


There is such a core training method in ChatGPT called "Human Feedback Reinforcement Learning (RLHF)".
It can make the model safer and the output results more consistent with human intentions.
Now, researchers from Google Research and UC Berkeley have found that using this method in AI painting can "treat" the situation where the image does not completely match the input, and the effect is also surprisingly good——
Up to 47% improvement can be achieved.

At this moment, the two popular models in the AIGC field seem to have found some kind of " resonance".
RLHF, the full name is "Reinforcement Learning from Human Feedback", is a reinforcement learning technology jointly developed by OpenAI and DeepMind in 2017.
As its name suggests, RLHF uses human evaluation of model output results (i.e. feedback) to directly optimize the model. In LLM, it can make "model values" more consistent with human values.
In the AI image generation model, it can fully align the generated image with the text prompt.
Specifically, first, collect human feedback data.
Here, the researchers generated a total of more than 27,000 "text-image pairs" and then asked some humans to score them.
For the sake of simplicity, text prompts only include the following four categories, related to quantity, color, background and blending options; human feedback is only divided into "good", "bad" and "don't know (skip)" ".

Secondly, learn the reward function.
This step is to use the data set composed of human evaluations just obtained to train a reward function, and then use this function to predict human satisfaction with the model output (red part of the formula).
In this way, the model knows how much its results match the text.
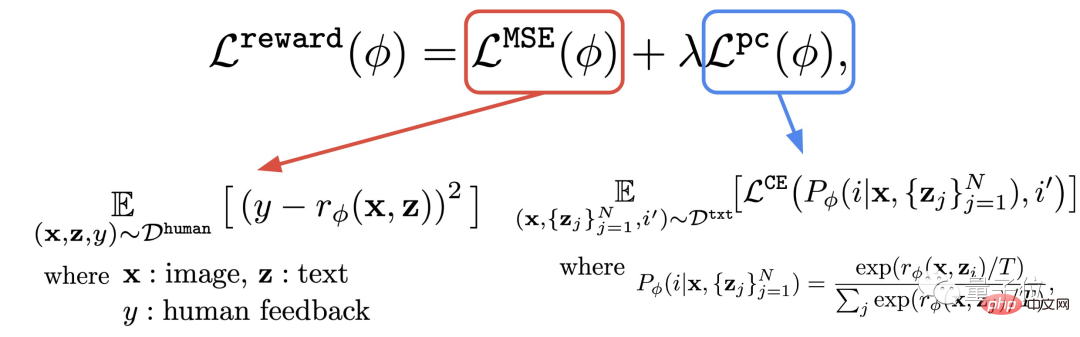
#In addition to the reward function, the author also proposes an auxiliary task (blue part of the formula).
That is, after the image generation is completed, the model will give a bunch of text, but only one of them is the original text, and let the reward model "check by itself" whether the image matches the text.
This reverse operation can make the effect "double insurance" (it can assist step 2 in the figure below to understand).
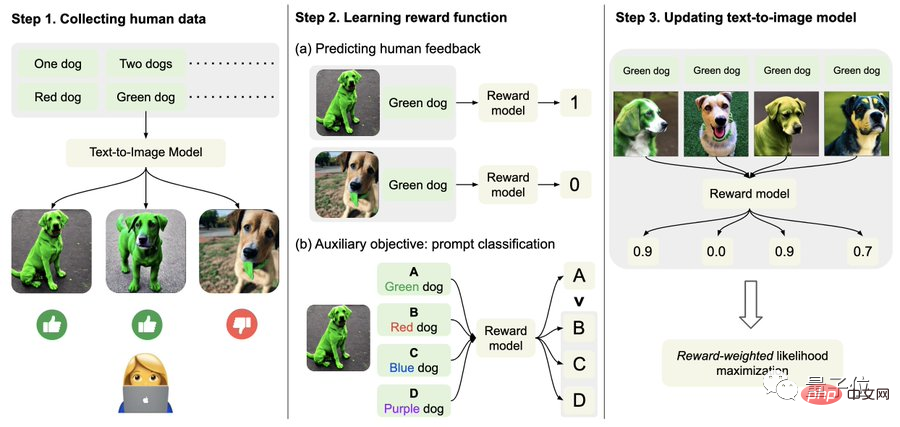
Finally, it’s fine-tuning.
That is, the text-image generation model is updated through reward-weighted likelihood maximization (the first item of the formula below).
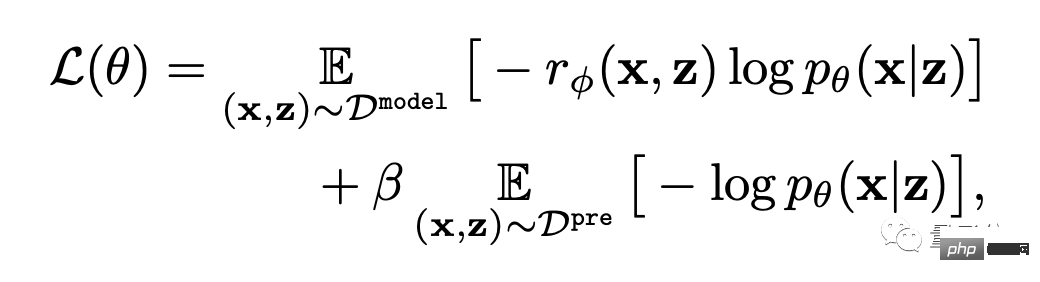
#In order to avoid overfitting, the author minimized the NLL value (the second term of the formula) on the pre-training data set. This approach is similar to InstructionGPT (the "direct predecessor" of ChatGPT).
As shown in the following series of effects, compared with the original Stable Diffusion, the model fine-tuned with RLHF can:
(1) Get "two" and "green" in the text more correctly;

