


"Wen Xinyiyan completed training on the largest high-performance GPU cluster in the country's AI field."
As early as 2021 In June 2019, in order to meet future large model training tasks, Baidu Intelligent Cloud began to plan the construction of a new high-performance GPU cluster, and jointly completed the design of an IB network architecture that can accommodate more than 10,000 cards in conjunction with NVIDIA. Each node between the nodes in the cluster Each GPU card is connected through the IB network, and the cluster construction will be completed in April 2022, providing single cluster EFLOPS level computing power.
In March 2023, Wen Xinyiyan was born on this high-performance cluster and continues to iterate new capabilities. Currently, the size of this cluster is still expanding.
Dr. Junjie Lai, General Manager of Solutions and Engineering at NVIDIA China: GPU clusters interconnected by high-speed IB networks are key infrastructure in the era of large models. NVIDIA and Baidu Intelligent Cloud jointly built the largest high-performance GPU/IB cluster in the domestic cloud computing market, which will accelerate Baidu's greater breakthrough in the field of large models.
High-performance cluster is not a simple accumulation of computing power. It also requires special design and optimization to bring out the full potential of the cluster. computing power.
In distributed training, GPUs will continuously communicate between and within machines. While using high-performance networks such as IB and RoCE to provide high-throughput and low-latency services for inter-machine communication, it is also necessary to specially design the internal network connections of the servers and the communication topology in the cluster network to meet the communication requirements of large model training. requirements.
Achieving the ultimate design optimization requires a deep understanding of what each operation in the AI task means to the infrastructure. Different parallel strategies in distributed training, that is, how to split models, data, and parameters, will produce different data communication requirements. For example, data parallelism and model parallelism will introduce a large number of intra-machine and inter-machine Allreduce operations respectively, and expert parallelism will Producing inter-machine All2All operations, 4D hybrid parallelism will introduce communication operations generated by various parallel strategies.
To this end, Baidu Smart Cloud optimizes the design from both stand-alone servers and cluster networks to build high-performance GPU clusters.
In terms of stand-alone servers, Baidu Smart Cloud’s super AI computer X-MAN has now evolved to its fourth generation. X-MAN 4.0 establishes high-performance inter-card communication for GPUs, providing 134 GB/s of Allreduce bandwidth within a single machine. This is currently Baidu’s server product with the highest degree of customization and the most specialized materials. In the MLCommons 1.1 list, X-MAN 4.0 ranks TOP2 in stand-alone hardware performance with the same configuration.
In terms of cluster network, a three-layer Clos architecture optimized for large model training is specially designed to ensure the performance and acceleration of the cluster during large-scale training. Compared with the traditional method, this architecture has been optimized with eight rails to minimize the number of hops in the communication between any card with the same number in different machines, and provides support for the Allreduce operation of the same card with the largest share of network traffic in AI training. High throughput and low latency network services.
This network architecture can support ultra-large-scale clusters with a maximum of 16,000 cards. This scale is the largest scale of all IB network box networking at this stage. The cluster's network performance is stable and consistent at a level of 98%, which is close to a state of stable communication. Verified by the large model algorithm team, hundreds of billions of model training jobs were submitted on this ultra-large-scale cluster, and the overall training efficiency at the same machine size was 3.87 times that of the previous generation cluster.
However, building large-scale, high-performance heterogeneous clusters is only the first step to successfully implement large models. To ensure the successful completion of AI large model training tasks, more systematic optimization of software and hardware is required.
In the past few years, the parameter size of large models will increase at a rate of 10 times per year. Around 2020, a model with hundreds of billions of parameters will be considered a large model. By 2022, it will already require hundreds of billions of parameters to be called a large model.
Before large models, the training of an AI model was usually sufficient for a single machine with a single card or a single machine with multiple cards. The training cycle ranged from hours to days. Now, in order to complete the training of large models with hundreds of billions of parameters, large cluster distributed training with hundreds of servers and thousands of GPU/XPU cards has become a must, and the training cycle has also been extended to months.
In order to train GPT-3 with 175 billion parameters (300 billion token data), 1 block of A100 takes 32 years based on half-precision peak performance calculation, and 1024 blocks of A100 takes 34 days based on resource utilization of 45%. . Of course, even if time is not taken into account, one A100 cannot train a model with a parameter scale of 100 billion, because the model parameters have exceeded the memory capacity of a single card.
To conduct large model training in a distributed training environment, the training cycle is shortened from decades to dozens of days for a single card. It is necessary to break through various challenges such as computing walls, video memory walls, and communication walls, so that all resources in the cluster can can be fully utilized to speed up the training process and shorten the training cycle.
