


Some time ago, Google’s leaked internal documents expressed the view that although on the surface it seems that OpenAI and Google are chasing each other on large AI models, the real winner may not come from these two, because There is a third party force that is quietly rising. This power is "open source".
Around Meta's LLaMA open source model, the entire community is rapidly building models with similar capabilities to OpenAI and Google's large models. Moreover, the open source model iterates faster and is more customizable. More privacy.
Recently, Sebastian Raschka, former assistant professor at the University of Wisconsin-Madison and chief AI education officer of the startup Lightning AI, said that The past month has been very difficult for open source. great.
However, with so many large language models (LLM) emerging one after another, it is not easy to keep a firm grasp of all models. So, in this article, Sebastian shares resources and research insights on the latest open source LLMs and datasets.
There have been so many research papers appearing in the past month that it can be difficult to choose from them Select the most favorite ones for in-depth discussion. Sebastian prefers papers that provide additional insights rather than simply demonstrate more powerful models. In view of this, what first caught his attention was the Pythia paper co-authored by researchers from Eleuther AI and Yale University and other institutions.

Paper address: https://arxiv.org/pdf/2304.01373.pdf
#Pythia: Gaining insights from large-scale training
Open source Pythia family of large models is really the other autoregressive decoding An interesting alternative to the container-style model (i.e. GPT-like model). The paper reveals some interesting insights into the training mechanism and introduces corresponding models ranging from 70M to 12B parameters.
The Pythia model architecture is similar to GPT-3 but includes improvements such as Flash attention (like LLaMA) and rotational position embedding (like PaLM). At the same time, Pythia was trained with 300B tokens on the 800GB diverse text data set Pile (1 epoch on the regular Pile and 1.5 epoch on the deduplication Pile).
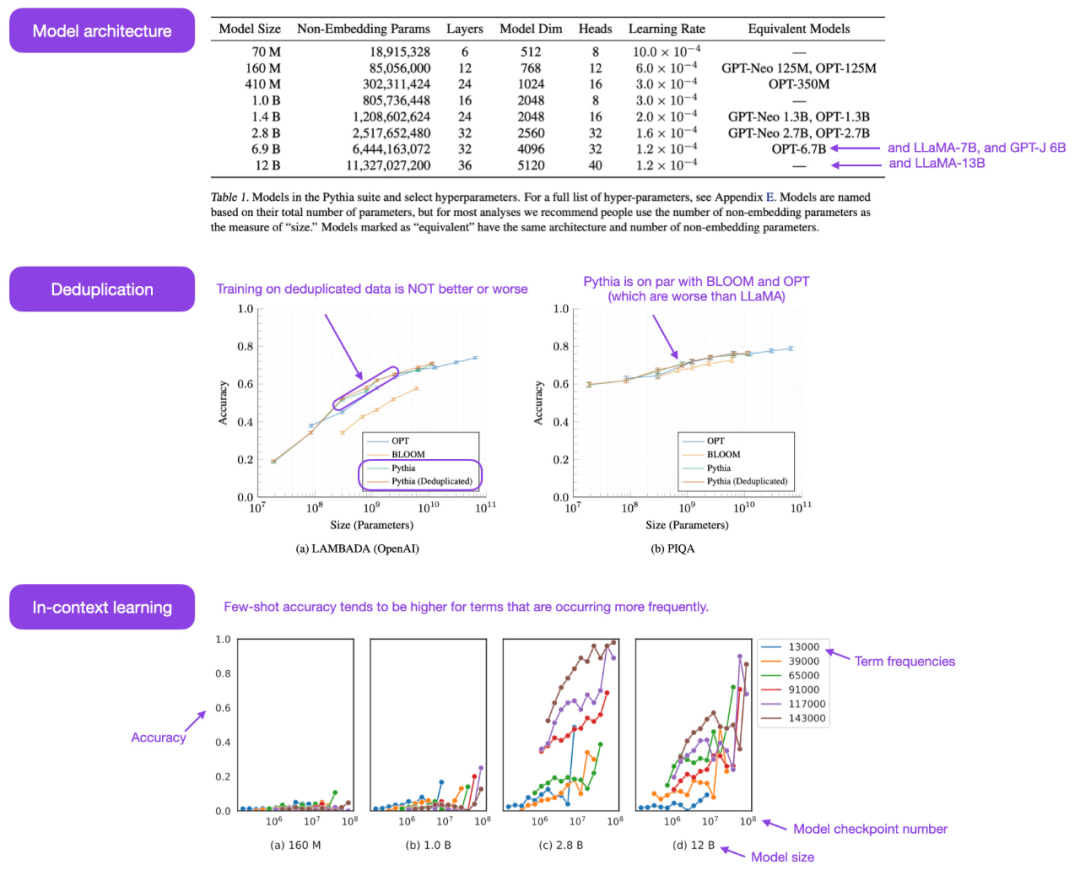
The following are some insights and reflections from the Pythia paper:
Open Source Data
The past month has been particularly exciting for open source AI, with several An open source implementation of LLM and a large set of open source data sets. These datasets include Databricks Dolly 15k, OpenAssistant Conversations (OASST1) for instruction fine-tuning, and RedPajama for pre-training. These dataset efforts are especially laudable because data collection and cleaning accounts for 90% of real-world machine learning projects, yet few people enjoy this work.
