



Musk acquired Twitter, but was dissatisfied with its technology. Think the homepage is too slow because there are over 1000 RPCs. Without commenting on whether the reason Musk said is correct, it can be seen that a complete service provided to users on the Internet will have a large number of microservice calls behind it.
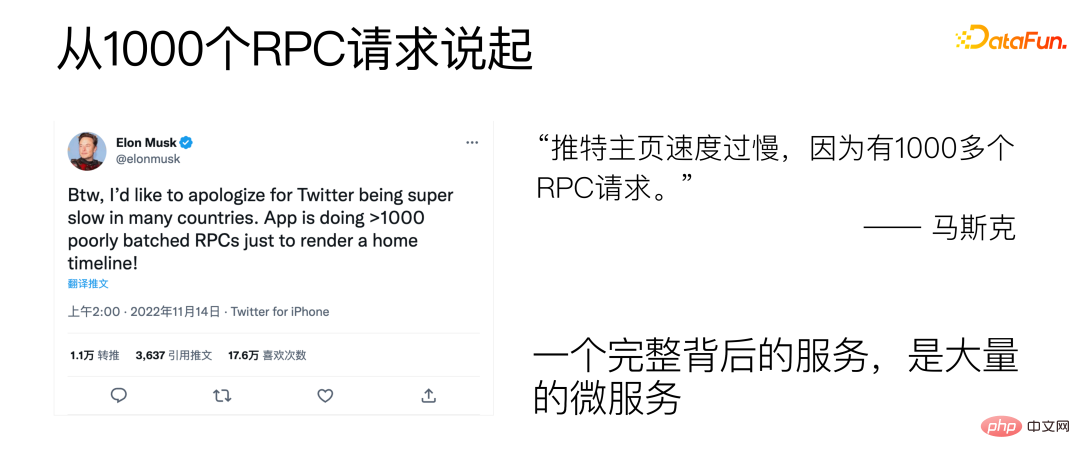
Taking WeChat reading recommendation as an example, it is divided into two stages: recall and sorting.
##After the request arrives, the characteristics will be pulled from the user characteristics microservice and the characteristics will be Combine them together to perform feature screening, and then call the recall-related microservices. This process also needs to be multiplied by an N because we have a multi-channel recall and there will be many similar recall processes running at the same time. The following is the sorting stage, which pulls relevant features from multiple feature microservices and calls the sorting model service multiple times after combining them. After obtaining the final result, on the one hand, the final result is returned to the caller, and on the other hand, some logs of the process are sent to the log system for archiving.
Reading recommendations are only a very small part of the entire WeChat Reading APP. It can be seen that even a relatively small service will have a large number of microservices behind it. transfer. If you take a closer look, you can expect that the entire WeChat Reading system will have a huge number of microservice calls.
#What problems does a large number of microservices bring?
According to the summary of daily work, there are mainly challenges in the above three aspects:
① Management: Mainly focuses on how to efficiently manage, develop and deploy a large number of algorithm microservices.
② Performance: Try to improve the performance of microservices, especially algorithm microservices.
③ Scheduling: How to achieve efficient and reasonable load balancing among multiple similar algorithm microservices .
The first point is that weprovide some automatic packaging and deployment pipelines to reduce the pressure on algorithm students to develop algorithm microservices. Now algorithm students You only need to write a Python function, and the pipeline will automatically pull a series of pre-written microservice templates and fill in the functions developed by algorithm students to quickly build microservices.
The second point is about microservices For automatic expansion and contraction, we adopt a task backlog-aware solution. We will actively detect the degree of backlog or idleness of a certain type of tasks. When the backlog exceeds a certain threshold, the expansion operation will be automatically triggered. When the idleness reaches a certain threshold, we will also trigger the reduction of the number of microservice processes.
The third point ishow to put a large number of Microservices are organized together to construct a complete upper-layer service. Our upper-layer services are represented by DAG. Each node of the DAG represents a call to the microservice, and each edge represents the transfer of data between services. For DAG, a DSL (domain specific language) has also been specially developed to better describe and structure DAG. And we have developed a series of web-based tools around DSL, which can visually build, stress test and deploy upper-layer services directly in the browser.
