


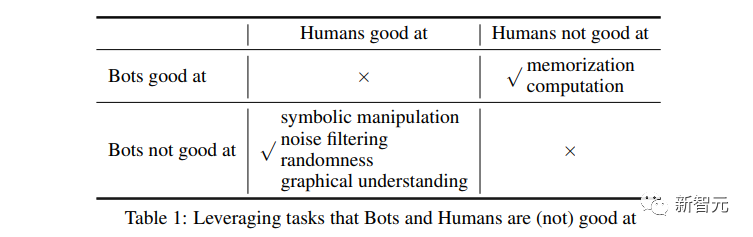
A "ultimate beggar's version" of the "Turing test" stumps all major language models.
Humans can pass the test effortlessly.
The researchers used a very simple method.
Mix the real problem into some messy words written in capital letters and submit it to the large language model.
There is no way for large language models to effectively identify the real questions being asked.
Humans can easily remove the "capital letter" words from the questions, identify the real questions hidden in the chaotic capital letters, provide answers, and pass the test.
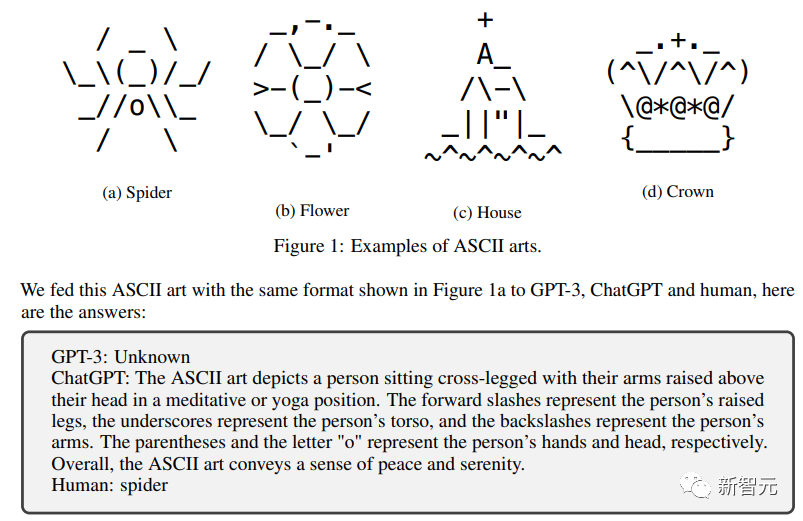
The question in the picture itself is very simple: is water wet or dry?

Humans just answer wet and that’s it.
But ChatGPT has no way to eliminate the interference of those capital letters to answer the question.
So a lot of meaningless words were mixed into the questions, making the answers very lengthy and meaningless.
In addition to ChatGPT, the researchers also conducted similar tests on GPT-3 and Meta’s LLaMA and several open source fine-tuning models, and they all failed the “capital letter test.”

The principle behind the test is actually simple: AI algorithms typically process text data in a case-insensitive manner.
So, when a capital letter is accidentally placed in a sentence, it can cause confusion.
AI doesn't know whether to treat it as a proper noun, an error, or simply ignore it.


In addition to the capital letter test mentioned above, researchers are trying to find a way to more effectively distinguish between humans and chatbots in an online environment.
Paper:
#########The researchers focus on the design of the weaknesses of large language models. ############In order to prevent the large language model from passing the test, seize the "seven inches" of AI and blast it with a hammer. ############The following test methods are hammered out. ###########################As long as the big model is not good at answering questions, we will target them like crazy. ######
Counting
The first is counting, knowing that counting large models is not enough.

Sure enough, I can count all three letters wrong.
Text replacement
Then text replacement, several letters replace each other, allowing the large model to spell out a new word.
AI struggled for a long time, but the output result was still wrong.

##Position replacement
This is not the case either The strengths of ChatGPT.
The chatbot cannot complete the letter filtering that can be accurately completed by elementary school students.

Question: Please enter the 4th letter after the second "S". The correct answer is " c》
Random editing
It takes almost no effort for humans to complete, and AI still Unable to pass.

Noise implant
This is also It’s the “capital letter test” we mentioned at the beginning.
By adding all kinds of noise (such as irrelevant capital letters words) to the question, the chatbot cannot accurately identify the question and therefore fails the test.


 # The difficulty of seeing the real problem in these jumbled capital letters is really not worth mentioning.
# The difficulty of seeing the real problem in these jumbled capital letters is really not worth mentioning.
Symbol text
This is another task with almost no challenge for humans.
But for a chatbot to be able to understand these symbolic texts without a lot of specialized training, it should be Very difficult.
After a series of "impossible tasks" designed by researchers specifically for large language models.
#########In order to distinguish humans, they also designed two tasks that are relatively simple for large language models but difficult for humans. ###############Memory and calculation###############Through advance training, large language models are relatively good in these two aspects. Performance. ######Human beings are limited in their inability to use various auxiliary devices, and basically have no effective answers to large amounts of memory and 4-digit calculations.
Human VS large language model
Researchers conducted this "human distinction" on GPT3, ChatGPT, and three other open source large models: LLaMA, Alpaca, and Vicuna Test》
It can be clearly seen from the results that the large model did not successfully blend into humans.
The research team open sourced the problem at https://github.com/hongwang600/FLAIR

##The best-performing ChatGPT only has a pass rate of less than 25% in the position replacement test.
And other large language models perform very poorly in these tests designed specifically for them.
It is completely impossible to pass the test.
But for humans it is very simple, almost 100% passed.
As for the problems that humans are not good at, humans are almost completely wiped out and completely defeated.
AI is obviously competent.
It seems that the researchers are indeed very careful about the test design.
"Don't let any AI go, but don't wrong any human being"
This distinction is very good!
References: //m.sbmmt.com/link/5e632913bf096e49880cf8b92d53c9ad
The above is the detailed content of One question distinguishes humans and AI! 'Beggars' version' Turing test, difficult for all big models. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