Databricks-Dolly-15 dataset
Databricks-Dolly-15 is a data set used for LLM fine-tuning set of over 15,000 instruction pairs written by thousands of DataBricks employees (similar to training systems like InstructGPT and ChatGPT).
OASST1 Dataset
OASST1 dataset is used to fine-tune a pre-trained LLM on a collection of ChatGPT assistant-like conversations created and annotated by humans. , containing 161,443 messages written in 35 languages and 461,292 quality assessments. These are organized in over 10,000 fully annotated dialogue trees.
RedPajama dataset used for pre-training

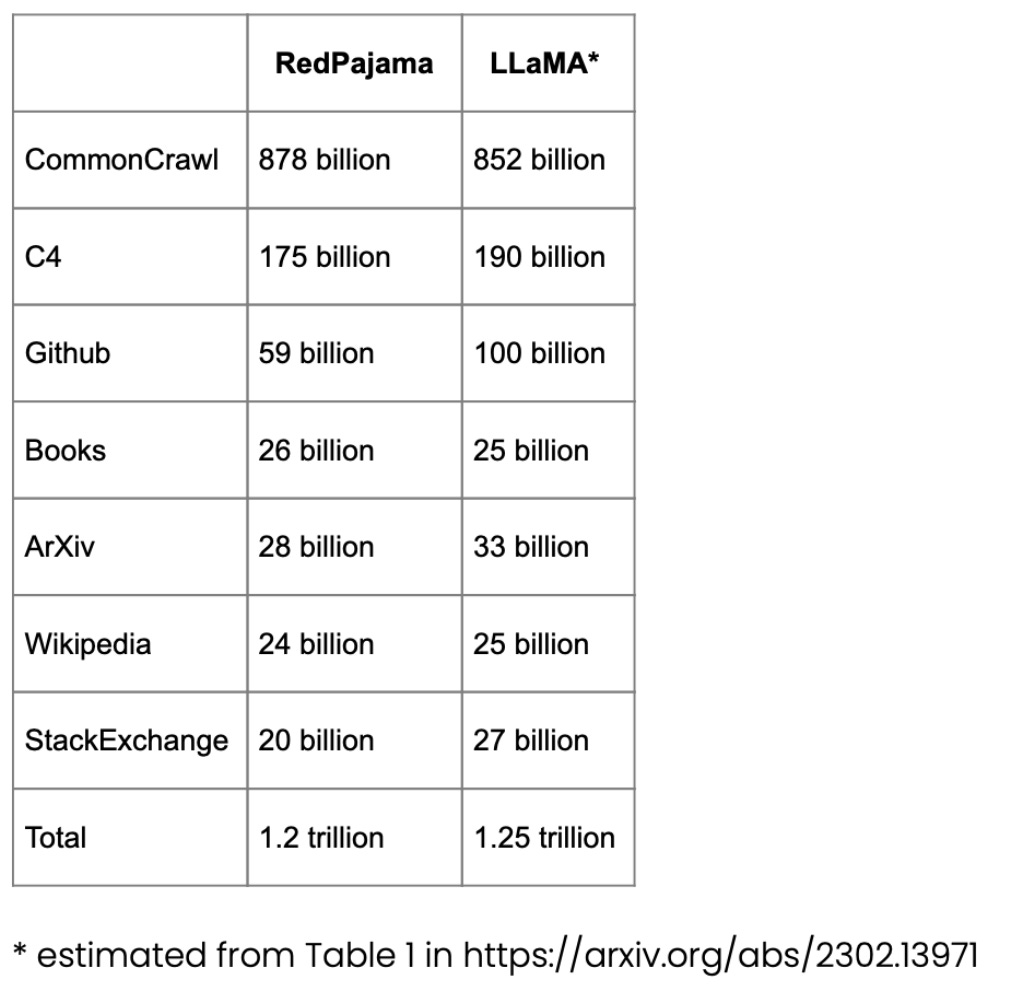
RedPajama is an open source data set for LLM pre-training, similar to Meta's SOTA LLaMA model. This dataset aims to create an open source competitor to most popular LLMs, which are currently either closed source business models or only partially open source.
