Index is an ordered data structure that helps MySQL obtain data efficiently. This is MySQL Official definition of index. In order to improve query efficiency, indexes are a mechanism added to fields in database tables. In addition to data, the database system also maintains data structures that satisfy specific search algorithms. These data structures reference (point to) the data in some way, so that advanced search algorithms can be implemented on these data structures. This data structure is an index. . As shown in the diagram below:
In fact, simply speaking, the index is a sorted data structure
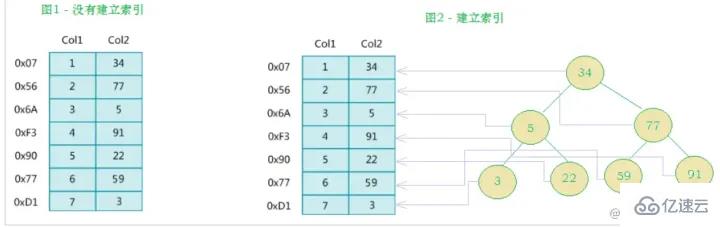
The left side is The data table has a total of two columns and seven records. The leftmost one is the physical address of the data record (note that logically adjacent records are not necessarily physically adjacent on the disk). In order to speed up the search of Col2, you can maintain a binary search tree as shown on the right. Each node contains index key value and a pointer to the physical address of the corresponding data record, so You can use binary search to quickly obtain the corresponding data.
Index advantages
Speed up the speed of search and sort, reduce the IO cost of the database and CPU consumption
By creating a unique index, you can ensure the uniqueness of each row of data in the database table.
Disadvantages of index
The index is actually a table, which saves the primary key and index field and points to the entity Class records themselves need to occupy space
Although it increases query efficiency, for additions, deletions and modifications, every time the table is changed, the index needs to be updated. New additions: naturally need to be in the index tree Deletion of new nodes: The records pointed to in the index tree may become invalid, which means that many nodes in this index tree are invalid changes: the pointing to of the nodes in the index tree may need to be changed
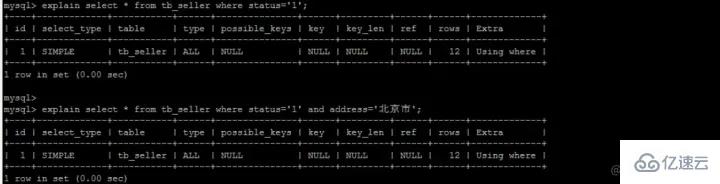
But in fact, we do not use binary search tree to store in MySQL. Why?
You must know that in a binary search tree, a node here can only store one piece of data, and a node corresponds to a disk block in MySQL, so we read one disk block each time , only one piece of data can be obtained, and the efficiency is very low, so we will think of using a B-tree structure to store it.
Index structure
The index is implemented in the storage engine layer of MySQL, not in the server layer. Therefore, indexes may differ between storage engines, and not all engines support all types of indexes.
BTREE index: The most common index type, most indexes support B-tree indexes.
HASH Index: Only supported by the Memory engine, the usage scenario is simple.
R-tree index (spatial index) : Spatial index is a special index type of the MyISAM engine, mainly used for geospatial data types, usually less used , no special introduction will be made.
Full-text (Full-text index) : Full-text index is also a special index type of MyISAM, mainly used for full-text index. InnoDB supports it starting from Mysql5.6 version Full text index.
MyISAM, InnoDB, and Memory storage engines support various index types
INDEX
INNODB ENGINE
MYISAM ENGINE
MEMORY ENGINE
BTREE index
Support
Support
Supported
##HASH index
Not supported
## Not supported
Supported
R-tree index
No Support
Support
Not support
Full-text
Supported after version 5.6
Supported
Not supported
The indexes we usually refer to, unless explicitly stated, are organized using a B-tree (a multi-way search tree, not necessarily binary) structure. Clustered indexes, compound indexes, prefix indexes, and unique indexes called indexes all use B-tree indexes by default.
