is, a large number of keys set the same time parameters. Multiple deduplications are required to reduce the number of expired keys to less than 25%. These keys expire in large numbers within the same second.
In short: A large number of keys expiring at the same time may cause performance fluctuations.
Solution
If a batch of keys does expire at the same time, you can add a random number within a certain size range to the expiration time parameters of EXPIREAT and EXPIRE. , In this way, it not only ensures that the key is deleted within a nearby time range, but also avoids the pressure caused by simultaneous expiration.
bigkey
Usually we will call a Key that contains large data or a large number of members or lists as a big Key. Below we will use several actual An example describes the characteristics of a large Key:
A STRING type Key, its value is 5MB (the data is too large)
A A Key of type LIST, the number of its lists is 10,000 (the number of lists is too many)
A Key of type ZSET, the number of its members is 10,000 (the number of members is too many)
A Key in HASH format has only 1000 members, but the total value size of these members is 10MB (the member size is too large)
bigkey brings the following problems:
Redis memory continues to grow, causing OOM, or reaching the maxmemory setting value, causing write blocking or important keys being evicted;
The memory of a certain node in Redis Cluster far exceeds that of other nodes, but because the minimum granularity of data migration in Redis Cluster is Key, the memory on the node cannot be balanced;
bigkey's read request occupies too much bandwidth, slows down and affects other services on the server;
Deleting a bigkey causes the main library to be blocked for a long time and triggers synchronization Interrupt or master-slave switching;
Find bigkey
Use the redis-rdb-tools tool to find the big key in a customized way.
Solution
Split large key
For example, split a HASH Key containing tens of thousands of members into multiple HASH Keys, and Ensure that the number of members of each Key is within a reasonable range. In the Redis Cluster structure, the splitting of large Keys can play a significant role in memory balance among nodes.
Asynchronous cleaning of large keys
Redis has provided the UNLINK command since 4.0, which can slowly and gradually clean up the incoming Key in a non-blocking manner. Through UNLINK, you can safely delete it Large Key or even Extra Large Key.
The above is the detailed content of How to determine if Redis has performance problems and how to solve them. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