The bulk of RedPajama consists of CommonCrawl, which filters sites in English, but Wikipedia articles cover 20 different languages.
LongForm Dataset
Paper《 The LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction" introduces a collection of manually created documents based on existing corpora such as C4 and Wikipedia and the instructions of these documents, thereby creating an instruction tuning data set suitable for long text generation.
Paper address: https://arxiv.org/abs/2304.08460
Alpaca Libre project
#The Alpaca Libre project aims to recreate the Alpaca project by converting 100k MIT licensed demos from the Anthropics HH-RLHF repository into an Alpaca compatible format.
Expand the open source data set
Instruction fine-tuning is how we evolve from a GPT-3-like pre-trained basic model to a more The key to a powerful ChatGPT-like large language model. Open source human-generated instruction datasets such as Databricks-Dolly-15 help achieve this. But how do we scale further? Is it possible not to collect additional data? One approach is to bootstrap an LLM from its own iteration. Although the Self-Instruct method was proposed 5 months ago (and is outdated by today's standards), it is still a very interesting method. It is worth emphasizing that it is possible to align pretrained LLMs with instructions thanks to Self-Instruct, a method that requires almost no annotations.
How does it work? In short, it can be divided into the following four steps:
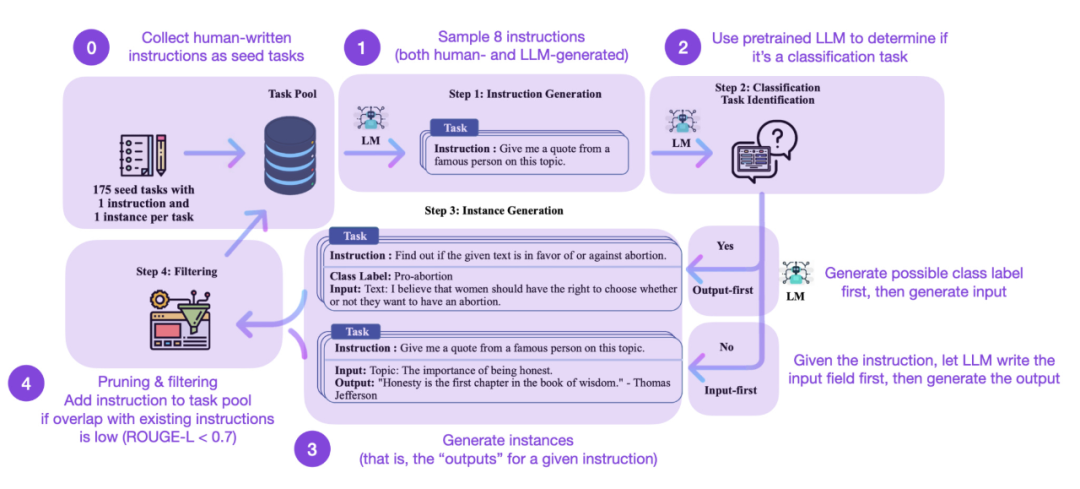
In practice, work based on ROUGE scores will be more effective. For example, Self-Instruct fine-tuned LLM is better than GPT-3 based LLM, and can compete with LLMs pretrained on large human-written instruction sets. At the same time, self-instruct can also benefit from LLM that has been fine-tuned on manual instructions.