BTREE
Multi-path balanced search tree, an m-order (m-fork) BTREE satisfies:
Each node can have at most m children. Number: ceil(m/2) to m Number of keywords: ceil(m/2)-1 to m-1
ceil means rounding up, ceil (2.3)=3
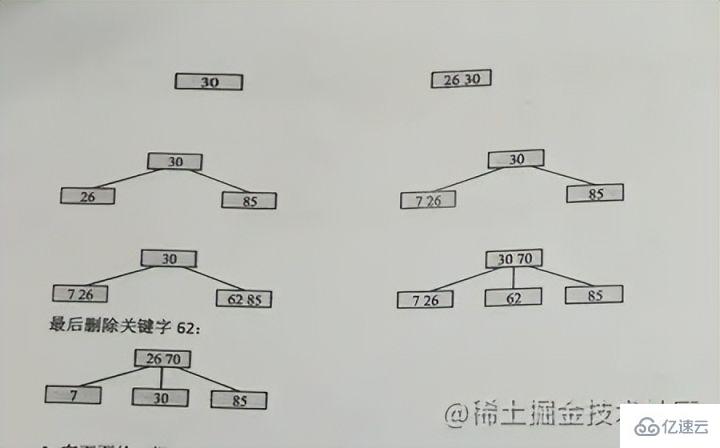
Inserting keyword case
#Guarantee not to destroy the properties of m-order B-tree
Due to 3 The order can only have 2 nodes at most, so 26 and 30 are together at the beginning, and then 85 will start to split. 30 will be the upper middle position, 26 will remain, and 85 will go to the right That is: The middle position The upper position is , then the left side stays at the old node, and the right side goes to the new node
. When 70 is inserted again in the picture, 70 happens to be the upper position in the middle, then 62 is maintained, and 85 is again Split a new node out
After the upper level, it needs to split again
Just continue to split upwards, the same reason
Comparative advantages
Compared with binary search trees, the height/depth is lower and the natural query efficiency is higher.
B TREE
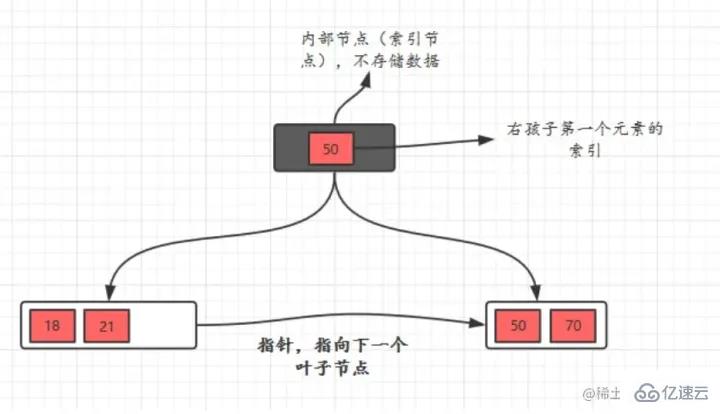
B tree has two types of nodes: internal nodes (also called index nodes) and leaves Node. Internal nodes are non-leaf nodes. Internal nodes do not store data, only indexes, and data are stored in leaf nodes.
The keys in the internal node are arranged in order from from small to large. For a key in the internal node, all keys in the left tree are smaller than It, the keys in the right subtree are greater than or equal to it. Records in leaf nodes are also arranged according to key size.
Each leaf node stores pointers to adjacent leaf nodes, and the leaf nodes themselves are connected in order from small to large according to the size of the keyword.
The parent node stores the index
of the first element of the right child.
Comparative advantages
The query efficiency of B Tree is
more stable. Since only leaf nodes of B Tree store key information, querying any key requires going from the root to the leaves, so it is more stable.
You can traverse the entire tree by just traversing the leaf nodes.
B Tree in MySQLMySql index data structure optimizes the classic B Tree. On the basis of the original B Tree, a
linked list pointer pointing to the adjacent leaf node (the overall structure is similar to a doubly linked list) is formed to form a B Tree with a sequential pointer to improve the performance of interval access.
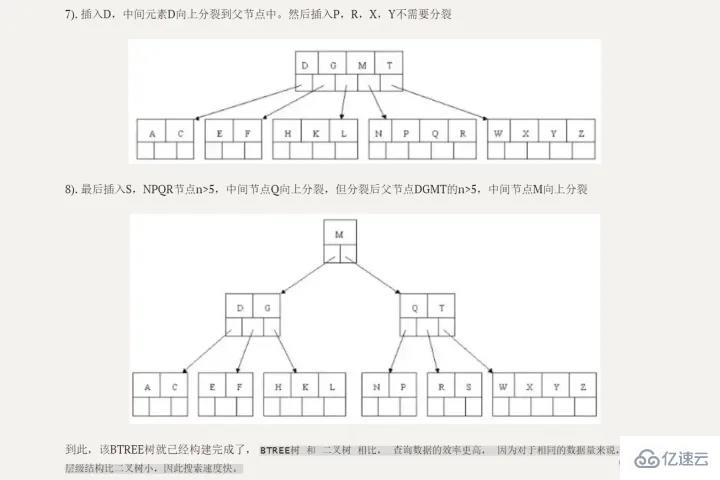
Careful students can see that what is the biggest difference between this picture and our binary search tree diagram?
Transitioning from
binary search tree to B-tree, a significant change is that one node can store multiple data, which is equivalent to one disk block Can store multiple data, greatly reducing our IO times! !