The computing wall refers to the huge difference between the computing power of a single card and the total computing power of the model. The single card computing power of A100 is only 312 TFLOPS, while GPT-3 requires a total computing power of 314 ZFLOPs. There is a difference of 9 orders of magnitude.
Video memory wall refers to the inability of a single card to completely store the parameters of a large model. GPT-3's 175 billion parameters alone require 700 GB of video memory (each parameter is calculated as 4 bytes), while the NVIDIA A100 GPU only has 80 GB of video memory.
The essence of the computing wall and the video memory wall is the contradiction between the limited single card capability and the huge storage and computing requirements of the model. This can be solved through distributed training, but after distributed training, you will encounter the problem of communication wall.
Communication wall, mainly because each computing unit of the cluster needs frequent parameter synchronization under distributed training, and communication performance will affect the overall computing speed. If the communication wall is not handled well, it is likely that the cluster will become larger and the training efficiency will decrease. Successfully breaking through the communication wall is reflected in the strong scalability of the cluster, that is, the multi-card acceleration capability of the cluster matches the scale. The linear acceleration ratio of multiple cards is an indicator for evaluating the acceleration capabilities of multiple cards in a cluster. The higher the value, the better.
These walls begin to appear during multi-machine and multi-card training. As the parameters of the large model become larger and larger, the corresponding cluster size also becomes larger and larger, and these three walls become higher and higher. At the same time, during long-term training of large clusters, equipment failures may occur, which may affect or interrupt the training process.
Generally speaking, from the perspective of infrastructure, the entire process of large model training can be roughly divided into the following two stages:
After submitting the large model to be trained, the AI framework will comprehensively consider the structure of the large model and other information, as well as the capabilities of the training cluster, to formulate a parallel training strategy for this training task. , and complete AI task placement. This process is to disassemble the model and place the task, that is, how to disassemble the large model and how to place the disassembled parts into each GPU/XPU of the cluster.
For AI tasks placed to run in GPU/XPU, the AI framework will jointly train the cluster to perform full-link optimization at the single-card runtime and cluster communication levels to accelerate the operation of each AI task during the large model training process. Efficiency, including data loading, operator calculation, communication strategy, etc. For example, ordinary operators running in AI tasks are replaced with optimized high-performance operators, and communication strategies that adapt to the current parallel strategy and training cluster network capabilities are provided.
The large model training task starts running according to the parallel strategy formulated above, and the training cluster provides various high-performance resources for the AI task. For example, in what environment does the AI task run, how to provide resource docking for the AI task, what storage method does the AI task use to read and save data, what type of network facilities does the GPU/XPU communicate through, etc.
At the same time, during the operation process, the training cluster will combine with the AI framework to provide a reliable environment for long-term training of large models through elastic fault tolerance and other methods. For example, how to observe and perceive the running status of various resources and AI tasks in the cluster, etc., and how to schedule resources and AI tasks when the cluster changes, etc.
From the dismantling of the above two stages, we can find that the entire large model training process relies on the close cooperation of the AI framework and the training cluster to complete the breakthrough of the three walls and jointly ensure large model training Efficient and stable.
Combined with years of technology accumulation and engineering practice in the fields of AI and large models, Baidu launched the full-stack at the end of 2022 The self-developed AI infrastructure "AI Big Base" includes a three-layer technology stack of "chip-framework-model". It has key self-developed technologies and leading products at all levels, corresponding to Kunlun Core, PaddlePaddle, and WeChat. Big model of the heart.
Based on these three layers of technology stack, Baidu Intelligent Cloud has launched two major AI engineering platforms, "AI Middle Platform" and "Baidu Baige·AI Heterogeneous Computing Platform", which are respectively in development and resources. Improve efficiency at all levels, break through the three walls, and accelerate the training process.
Among them, "AI middle platform" relies on the AI framework to develop parallel strategies and optimized environments for the large model training process, covering the entire life cycle of training. "Baidu Baige" realizes efficient chip enablement and provides management of various AI resources and task scheduling capabilities.