But of course, the gold standard for evaluating LLMs is asking human raters. Based on human evaluation, Self-Instruct outperforms basic LLMs, as well as LLMs trained on human instruction datasets in a supervised manner (such as SuperNI, T0 Trainer). Interestingly, however, Self-Instruct does not perform better than methods trained with reinforcement learning with human feedback (RLHF).
Artificially generated vs synthetic training data set
Artificially generated instruction data set or self-instruct data set, which one is more promising? Woolen cloth? Sebastian sees a future in both. Why not start with a manually generated instruction data set (e.g. databricks-dolly-15k of 15k instructions) and then extend it using self-instruct? The paper "Synthetic Data from Diffusion Models Improves ImageNet Classification" shows that combining real image training sets with AI-generated images can improve model performance. It would be interesting to explore whether this is also true for text data.
Paper address: https://arxiv.org/abs/2304.08466
Recent paper "Better Language" Models of Code through Self-Improvement" is research in this direction. The researchers found that code generation tasks can be improved if a pretrained LLM uses its own generated data.
Paper address: https://arxiv.org/abs/2304.01228
Less is more Less is more?
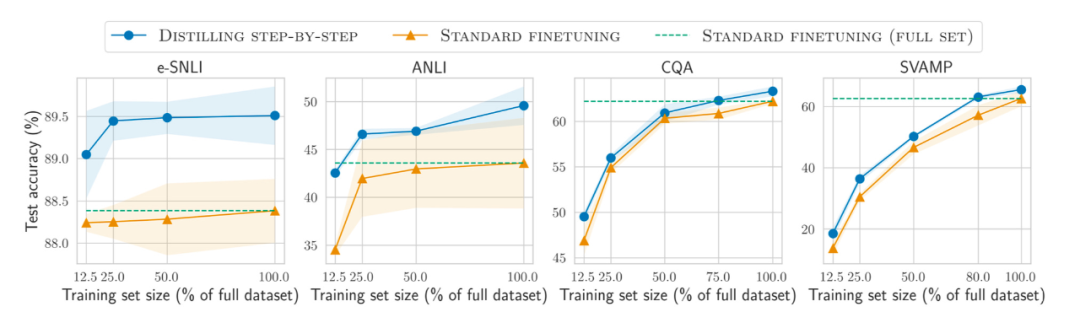
In addition, in addition to pre-training and fine-tuning the model on larger and larger data sets, how can we improve the performance of smaller data sets? What about the efficiency? The paper "Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes" proposes using a distillation mechanism to manage task-specific smaller models that use less training data but exceed standard fine-tuning. performance.
Paper address: https://arxiv.org/abs/2305.02301
Tracking open source LLM
The number of open source LLM is exploding. On the one hand, it is a very good development trend (compared to controlling the model through paid API ), but on the other hand keeping track of it all can be cumbersome. The following four resources provide different summaries of most relevant models, including their relationships, underlying datasets, and various licensing information.
The first resource is the ecosystem graph website based on the paper "Ecosystem Graphs: The Social Footprint of Foundation Models", which provides the following tables and interactive dependency graphs (not shown here).
This ecosystem diagram is the most comprehensive list Sebastian has seen to date, but it can be a bit confusing because it includes many less popular LLMs. Checking the corresponding GitHub repository shows that it has been updated for at least a month. It's also unclear if it will add newer models.