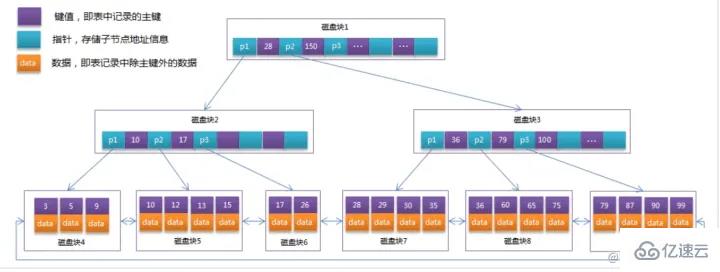
B Tree index structure diagram in MySQL:
##Binary search tree diagram:
Index principle
BTree index:
Initialization introduction
The light blue one is called a disk block, and you can see each disk The block contains several data items (shown in dark blue) and pointers (shown in yellow)
For example, disk block 1 contains data items 17 and 35, including pointers P1, P2, and P3.
P1 represents a disk less than 17 blocks, P2 represents disk blocks between 17 and 35, and P3 represents disk blocks greater than 35.
The real data exists in the leaf nodes
That is, 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. `
Non-leaf nodes do not store real data, only
data items that guide the search direction
, such as 17 and 35 do not actually exist in the data table. `
Search process
If you want to find data item 29, then disk block 1 will first be loaded from the disk to the memory, and an IO will occur at this time. Use a binary search in the memory to determine that 29 is between 17 and 35, and lock the P2 pointer of disk block 1. The memory time is negligible because it is very short (compared to the IO of the disk). Use the disk address of the P2 pointer of disk block 1 to Disk block 3 is loaded from the disk into the memory. The second IO occurs. 29 is between 26 and 30. The P2 pointer of disk block 3 is locked. Disk block 8 is loaded into the memory through the pointer. The third IO occurs. At the same time, the memory passes The binary search reaches 29 and ends the query, resulting in a total of three IOs.
The real situation is that a 3-layer B-tree can represent millions of data. If millions of data searches only require three IOs, the performance improvement will be huge. If there is no index, each data If an IO occurs for each item, a total of millions of IOs will be required. Obviously, the cost is very, very high.
Index classification
An index-organized table is a table stored in primary key order as an index. This method is suitable for the InnoDB engine. Since InnoDB uses the B-tree index model, the data is stored in the B-tree.
Each index corresponds to a B-tree in InnoDB. Assume that we have a table with the primary key column as ID, there is field k in the table, and there is an index on k. The table creation statement of this table is:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
复制代码
Copy after login
The (ID,k) values of R1~R5 in the table are (100,1), (200,2), (300,3), (500,5) and (600,6), the example diagrams of the two trees are as follows:
It is not difficult to see from the figure that according to the contents of the leaf nodes , index types are divided into primary key indexes and non-primary key indexes.
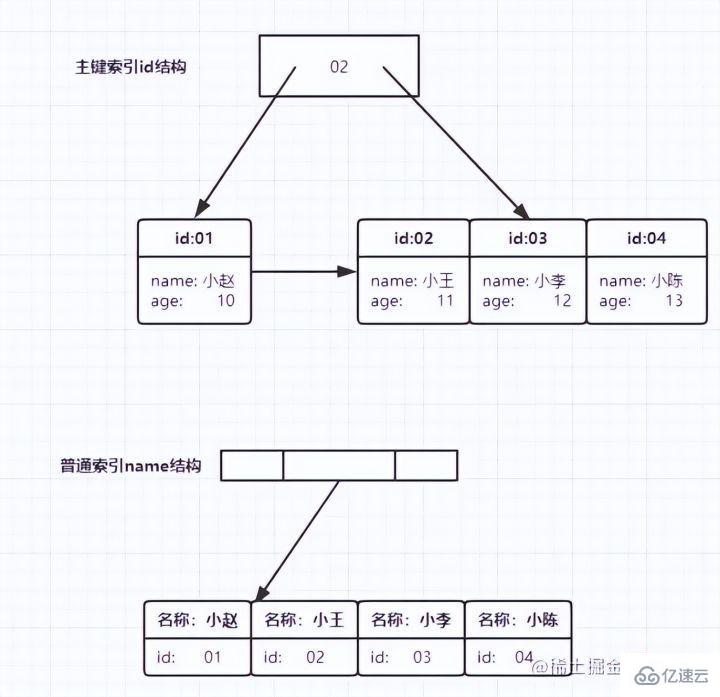
Primary key index
The primary key column of the data table uses the primary key index and will be created by default. This is why, before we learned indexing, the teacher often told us to query based on the primary key. It will be faster. It turns out that the primary key itself is indexed. The leaf node of the primary key index stores the entire row of data. In InnoDB, the primary key index is also called clustered index (clustered index).