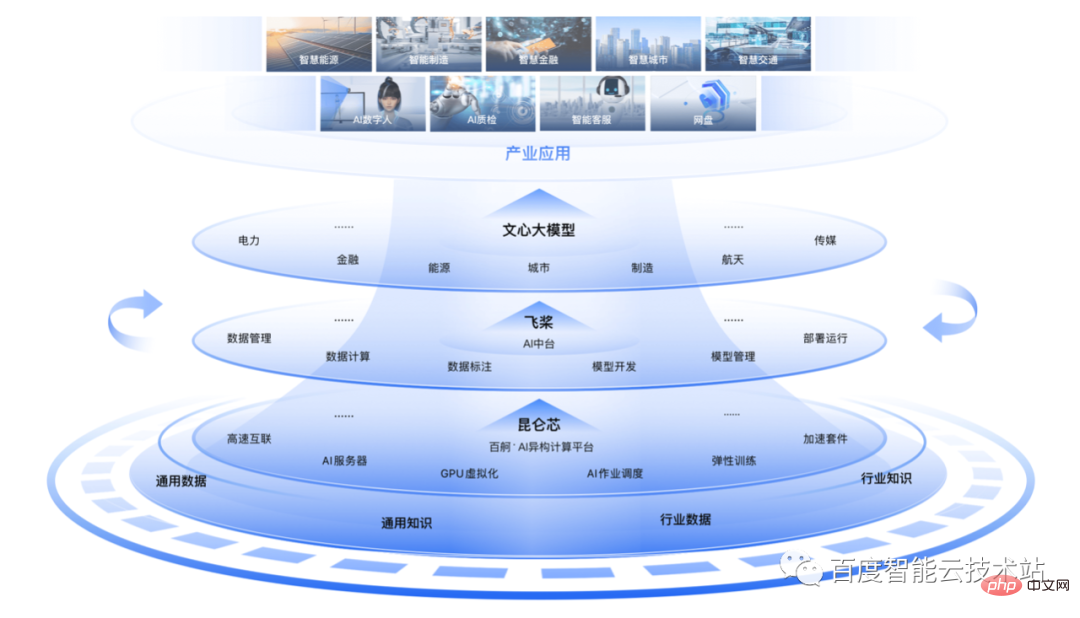
Baidu's "AI Big Base" has carried out full-stack integration and system optimization of each layer of the technology stack, completing the technology integration construction of cloud and intelligence. End-to-end optimization and acceleration of large model training can be achieved.
Hou Zhenyu, Vice President of Baidu Group: Large model training is a systematic project. The cluster size, training time, and cost have all increased a lot compared to the past. Without full-stack optimization, it would be difficult to ensure the successful completion of large model training. Baidu's technical investment and engineering practices in large models over the years have enabled us to establish a complete set of software stack capabilities to accelerate the training of large models.
Next, we will combine the two stages of the large model training process mentioned above to describe how the various layers of the technology stack of the "AI Big Base" are integrated with each other. System optimization to achieve end-to-end optimization and acceleration of large model training.
Flying Paddle can provide data parallelism, model parallelism, pipeline parallelism, parameter grouping and slicing, and expert parallelism for large model training and other rich parallel strategies. These parallel strategies can meet the needs of training large models with parameters ranging from billions to hundreds of billions, or even trillions, and achieve breakthroughs in computing and video memory walls. In April 2021, Feipiao was the first in the industry to propose a 4D hybrid parallel strategy, which can support the training of hundreds of billions of large models to be completed at the monthly level.
Baidu Baige has cluster topology awareness capabilities specially prepared for large model training scenarios, including intra-node architecture awareness, inter-node architecture awareness, etc., such as the computing power inside each server. Information such as power, CPU and GPU/XPU, GPU/XPU and GPU/XPU link methods, and GPU/XPU and GPU/XPU network link methods between servers.
Before the large model training task starts running, Feipiao can form a unified distributed resource graph for the cluster based on the topology awareness capabilities of Baidu Baige platform. At the same time, the flying paddle forms a unified logical calculation view based on the large model to be trained.
Based on these two pictures, Feipiao automatically searches for the optimal model segmentation and hardware combination strategy for the model, and allocates model parameters, gradients, and optimizer status to different GPUs/GPUs according to the optimal strategy. On XPU, complete the placement of AI tasks to improve training performance.
For example, model parallel AI tasks are placed on different GPUs on the same server, and these GPUs are linked through the NVSwitch inside the server. Place data-parallel and pipeline-parallel AI tasks on GPUs of the same number on different servers, and these GPUs are linked through IB or RoCE. Through this method of placing AI tasks according to the type of AI tasks, cluster resources can be used efficiently and the training of large models can be accelerated.
During the running of the training task, if the cluster changes, such as a resource failure, or the cluster scale changes, Baidu Baige will perform fault tolerance replacement or elastic expansion and contraction. Since the locations of the nodes participating in the calculation have changed, the communication mode between them may no longer be optimal. Flying Paddle can automatically adjust model segmentation and AI task placement strategies based on the latest cluster information. At the same time, Baidu Baige completes the scheduling of corresponding tasks and resources.
Feipiao’s unified resource and computing view and automatic parallel capabilities, combined with Baidu Baige’s elastic scheduling capabilities, realize end-to-end adaptive distributed training of large models, covering the entire life of cluster training cycle.
