



On May 9, local time, Meta announced the open source of a new AI model ImageBind that can span 6 different modalities, including vision (image and video forms), temperature (infrared image), text, audio , depth information, motion readings (generated by an inertial measurement unit or IMU). Currently, the relevant source code has been hosted on GitHub.
What does it mean to span 6 modes?
ImageBind takes vision as its core and can freely understand and convert between 6 modes. Meta showed some cases, such as hearing a dog barking and drawing a dog, and giving the corresponding depth map and text description at the same time; such as inputting an image of a bird and the sound of ocean waves, and getting an image of a bird on the beach.
Compared with image generators like Midjourney, Stable Diffusion and DALL-E 2 that pair text with images, ImageBind is more like casting a wide net and can connect text, images/videos, audio, 3D measurements (depth), temperature data (heat) and motion data (from the IMU), and it directly predicts the connections between the data without first training for every possibility, similar to the way humans perceive or imagine the environment.

The researchers stated that ImageBind can be initialized using large-scale visual language models (such as CLIP), thereby leveraging the rich image and text representations of these models. Therefore, ImageBind can be adapted to different modalities and tasks with very little training.
ImageBind is part of Meta’s commitment to creating multimodal AI systems that learn from all relevant types of data. As the number of modalities increases, ImageBind opens the floodgates for researchers to try to develop new holistic systems, such as combining 3D and IMU sensors to design or experience immersive virtual worlds. It also provides a rich way to explore your memory by using a combination of text, video and images to search for images, videos, audio files or text information.
This model is currently only a research project and has no direct consumer or practical applications, but it shows how generative AI can generate immersive, multi-sensory content in the future, and also shows that Meta In a different way from competitors such as OpenAI and Google, it is forging a path towards a large open source model.