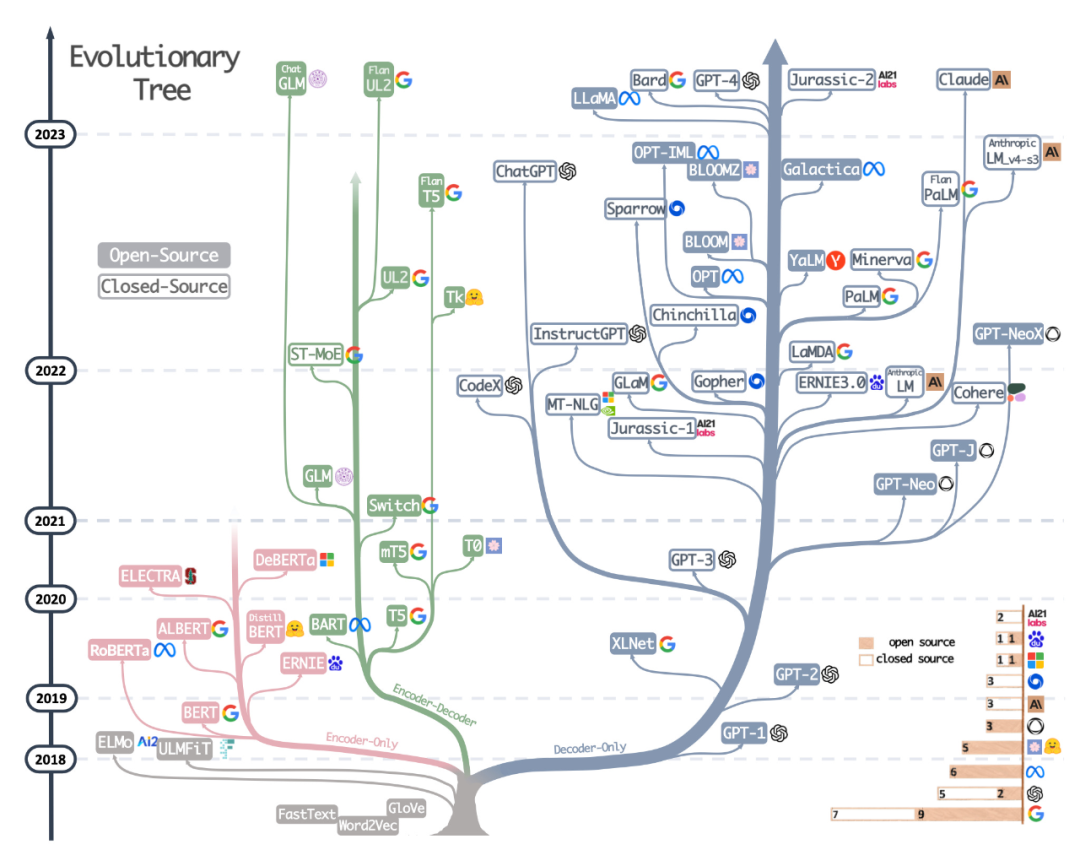
The second resource is the beautifully drawn evolutionary tree from the recent paper Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, which focuses on the most popular LLMs and their Relationship.
Although readers have seen a very beautiful and clear visual LLM evolutionary tree, there are also some minor doubts. It's not clear why the bottom doesn't start from the original transformer architecture. Also open source labels are not very accurate, for example LLaMA is listed as open source, but the weights are not available under an open source license (only the inference code is).