##The fourth pointPerformance monitoring, when When there is a problem with the upper-layer service, we need to locate the problem. We built our own Trace system. For each external request, there is a complete set of tracking, which can check the time consumption of the request in each microservice, thereby discovering the performance bottleneck of the system.
Generally speaking, the performance time of the algorithm is Regarding deep learning models, a large part of the focus of optimizing the performance of algorithm microservices is optimizing the infer performance of deep learning models. You can choose a dedicated infer framework, or try deep learning compilers, Kernel optimization, etc. For these solutions, we believe that they are not completely necessary. In many cases, we directly use Python scripts to go online, and we can still achieve performance comparable to C.
#The reason why it is not completely necessary is that these solutions can indeed bring better performance, but good performance is not the only requirement of the service. There is a well-known 80/20 rule, described in terms of people and resources, that is, 20% of people will generate 80% of the resources. In other words, 20% of the people will provide 80% of the contributions. This is also applicable to microservices.
We can divide microservices into two categories. First, mature and stable services are not large in number and may only occupy 20%, but bear 80% of the traffic. The other category is some experimental services or services that are still under development and iteration. They are large in number, accounting for 80%, but only account for 20% of the traffic. The important point is that there are often changes and iterations, so There will also be a strong demand for rapid development and launch. The methods mentioned earlier, such as the Infer framework, Kernel optimization, etc., inevitably require additional development costs. Mature and stable services are still very suitable for this type of method, because there are relatively few changes and they can be used for a long time after one optimization. On the other hand, these services bear a large amount of traffic, and a small performance improvement may have a huge impact, so it is worth investing in the cost.But these methods are not so suitable for experimental services, because experimental services will be updated frequently, and we cannot make new optimizations for every new model. For experimental services, we developed a self-developed Python interpreter - PyInter for GPU hybrid deployment scenarios. It is possible to go online directly using Python scripts without modifying any code, and at the same time, the performance can be close to or even exceed that of C.
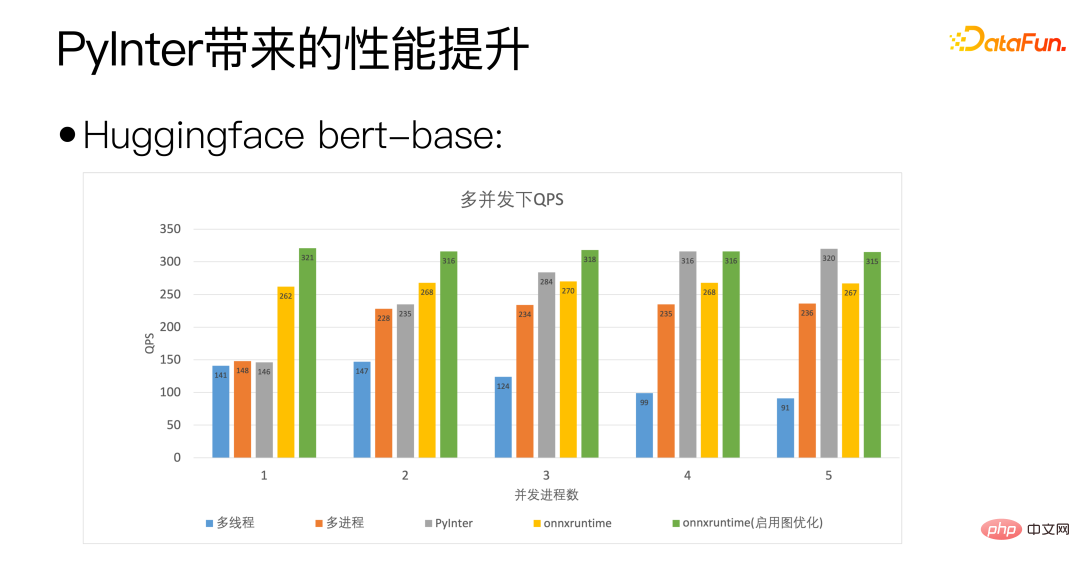
We use Huggingface’s bert-base as the standard. The horizontal axis of the above figure is concurrency. The number of processes represents the number of model copies we deploy. It can be seen that our PyInter's QPS even surpasses onnxruntime when the number of model copies is large.