This is an in-depth interaction between the AI framework and the AI heterogeneous computing power platform. It realizes the system optimization of the trinity of computing power, framework and algorithm, supports automatic and flexible training of large models, and has an end-to-end measured performance of 2.1 times. The performance improvement ensures the efficiency of large-scale training.
After completing the splitting of the model and the placement of AI tasks, during the training process, in order to ensure that the operator operates in various mainstream AI frameworks such as Flying Paddle and Pytorch and various computing cards It can accelerate calculations, and Baidu Baige platform has a built-in AI acceleration suite. The AI acceleration suite includes data layer storage acceleration, training and inference acceleration library AIAK, which optimizes the entire link from the dimensions of data loading, model calculation, distributed communication and other dimensions.
Among them, the optimization of data loading and model calculation can effectively improve the operating efficiency of a single card; the optimization of distributed communication, combined with high-performance networks such as cluster IB or RoCE and specially optimized communication topology, as well as reasonable AI task placement Strategies to jointly solve the communication wall problem.
Baidu Baige’s multi-card acceleration ratio in a kilo-card scale cluster has reached 90%, allowing the overall computing power of the cluster to be fully released.
In the test results of MLPerf Training v2.1 released in November 2022, the model training performance results submitted by Baidu using Fei Paddle plus Baidu Baige ranked first in the world under the same GPU configuration, end-to-end Both training time and training throughput exceed the NGC PyTorch framework.
Baidu Baige can provide various computing, network, storage and other AI resources, including Baidu Taihang elastic bare metal server BBC, IB network, RoCE network, and parallel file storage PFS , object storage BOS, data lake storage acceleration RapidFS and other various cloud computing resources suitable for large model training.
When a task is running, these high-performance resources can be reasonably combined to further improve the efficiency of AI operations and realize computing acceleration of AI tasks throughout the process. Before the AI task starts, the training data in the object storage BOS can be warmed up, and the data can be loaded into the data lake storage acceleration RapidFS through the elastic RDMA network. The elastic RDMA network can reduce communication latency by 2 to 3 times compared to traditional networks, and accelerates the reading of AI task data based on high-performance storage. Finally, AI task calculations are performed through the high-performance Baidu Taihang elastic bare metal server BBC or cloud server BCC.
When running an AI task, it not only requires high-performance resources, but also needs to ensure the stability of the cluster and minimize the occurrence of resource failures to avoid interrupting training. However, resource failure cannot be absolutely avoided. The AI framework and the training cluster need to jointly ensure that the training task can be recovered from the most recent state after being interrupted, thereby providing a reliable environment for long-term training of large models.
Baidu's self-developed heterogeneous collection library ECCL supports communication between Kunlun cores and other heterogeneous chips, and supports the perception of slow nodes and faulty nodes. Through Baidu Baige's resource elasticity and fault-tolerance strategy, slow nodes and faulty nodes are eliminated, and the latest architecture topology is fed back to Feipiao to re-arrange tasks and allocate corresponding training tasks to other XPU/GPUs to ensure smooth training. Run efficiently.
Large models are a milestone technology for artificial intelligence to move towards general intelligence. Mastering large models well is a must-answer on the path to complete intelligent upgrades. Ultra-large-scale computing power and full-stack integrated software optimization are the best answers to this must-answer question.
In order to help society and industry quickly train their own large models and seize the opportunity of the times, Baidu Intelligent Cloud released the Yangquan Intelligent Computing Center at the end of 2022, equipped with the full-stack capabilities of Baidu's "AI Big Base", which can provide 4 EFLOPS of heterogeneous computing power. This is currently the largest and most technologically advanced data center in Asia.
Currently, Baidu Smart Cloud has opened all the capabilities of the "AI Big Base" to the outside world, realizing inclusive AI in the big model era, through central clouds in various regions, edge clouds BEC, local computing clusters LCC, private It is delivered in various forms such as Cloud ABC Stack, making it easy for society and industry to obtain intelligent services.
The above is the detailed content of AI large base, the answer to the era of large models. For more information, please follow other related articles on the PHP Chinese website!
 Advantages of plc control system
Advantages of plc control system
 delete folder in linux
delete folder in linux
 Introduction to article tag attributes
Introduction to article tag attributes
 How to type the inscription on the coin circle?
How to type the inscription on the coin circle?
 What does MLM coin mean? How long does it usually take to crash?
What does MLM coin mean? How long does it usually take to crash?
 Common usage of Array.slice
Common usage of Array.slice
 Top ten digital currency exchanges
Top ten digital currency exchanges
 Windows 10 activation key list
Windows 10 activation key list








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