##Paper address: https://arxiv.org/abs/2304.13712 The third resource is a table drawn by Sebastian's colleague Daniela Dapena, from the blog "The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs...". Although the table below is smaller than other resources, it has the advantage of including model dimensions and licensing information. This table will be very useful if you plan to use these models in any project. Blog address: https://lightning.ai/pages/community/community-discussions/the-ultimate-battle-of -language-models-lit-llama-vs-gpt3.5-vs-bloom-vs/ The fourth resource is the LLaMA-Cult-and-More overview table , which provides additional information on fine-tuning methods and hardware costs. 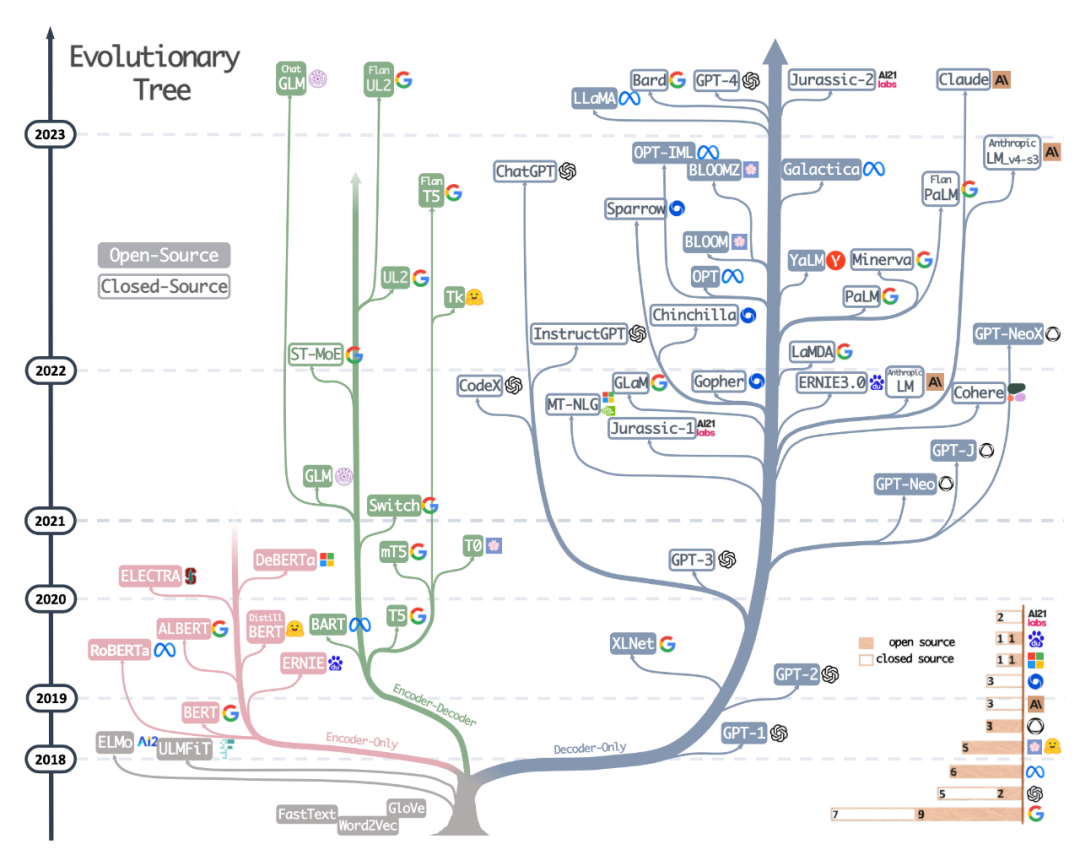
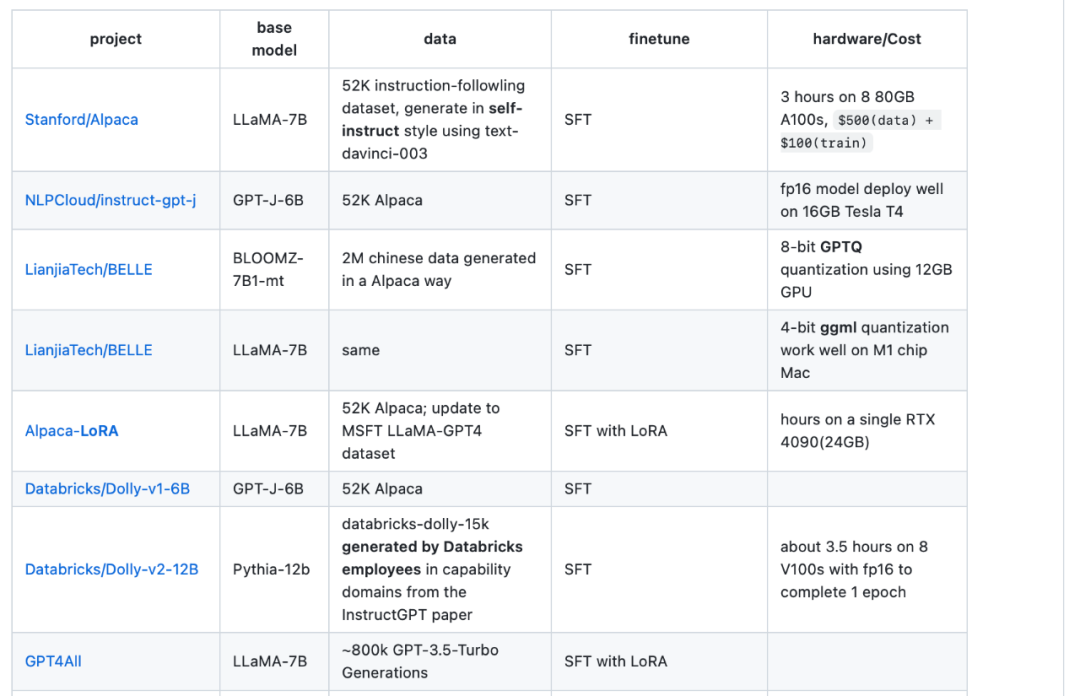
Overview table address: https://github.com/shm007g/LLaMA-Cult-and- More/blob/main/chart.md
Use LLaMA-Adapter V2 to fine-tune multi-modal LLM