(2) Will not ignore "sea" As a background requirement;
(3) If you want a red tiger, it can give a "redder" result.
Judging from the specific data, the human satisfaction level of the fine-tuned model is 50%, which is a 47% improvement compared to the original model (3%).
However, the price is a loss of 5% image clarity.
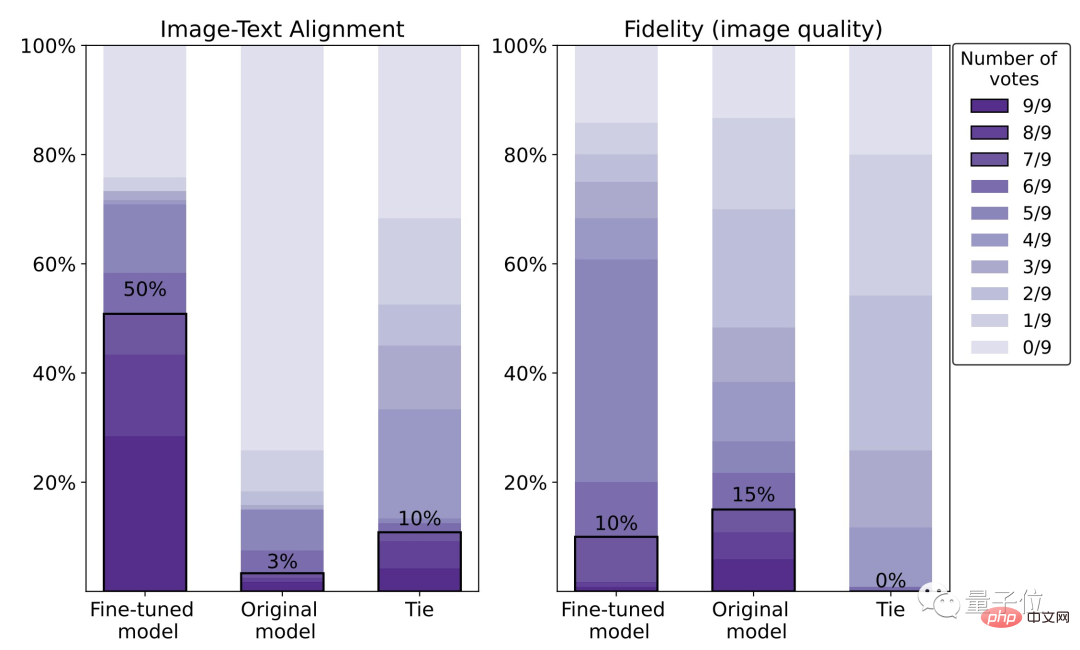
We can also clearly see from the picture below that the wolf on the right is obviously blurrier than the one on the left:
Yes Therefore, the authors suggest that the situation could be improved using larger human evaluation datasets and better optimization (RL) methods.
There are 9 authors in total for this article.

As a Google AI research scientist Kimin Lee, Ph.D. from Korea Institute of Science and Technology, postdoctoral research was carried out at UC Berkeley.

Three Chinese authors:
Liu Hao, a doctoral student at UC Berkeley, whose main research interest is feedback neural networks.
Du Yuqing is a PhD candidate at UC Berkeley. His main research direction is unsupervised reinforcement learning methods.
Shixiang Shane Gu (Gu Shixiang), the corresponding author, studied under Hinton, one of the three giants, for his undergraduate degree, and graduated from Cambridge University with his doctorate.

It is worth mentioning that when writing this article, he was still a Googler, and now he has switched to OpenAI, where he directly reports to Report from the person in charge of ChatGPT.
Paper address:
https://arxiv.org/abs/2302.12192
Reference link: [1]https://www.php .cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2]https://openai.com/blog/instruction-following/
The above is the detailed content of The core method of ChatGPT can be used for AI painting, and the effect soars by 47%. Corresponding author: has switched to OpenAI. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