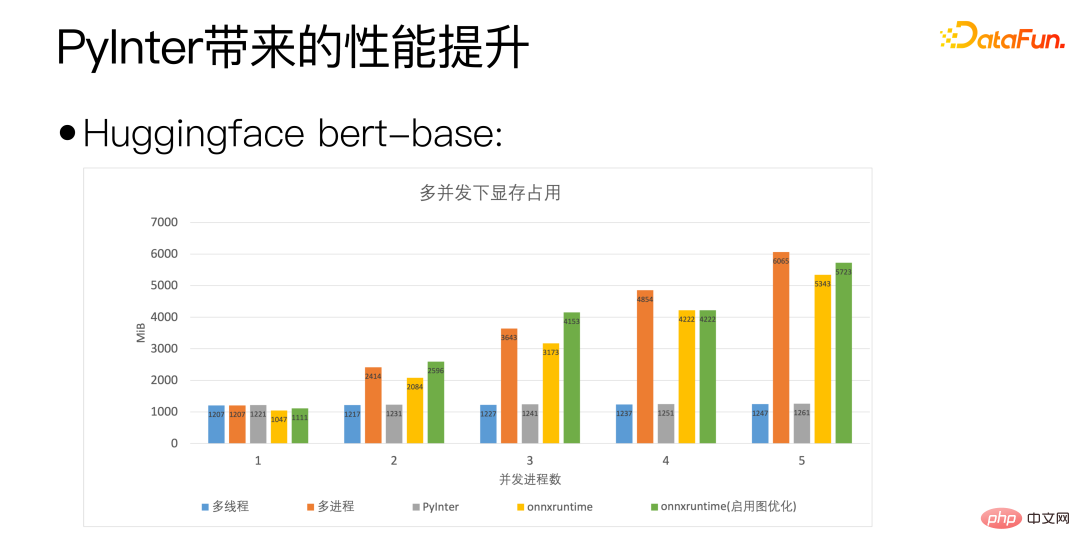
Through the above figure, you can see that PyInter has a large number of model copies. Compared with multi-process and ONNXRuntime, the video memory usage is reduced by almost 80%, and please note that regardless of the number of copies of the model, PyInter's video memory usage remains unchanged.
# Let’s go back to the more basic question before: Is Python really slow?
Yes, Python is really slow, but Python is not slow when doing scientific calculations, because the actual calculation is not done in Python, but by calling MKL or cuBLAS, a dedicated calculation library.
#So where is the main performance bottleneck of Python? Mainly due to the GIL (Global Interpreter Lock) under multi-threading, which causes only one thread to be working at the same time under multi-threading. This form of multithreading may be helpful for IO-intensive tasks, but it makes no sense for model deployment, which is as computationally intensive.
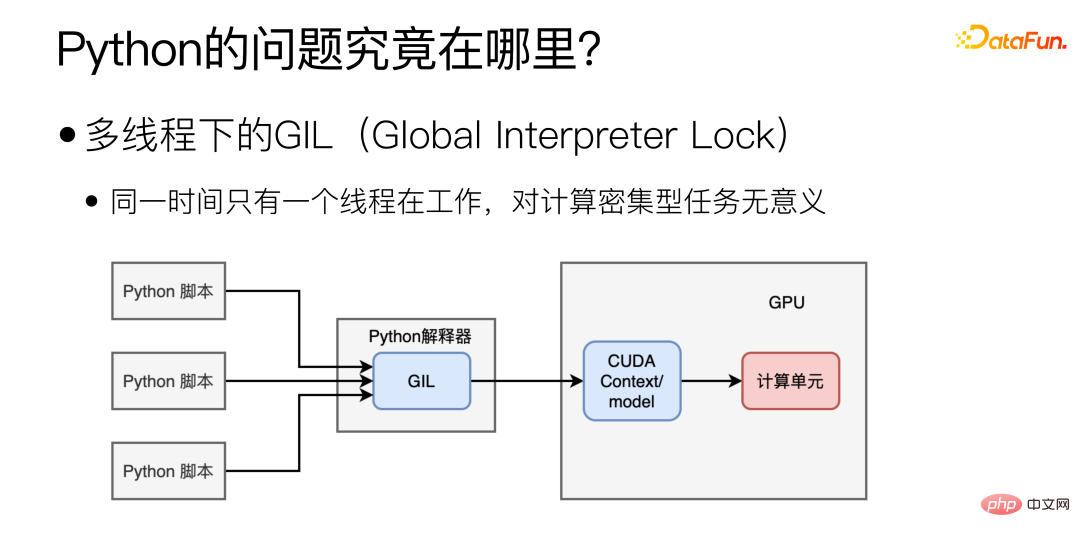
Can the problem be solved by switching to multiple processes?
