


Transformer is the most powerful seq2seq architecture today. Pretrained transformers typically have context windows of 512 (e.g. BERT) or 1024 (e.g. BART) tokens, which is long enough for many current text summarization datasets (XSum, CNN/DM).
But 16384 is not an upper limit on the length of context required to generate: tasks involving long narratives, such as book summaries (Krys-´cinski et al., 2021) or narrative question and answer (Kociskýet al. ., 2018), typically inputting more than 100,000 tokens. The challenge set generated from Wikipedia articles (Liu* et al., 2018) contains inputs of more than 500,000 tokens. Open-domain tasks in generative question answering can synthesize information from larger inputs, such as answering questions about the aggregated properties of articles by all living authors on Wikipedia. Figure 1 plots the sizes of several popular summarization and Q&A datasets against common context window lengths; the longest input is more than 34 times longer than Longformer’s context window.
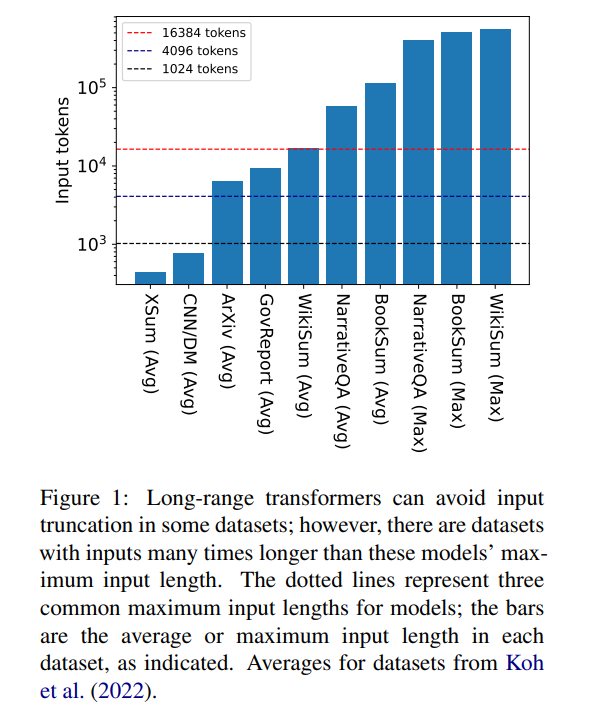
In the case of these very long inputs, the vanilla transformer cannot scale because the native attention mechanism has quadratic complexity. Long input transformers, while more efficient than standard transformers, still require significant computational resources that increase as the context window size increases. Furthermore, increasing the context window requires retraining the model from scratch with the new context window size, which is computationally and environmentally expensive.
In the article "Unlimiformer: Long-Range Transformers with Unlimited Length Input", researchers from Carnegie Mellon University introduced Unlimiformer. This is a retrieval-based approach that augments a pre-trained language model to accept infinite-length input at test time.

Paper link: https://arxiv.org/pdf/2305.01625v1.pdf
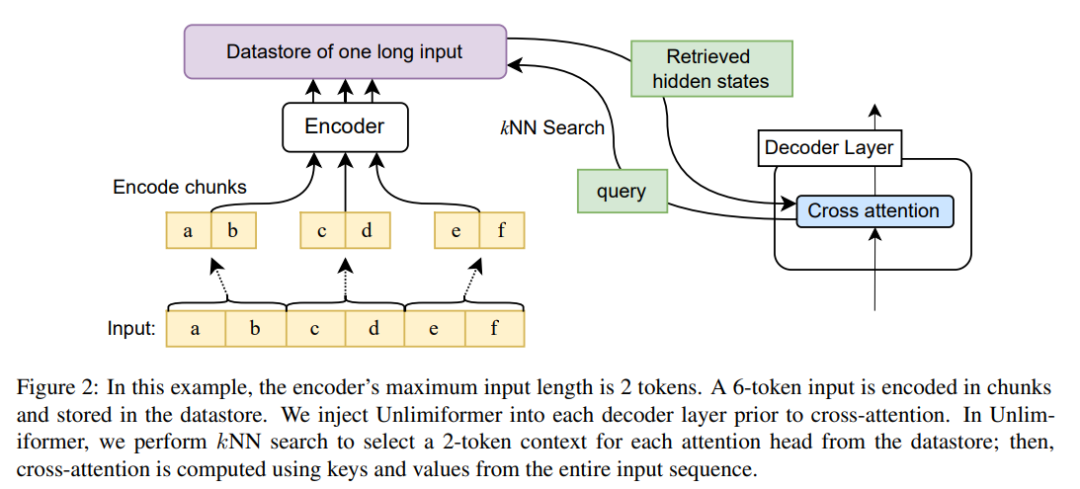
Unlimiformer can be injected into any existing encoder-decoder transformer, capable of handling input of unlimited length. Given a long input sequence, Unlimiformer can build a data store on the hidden states of all input tokens. The decoder's standard cross-attention mechanism is then able to query the data store and focus on the top k input tokens. The data store can be stored in GPU or CPU memory and can be queried sub-linearly.