Ultimately, Meta believes that ImageBind technology will eventually surpass the current six "senses," saying on its blog, "While we explored six modes in the current study, we believe in introducing as many connections as possible New modalities of senses—such as touch, speech, smell, and brain fMRI signals—will enable richer human-centered artificial intelligence models.”
Use of ImageBind
If ChatGPT can serve as a search engine and question and answer community, and Midjourney can be used as a drawing tool, what can you do with ImageBind?
According to the official demo, it can generate audio directly from pictures:
You can also generate pictures from audio:
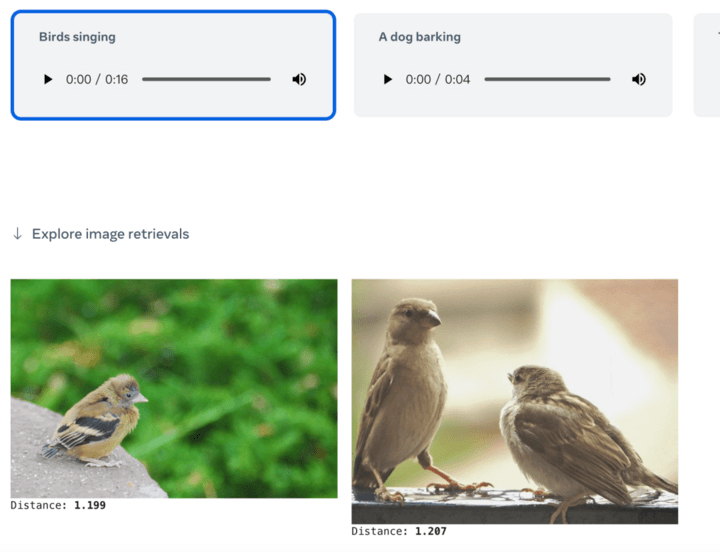
Or you can retrieve related pictures or audio content directly by giving a text:
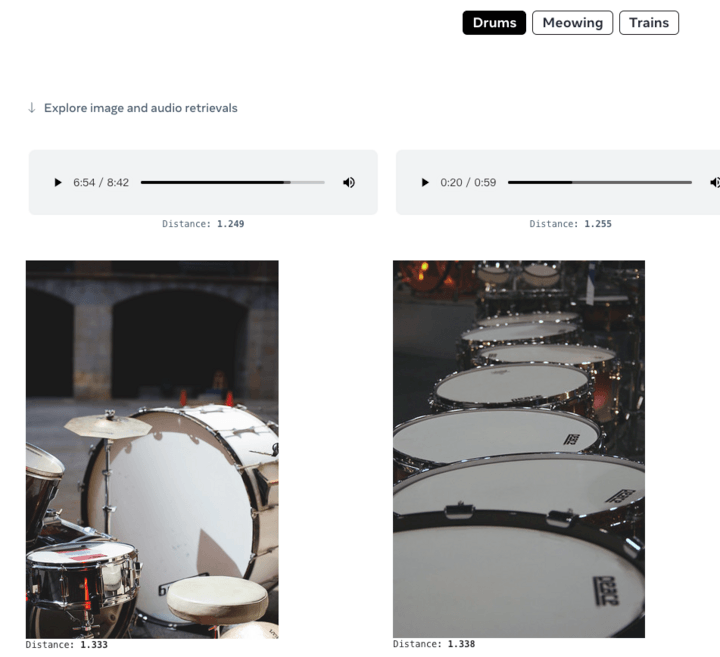
You can also give audio and generate corresponding images:
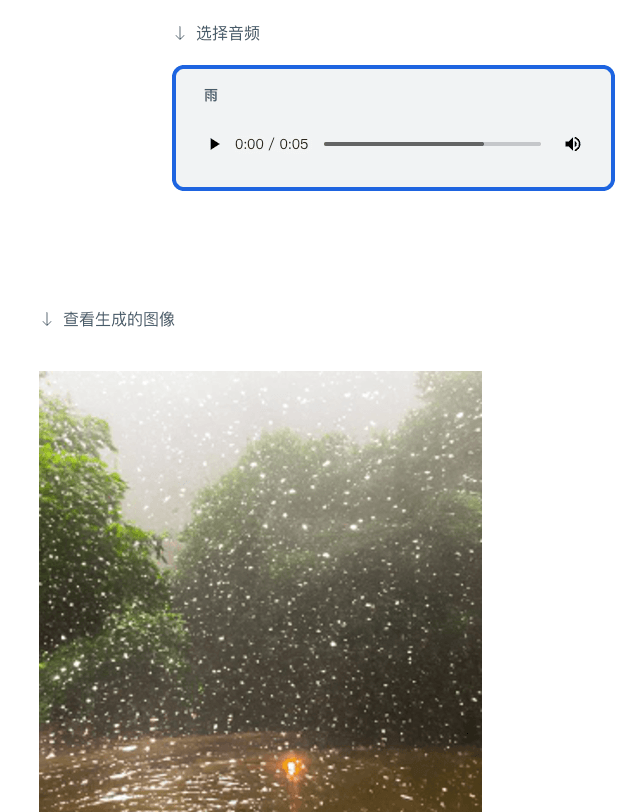
As mentioned above, ImageBind provides a way for future generative AI systems to be presented in multiple modalities, and at the same time, combined with Meta's internal virtual reality, mixed reality, metaverse and other technologies and scenarios. Using tools like ImageBind will open new doors in accessible spaces, for example, generating real-time multimedia descriptions to help people with vision or hearing impairments better perceive their immediate environment.
There is still a lot to be discovered about multimodal learning. Currently, the field of artificial intelligence has not effectively quantified scaling behaviors that only appear in larger models and understood their applications. ImageBind is a step toward evaluating and demonstrating new applications for image generation and retrieval in a rigorous manner.
Author: Ballad
Source: First Electric Network (www.d1ev.com)
The above is the detailed content of AI Morning Post | What is the experience of text, image, audio and video, and 3D generating each other?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