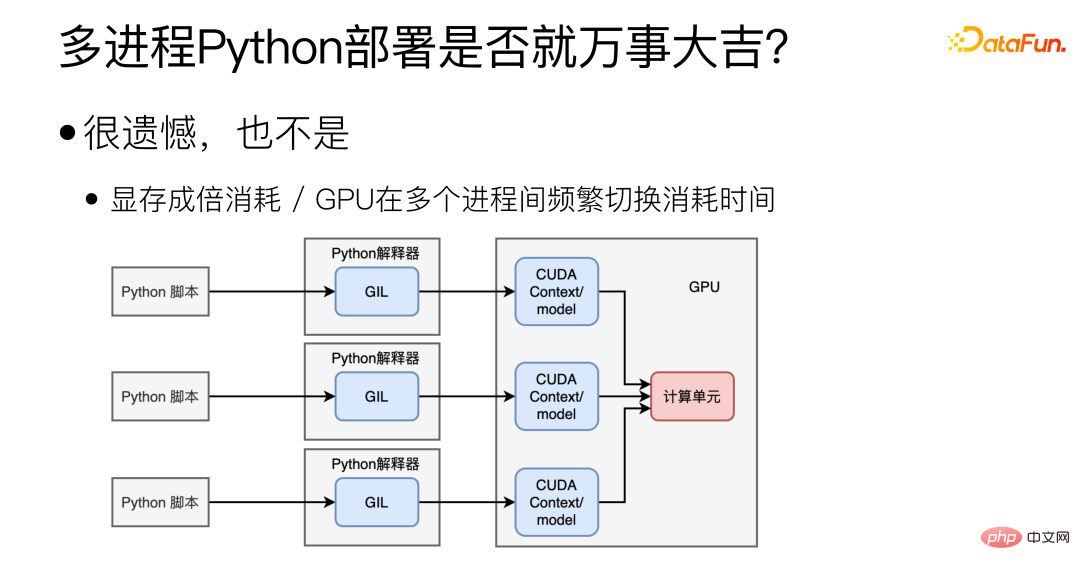
In fact, no, multi-process can indeed solve the problem of GIL, but it will also bring Other new questions. First of all, it is difficult to share CUDA Context/model between multiple processes, which will cause a lot of waste of video memory. In this case, several models cannot be deployed on one graphics card. The second is the problem of the GPU. The GPU can only perform the tasks of one process at the same time, and the frequent switching of the GPU between multiple processes also consumes time.