Sebastian predicts that we will see more multi-modal LLM models this month, so we have to talk about the recently released paper "LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model". First, let’s review what is LLaMA-Adapter? It is a parameter-efficient LLM fine-tuning technique that modifies the previous transformer blocks and introduces a gating mechanism to stabilize training.
Paper address: https://arxiv.org/abs/2304.15010
Using the LLaMA-Adapter method, The researchers were able to fine-tune a 7B parameter LLaMA model in just 1 hour (8 A100 GPUs) on 52k instruction pairs. Although only the newly added 1.2M parameters (adapter layer) have been fine-tuned, the 7B LLaMA model is still frozen.
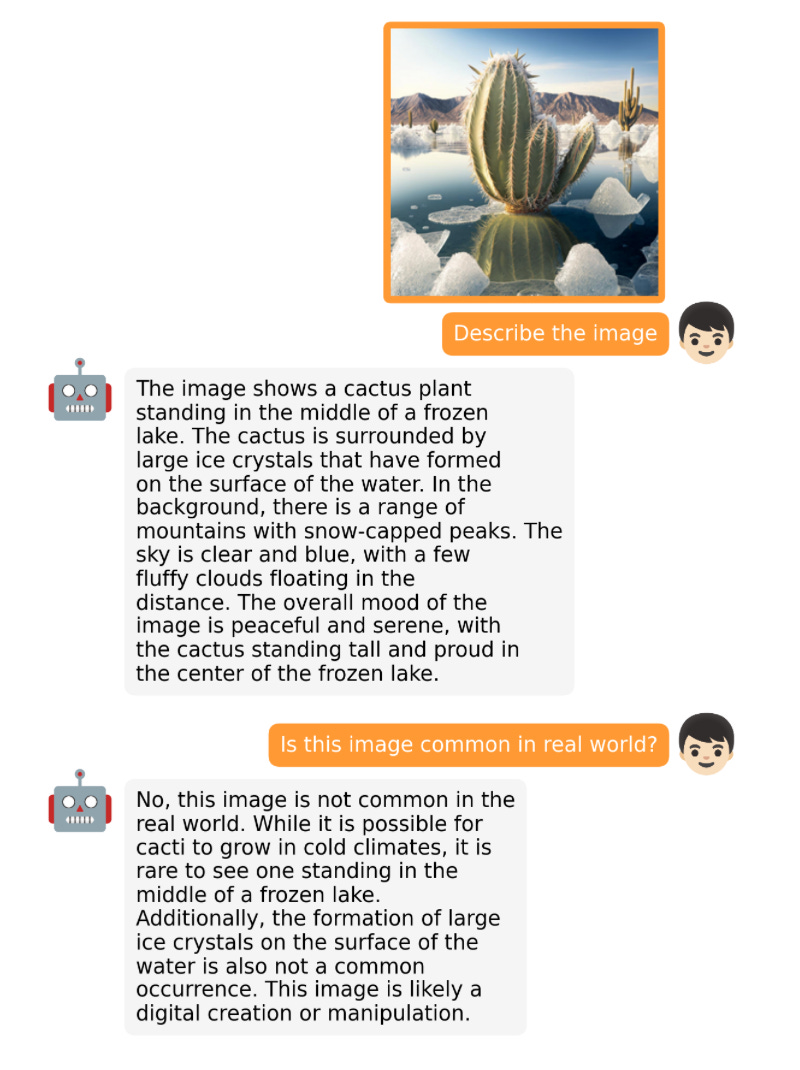
The focus of LLaMA-Adapter V2 is multi-modality, that is, building a visual command model that can receive image input. Although the original V1 could receive text tokens and image tokens, images were not fully explored.