Auxiliary index
The leaf node content of the auxiliary index is the value of the primary key. In InnoDB, the auxiliary index is also called Secondary index (secondary index).
As shown below:
The primary key index stores the entire row of data
auxiliary The index only stores itself, and the id primary key is used for table query
According to the above index structure, let’s discuss a question: What is the difference between queries based on primary key index and auxiliary index?
If the statement is select * from T where ID=500, which is the primary key query method, you only need to search the B tree of ID;
If the statement is select * from T where k=5, which is the ordinary index query method, you need to search the k index tree first, and get the ID value of 500, then Search once in the ID index tree . This process is called Returning to the table.
In other words, queries based on auxiliary indexes need to scan one more index tree. Therefore, we should try to use primary key queries in our applications.
Unless the data we want to query happens to exist on our index tree, at this time we call it covering index-that is, the index column contains our All data to be queried.
At the same time, secondary indexes are divided into the following types (just skip it briefly, and we will learn more about it later):
Unique Key (Unique Key): The unique index is also a constraint. The attribute column of the unique index cannot have duplicate data, but the data is allowed to be NULL. A table allows the creation of multiple unique indexes. Most of the time, the purpose of establishing a unique index is for the uniqueness of the data in the attribute column, not for query efficiency.
Ordinary Index (Index): The only function of an ordinary index is to quickly query data. A table allows the creation of multiple ordinary indexes, and allows Data is duplicated and NULL.
Prefix index (Prefix): Prefix index is only applicable to string type data. The prefix index creates an index on the first few characters of the text. Compared with the ordinary index, the data created is smaller because only the first few characters are fetched.
Full Text Index (Full Text): Full text index is mainly used to retrieve keyword information in large text data. It is a type of database currently used by search engines. technology. Before Mysql5.6, only the MYISAM engine supported full-text indexing. After 5.6, InnoDB also supported full-text indexing
Extension--Index pushdown
The so-called pushdown, as the name suggests, actually postpones our table return operation, MySQL will not let us go back easily Table, because it is very wasteful. What does that mean? Consider the following example.
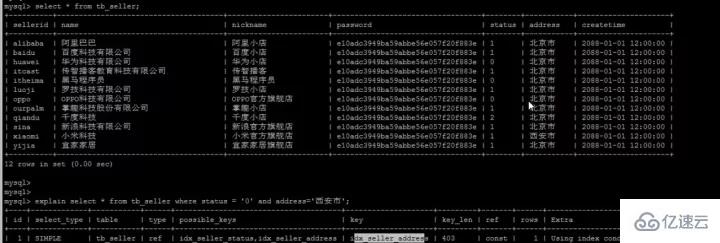
We have established a composite index (name, status, address), which is also stored according to this field, similar to the picture:
Compound index tree (only stores the index column and The primary key is used to return the table)
name
##status
address
id(primary key)
Xiaomi 1
0
1
1
##Xiaomi 2
1
1
2
我们执行这样一条语句:
SELECT name FROM tb_seller WHERE name like '小米%' and status ='1' ;
复制代码
The above is the detailed content of What is the syntax of MySQL index. For more information, please follow other related articles on the PHP Chinese website!
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn











 ##Binary search tree diagram:
##Binary search tree diagram: 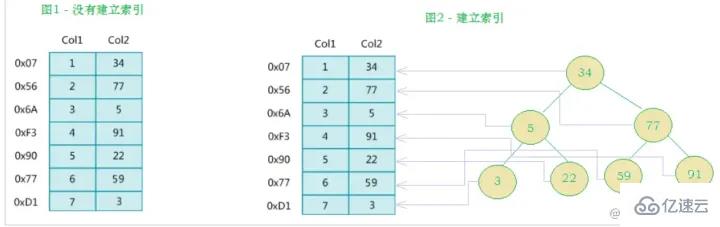 Index principle
Index principle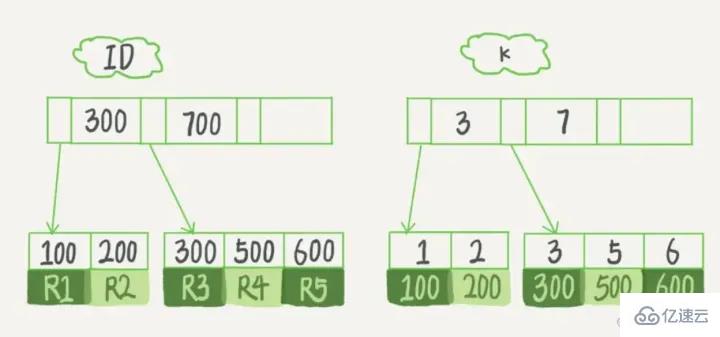












![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