For Python scenarios, the ideal mode is as shown below:
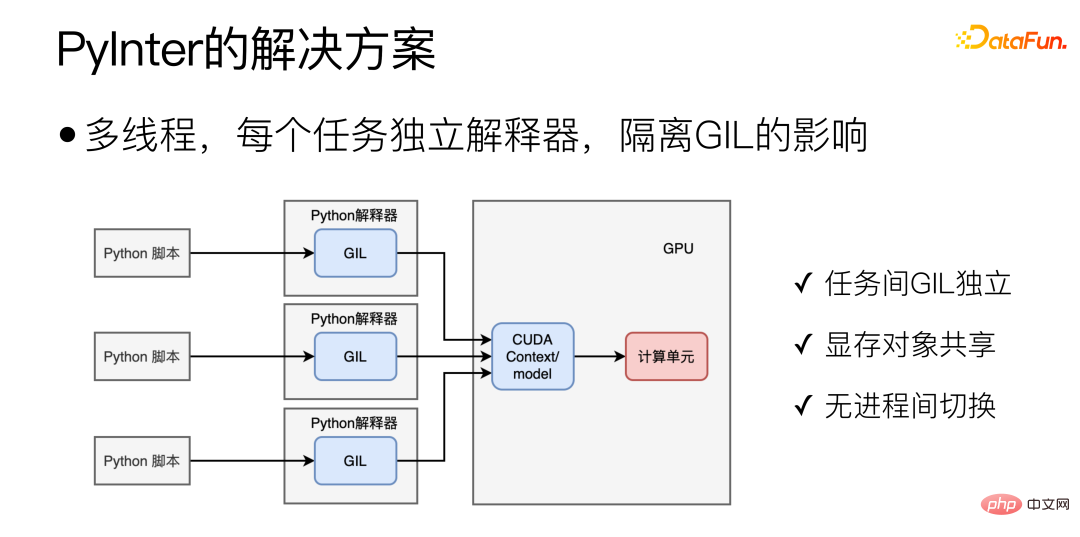
The key to the implementation of PyInter is the isolation of dynamic libraries within the process. The isolation of the interpreter is essentially the isolation of dynamic libraries. Here we have developed a self-developed dynamic library loader, similar to dlopen, but Supports two dynamic library loading methods: "isolated" and "shared".
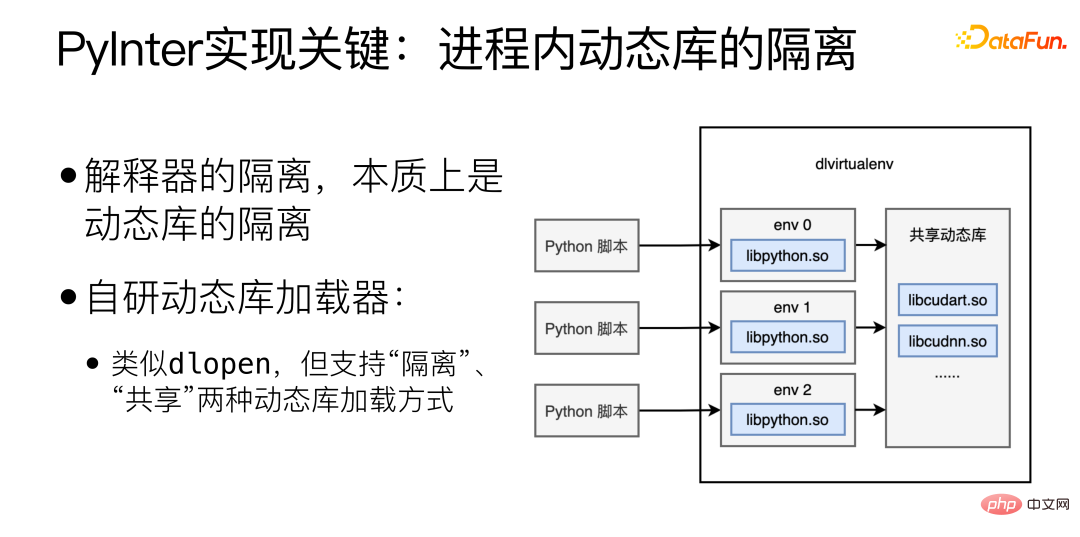
## Loading dynamic libraries in "isolated" mode will load dynamic libraries into different Virtual spaces, different virtual spaces cannot see each other. If the dynamic library is loaded in "shared" mode, the dynamic library can be seen and used anywhere in the process, including inside each virtual space.
Load the Python interpreter-related libraries in "isolated" mode, and then load the cuda-related libraries in "shared" mode, thus achieving isolated interpretation processor while sharing video memory resources.
4. Scheduling issues faced by microservicesMultiple microservices play an equal importance and The same effect, then how to achieve dynamic load balancing among multiple microservices. Dynamic load balancing is important, but almost impossible to do perfectly.