Unlimiformer can be applied directly to a trained model and can improve existing checkpoints without any further training. The performance of Unlimiformer will be further improved after fine-tuning. This paper demonstrates that Unlimiformer can be applied to multiple base models, such as BART (Lewis et al., 2020a) or PRIMERA (Xiao et al., 2022), without adding weights and retraining. In various long-range seq2seq data sets, Unlimiformer is not only stronger than long-range Transformers such as Longformer (Beltagy et al., 2020b), SLED (Ivgi et al., 2022) and Memorizing transformers (Wu et al., 2021) on these data sets The performance is better, and this article also found that Unlimiform can be applied on top of the Longformer encoder model to make further improvements.
Since the size of the encoder context window is fixed, the maximum input length of the Transformer is limited. However, during decoding, different information may be relevant; furthermore, different attention heads may focus on different types of information (Clark et al., 2019). Therefore, a fixed context window may waste effort on tokens to which attention is less focused.
At each decoding step, each attention head in Unlimiformer selects a separate context window from all inputs. This is achieved by injecting the Unlimiformer lookup into the decoder: before entering the cross-attention module, the model performs a k-nearest neighbor (kNN) search in the external data store, selecting a set of each attention head in each decoder layer. token to participate.
coding
In order to encode input sequences longer than the context window length of the model, this article encodes the input overlapping blocks according to the method of Ivgi et al. (2022) (Ivgi et al., 2022), only The middle half of the output for each chunk is retained to ensure sufficient context before and after the encoding process. Finally, this article uses libraries such as Faiss (Johnson et al., 2019) to index encoded inputs in data stores (Johnson et al., 2019).
Retrieve enhanced cross-attention mechanism
In the standard cross-attention mechanism, the decoder of the transformer Focusing on the final hidden state of the encoder, the encoder usually truncates the input and encodes only the first k tokens in the input sequence.
This article does not only focus on the first k tokens of the input. For each cross attention head, it retrieves the first k hidden states of the longer input series and only focuses on the first k tokens. k. This allows the keyword to be retrieved from the entire input sequence rather than truncating the keyword. Our approach is also cheaper in terms of computation and GPU memory than processing all input tokens, while typically retaining over 99% of attention performance.
Figure 2 shows this article’s changes to the seq2seq transformer architecture. The complete input is block-encoded using the encoder and stored in a data store; the encoded latent state data store is then queried when decoding. The kNN search is non-parametric and can be injected into any pretrained seq2seq transformer, as detailed below.
Long document summary
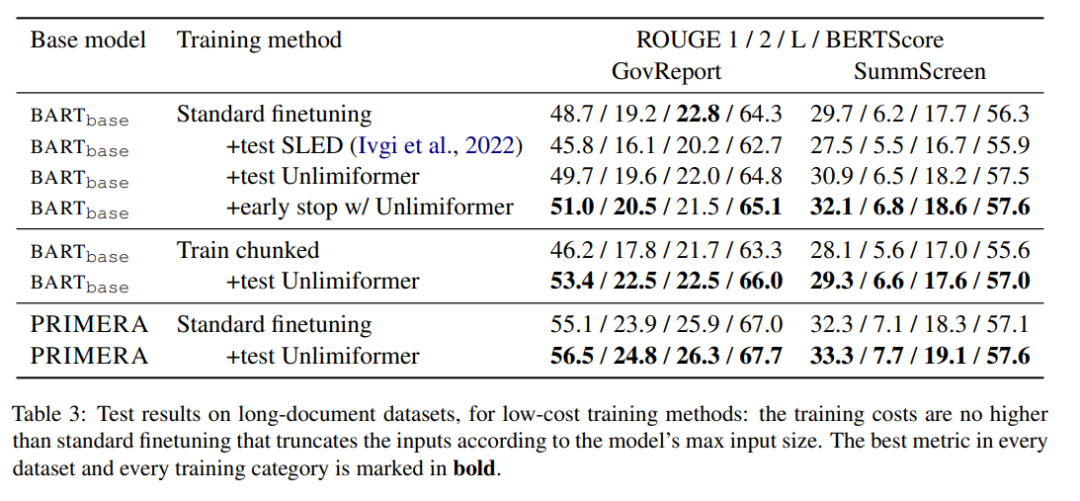
Table 3 shows the results in the long text (4k and 16k token input) summary dataset.
