


In 2017, the Google Brain team creatively proposed the Transformer architecture in its paper "Attention Is All You Need". Since then, this research has been a success and has become one of the most popular models in the NLP field today. One, it is widely used in various language tasks and has achieved many SOTA results.
Not only that, Transformer, which has been leading the way in the field of NLP, has quickly swept across fields such as computer vision (CV) and speech recognition, and has achieved good results in tasks such as image classification, target detection, and speech recognition. Effect.

Paper address: https://arxiv.org/pdf/1706.03762 .pdf
#Since its launch, Transformer has become the core module of many models. For example, the familiar BERT, T5, etc. all have Transformer. Even ChatGPT, which has become popular recently, relies on Transformer, which has already been patented by Google.

## Source: https://patentimages.storage.googleapis.com /05/e8/f1/cd8eed389b7687/US10452978.pdf
In addition, the series of models GPT (Generative Pre-trained Transformer) released by OpenAI has Transformer in the name, visible Transformer It is the core of the GPT series of models.
At the same time, OpenAI co-founder Ilya Stutskever recently said when talking about Transformer that when Transformer was first released, it was actually the second day after the paper was released. I couldn’t wait to switch my previous research to Transformer, and then GPT was introduced. It can be seen that the importance of Transformer is self-evident.
Over the past 6 years, models based on Transformer have continued to grow and develop. Now, however, someone has discovered an error in the original Transformer paper.
Transformer architecture diagram and code are "inconsistent"The person who discovered the error was Sebastian, a well-known machine learning and AI researcher and the chief AI educator of the startup Lightning AI. Raschka. He pointed out that the architecture diagram in the original Transformer paper was incorrect, placing layer normalization (LN) between residual blocks, which was inconsistent with the code.
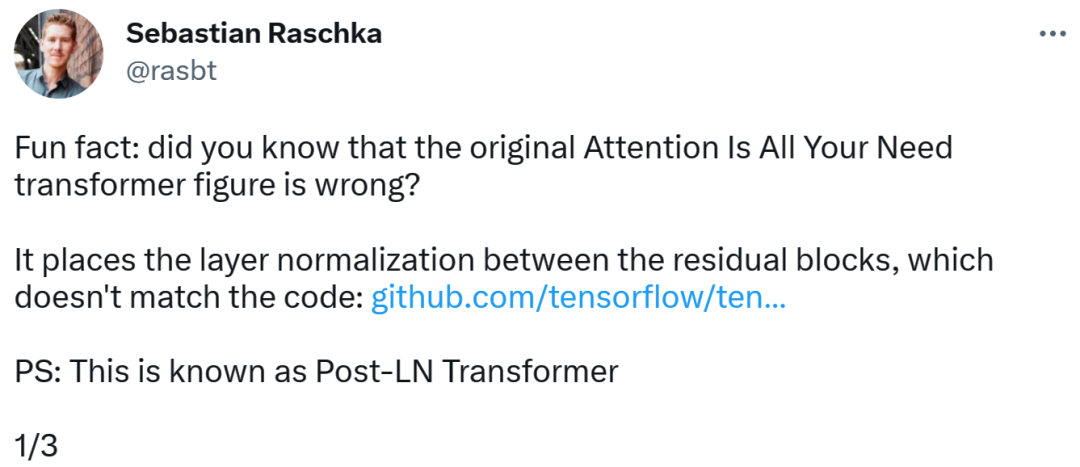
Transformer architecture diagram is as follows on the left, and on the right is the Post-LN Transformer layer (from the paper "On Layer Normalization in the Transformer Architecture" [1]).