#Why is dynamic load balancing important? The reasons are as follows:
(1) Machine hardware differences (CPU / GPU);
(2) Request length difference (2 words translated / 200 words translated);
(3) Random load balancing, long tail The effect is obvious: ① The difference between P99/P50 can reach 10 times; ② The difference between P999/P50 can reach 20 times. # (4) For microservices, the long tail is the key to determining the overall speed. #The time taken to process a request varies greatly, and differences in computing power, request length, etc. will all affect the time taken. As the number of microservices increases, there will always be some microservices that hit the long tail, which will affect the response time of the entire system. #Why is dynamic load balancing so difficult to perfect? #Option 1: Run Benchmark on all machines. #This solution is not "dynamic" and cannot cope with the difference in Request length. And there is no perfect benchmark that can reflect performance. Different machines will respond differently to different models. #Option 2: Get the status of each machine in real time and send the task to the one with the lightest load. This solution is relatively intuitive, but the problem is that there is no real "real time" in a distributed system, and information is passed from one machine to another. It will definitely take time, and during this time, the machine status can change. For example, at a certain moment, a certain Worker machine is the most idle, and multiple Master machines responsible for task distribution all sense it, so they all assign tasks to this most idle Worker, and this most idle Worker instantly becomes This is the famous tidal effect in load balancing. Option 3: Maintain a globally unique task queue. All Masters responsible for task distribution send tasks to the queue, and all Workers take tasks from the queue. Task. #In this solution, the task queue itself may become a single point bottleneck, making it difficult to expand horizontally. The fundamental reason why dynamic load balancing is difficult to perfect is that the transmission of information takes time. When a state is observed, this state must It has passed. There is a video on Youtube that I recommend to everyone, "Load Balancing is Impossible" https://www.youtube.com/watch?v=kpvbOzHUakA. Regarding the dynamic load balancing algorithm, the Power of 2 Choices algorithm randomly selects two workers and assigns tasks to the more idle one. This algorithm is the basis for the dynamic equalization algorithm we currently use. However, there are two major problems with the Power of 2 Choices algorithm: First, before each task is assigned, the idle status of the Worker needs to be queried, which adds an RTT; in addition, it is possible that the two randomly selected workers happen to be very busy. In order to solve these problems, we have made improvements. 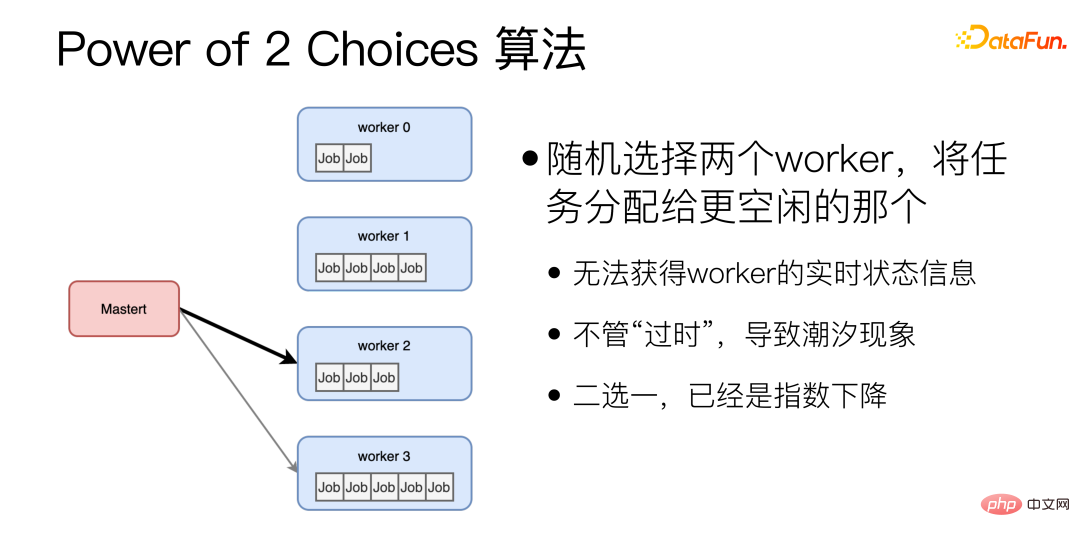
The improved algorithm is Joint-Idle-Queue.