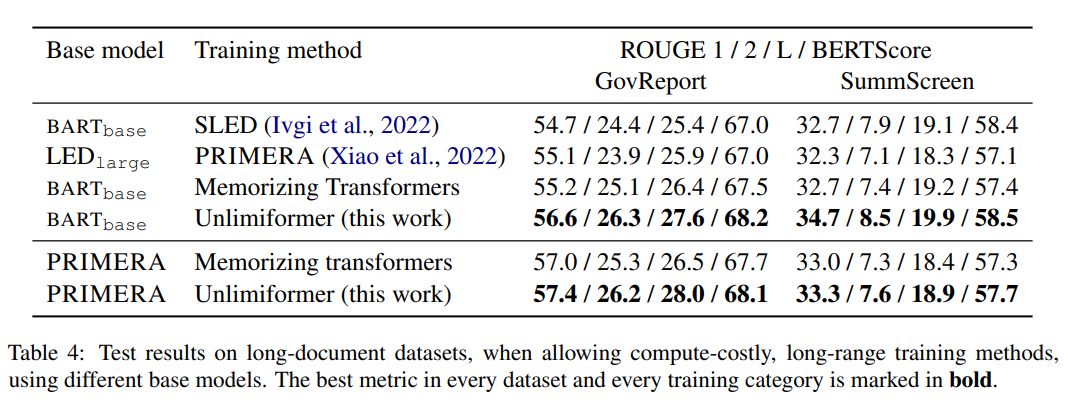
Among the training methods in Table 4, Unlimiformer can achieve the best in various indicators.
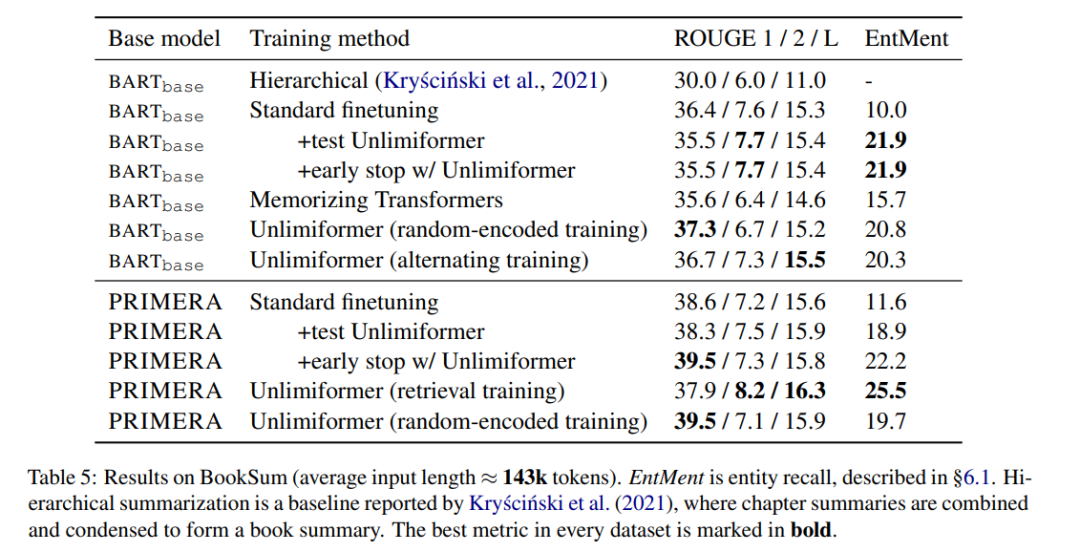
Book Summary
Table 5 Display Results on book abstracts. It can be seen that based on BARTbase and PRIMERA, applying Unlimiformer can achieve certain improvement results.
The above is the detailed content of GPT-4's 32k input box is still not enough? Unlimiformer stretches the context length to infinite length. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