The inconsistent code part is as follows. Line 82 writes the execution sequence "layer_postprocess_sequence="dan"", which means that the post-processing executes dropout, residual_add and layer_norm in sequence. If add&norm in the left middle of the above picture is understood as: add is above norm, that is, norm first and then add, then the code is indeed inconsistent with the picture.
Code address:
https://github.com/tensorflow/tensor2tensor/commit/ f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef16871bdbf46bf04dfe7f1477bafb884748f08197c9cf1b10a4dd78e…
Next, Sebastian He also stated that the paper "On Layer Normalization in the Transformer Architecture" believes that Pre-LN performs better and can solve the gradient problem. . This is what many or most architectures do in practice, but it can lead to representation corruption.
Better gradients can be achieved when layer normalization is placed in the residual connection before the attention and fully connected layers.
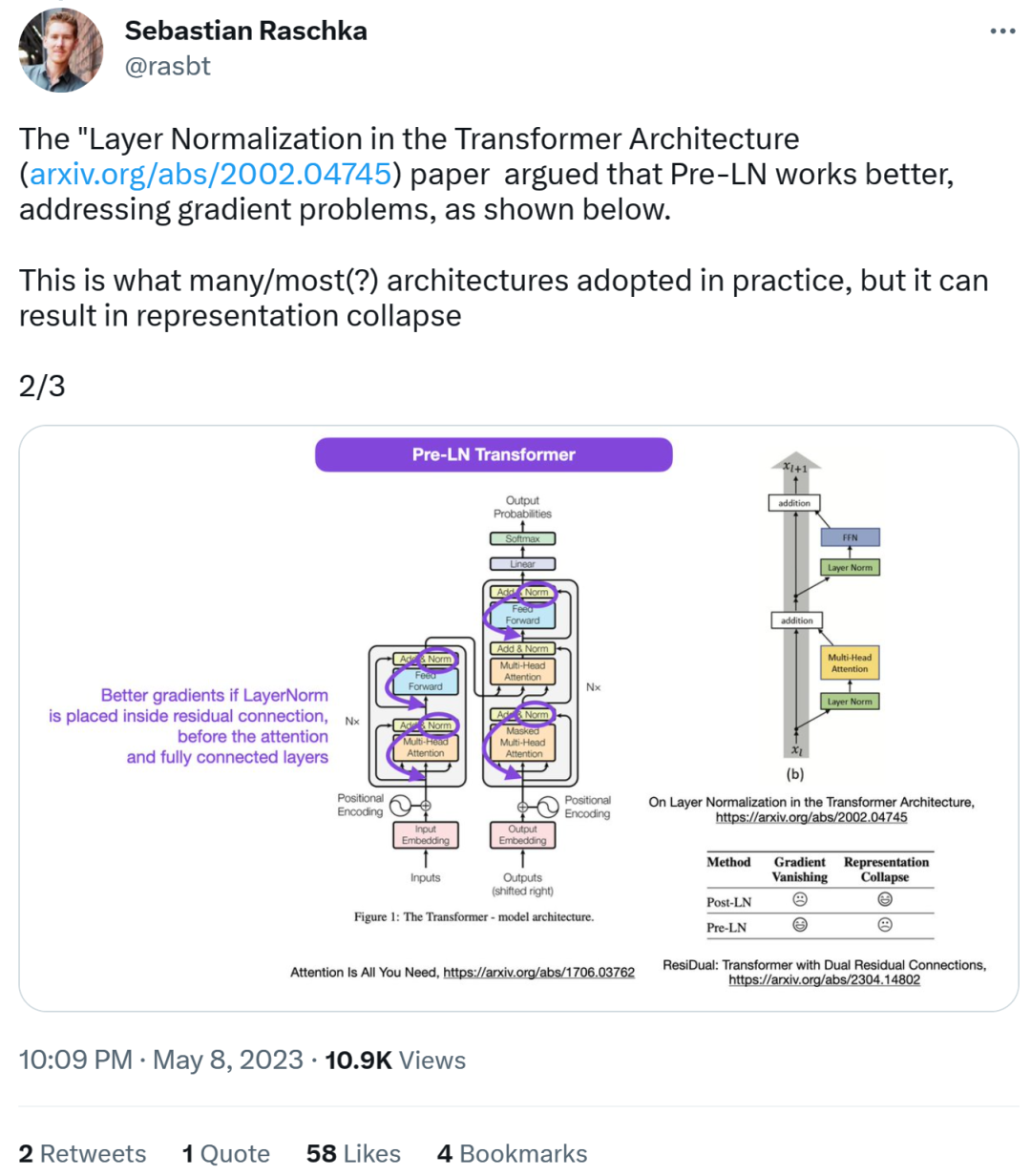
So while the debate about Post-LN or Pre-LN continues, another paper combines These two points are addressed in "ResiDual: Transformer with Dual Residual Connections"[2].
Regarding Sebastian’s discovery, some people think that we often encounter papers that are inconsistent with the code or results. Most of it is honest, but sometimes it's strange. Considering the popularity of the Transformer paper, this inconsistency should have been mentioned a thousand times over.
Sebastian replied that, to be fair, the "most original" code was indeed consistent with the architecture diagram, but the code version submitted in 2017 was modified and the architecture diagram was not updated. So, this is really confusing.
As one netizen said, "The worst thing about reading code is that you will You often find small changes like this, and you don’t know if they were intentional or not. You can’t even test it because you don’t have enough computing power to train the model.”
I wonder what Google will do in the future Whether to update the code or the architecture diagram, we will wait and see!
The above is the detailed content of The picture is inconsistent with the code. An error was found in the Transformer paper. Netizen: It should have been pointed out 1,000 times.. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