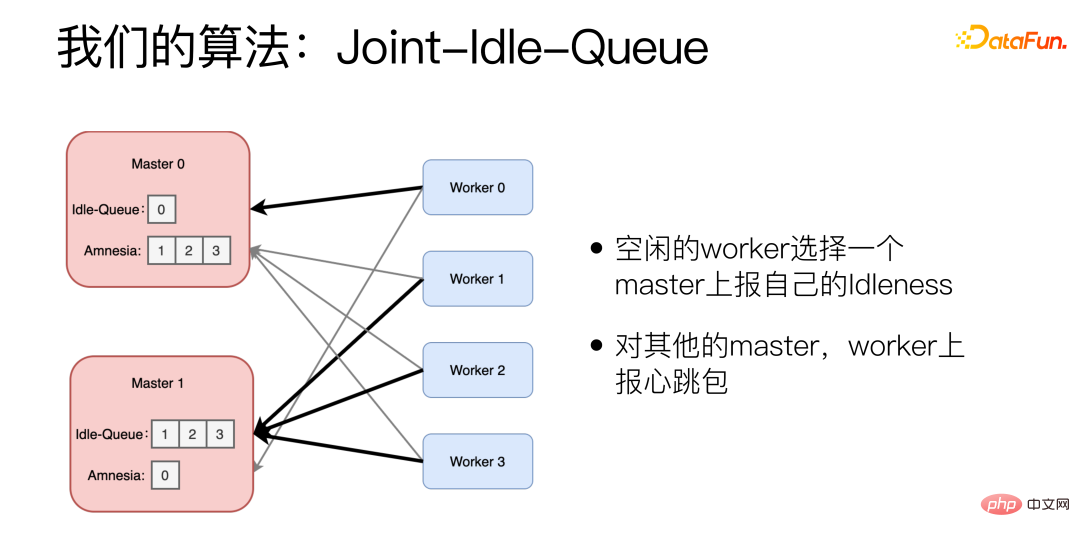
We have added two parts to the Master machine, Idle-Queue and Amnesia. Idle-Queue is used to record which Workers are currently idle. Amnesia records which workers have sent heartbeat packets to itself in the recent period. If a worker has not sent a heartbeat packet for a long time, Amnesia will gradually forget it. Each Worker periodically reports whether it is idle. The idle Worker selects a Master to report its IdIeness and reports the number it can process. The Worker also uses the Power of 2 Choices algorithm when selecting the Master. For other Masters, the Worker reports heartbeat packets.
When a new task arrives, the Master randomly picks two from the Idle-Queue and chooses the one with lower historical latency. If the Idle-Queue is empty, Amnesia will be viewed. Randomly pick two from Amnesia and choose the one with lower historical latency.
In terms of actual effect, using this algorithm, P99/P50 can be compressed to 1.5 times, which is 10 times better than the Random algorithm.
In the practice of model servitization, we have encountered three challenges:
The first is how to manage a large number of microservices and how to optimize the development, online and deployment processes. Our solution is to automate as much as possible, extract repetitive processes and make them Automated pipelines and procedures.
The second aspect is model performance optimization. How to make deep learning model microservices run more efficiently. Our solution is to start from the actual needs of the model and customize services that are relatively stable and have large traffic. For optimization, PyInter is used for experimental services, and Python scripts are used to directly launch services, which can also achieve the performance of C.
The third is the task scheduling problem. How to achieve dynamic load balancing. Our solution is to develop the JIQ algorithm based on Power of 2 Choices. This greatly alleviates the long-tail problem of time-consuming services.
The above is the detailed content of WeChat NLP algorithm microservice governance. For more information, please follow other related articles on the PHP Chinese website!
 What are the production methods of html5 animation production?
What are the production methods of html5 animation production?
 Three major characteristics of java
Three major characteristics of java
 jdk environment variable configuration
jdk environment variable configuration
 mstsc remote connection failed
mstsc remote connection failed
 What are the common management systems?
What are the common management systems?
 Solution to invalid signature
Solution to invalid signature
 What are the definitions of arrays?
What are the definitions of arrays?
 How to enter root privileges in linux
How to enter root privileges in linux








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