LLaMA-Adapter From V1 to V2, researchers improved the adapter method through the following three main techniques.
LLaMA V2 (14M) has many more parameters than LLaMA V1 (1.2 M), but it is still lightweight, accounting for only 0.02% of the total parameters of 65B LLaMA . Particularly impressive is that by fine-tuning only 14M parameters of the 65B LLaMA model, the resulting LLaMA-Adapter V2 performs on par with ChatGPT (when evaluated using the GPT-4 model). LLaMA-Adapter V2 also outperforms the 13B Vicuna model using the full fine-tuning approach.
Unfortunately, the LLaMA-Adapter V2 paper omits the computational performance benchmark included in the V1 paper, but we can assume that V2 is still much faster than the fully fine-tuned method.

Other open source LLM
The development of large models is so fast that we can’t list them all. Some of the famous open source LLM and chatbots launched this month include Open-Assistant, Baize, StableVicuna, ColossalChat, Mosaic’s MPT, etc. Additionally, below are two particularly interesting multimodal LLMs.
OpenFlamingo
OpenFlamingo is an open source copy of the Flamingo model released by Google DeepMind last year. OpenFlamingo aims to provide multi-modal image inference capabilities for LLM, allowing people to interleave text and image input.
MiniGPT-4
##MiniGPT-4 is another open source model with visual language capabilities. It is based on the BLIP-27 frozen visual encoder and the frozen Vicuna LLM.
NeMo Guardrails
With these With the emergence of large language models, many companies are thinking about how and whether they should deploy them, and security concerns are particularly prominent. There are no good solutions yet, but there is at least one more promising approach: NVIDIA has open sourced a toolkit to solve the LLM hallucination problem.
In a nutshell, how it works is that this method uses database links to hard-coded prompts that must be managed manually. Then, if the user enters prompt, that content will be matched first to the most similar entry in that database. The database then returns a hardcoded prompt which is then passed to LLM. So if one carefully tests the hardcoded prompt, one can ensure that the interaction does not deviate from allowed topics etc.
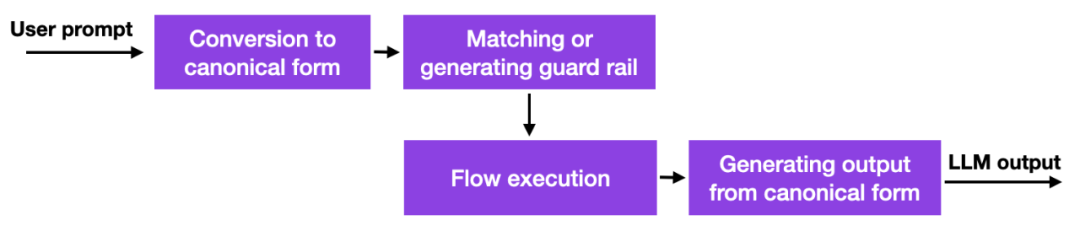
The guardrails approach can also be combined with other alignment techniques, such as the popular human-feedback reinforcement learning training paradigm that the authors introduced in a previous issue of Ahead of AI.
Consistency Model
Talking about interesting models other than LLM is a good attempt, and OpenAI finally open sourced them Code for the consistency model: https://github.com/openai/consistency_models.The consistency model is considered a feasible and effective alternative to the diffusion model. You can get more information in the consistency model paper.
The above is the detailed content of Large models are ushering in the 'open source season', taking stock of the open source LLM and data sets in the past month. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



