


Install PyPDF2 module
# This module is strictly case-sensitive, y is lowercase, and the rest is uppercase
pip3 install PyPDF2
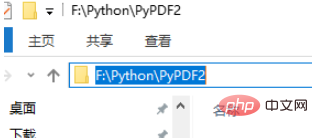
After the installation is completed, create a folder specifically to store this project on the local hard disk. The storage path here is F:\Python\PyPDF2. There is a Python folder on the F drive, and I created it in it. A folder named after this module to store it separately and distinguish it from other projects.
Create files and prepare PDF documents
Looking for a larger PDF document for practice, I downloaded it from the Django official website This document is large enough, with more than 1,900 pages, which is definitely enough for practicing. If necessary, go to the official website to download, or directly reply 'pdf' on my official account to get the download link, and then create a PDFCF.py project file .
Start writing
The program starts with two lines and writes the two sentences above and below. The first sentence means to specify the running program of this file. The second sentence This sentence is a description of this file. The function of this cannot be seen yet, but if you know how to quickly execute programs in batches, you will know its function. I will not go into details here.
#! python# PDFCF.py - pdf文件拆分程序
The idea of document splitting
It is not fixed how many parts it is split into, but it is fixed how many pages each part consists of , and then dynamically calculate the number of splits. Once you have the idea of splitting, the next step is to list the calculation formula.
拆分的份数= 文档总页数 / 拆份每个pdf组成的页数
For example:
If we want to split a pdf document with a total of 35 pages, it will be composed of 10 pages each For a new document, the calculation formula for how many parts it can be split into is as follows:
3.5 = 35 / 10
At this time, everyone pays attention. If the remainder is 0.5, what does it mean? Using this example, it means that there are 5 pages left after splitting into 3 parts. In this case, no matter what the remainder is, you have to move forward by 1 to complete the entire split. The result of this document split is that the first 3 documents Each document consists of 10 pages, and the fourth document consists of the last 5 pages. If it is divisible, the result is directly the number of split copies.
Python split calculation formula:
if 35 % 10: # 判断是否有余数 35 // 10 + 1 # 取余数整数部分加1else: 0 # 能整除则直接返回0 # 将这个循环写到一行4 = 35 // 10 + 1 if 35 % 10 else 0
How to split it specifically?
Let’s take this 35-page document split as an example:
Loop through each page of data for num in range(35), get the data of each page, and then specify the split page range to split:
The first document starts from 0- -10, excluding 10
The second document is from 10--20, excluding 20
The third document is from 20 - 30, not including 30
The fourth document is from 30--35, not including 35
We found the pattern, each time we traverse the The rule of a number is the number of pages in a document, which can be obtained by multiplying the number it belongs to. We found that there is no pattern in the second number. In fact, there is a pattern if we observe carefully. If we sort the number of splits, this example is 1--4. The second number is the current number of splits multiplied by each The number of pages the document consists of (the number of pages is fixed at 10).
But when we traverse for the first time, we start from 0, which makes num unusable. Then we modify it and start traversing from 1, range(1,35), traverse from the beginning, based on the range is not Contains the last characteristic of itself, so that one page of documents will be missing after traversing, then we add 1 to it and become
for num in range(1,35 1 )
The first document starts from 10*(1-1)--10*1, excluding 10
The two documents are from 10*(2-1)--10*2, not including 20
The third document is from 10*(3-1)-10*3, not The fourth document containing 30
The specific traversal code is as follows:
for num in range(1,35+1): pass for i in range(10 * (num-1), 10 * num if num != 4 else 35): pass
Complete splitting procedure:
import PyPDF2
Split list method to split PDF:
#! python
How to use?
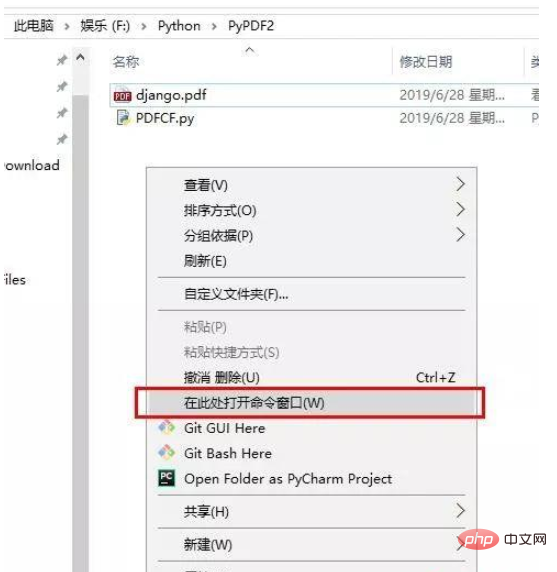
Hold down the Shift key inside the project folder, right-click the mouse, choose to open the command window here, enter PDFCF.py, and press Enter to change it according to your needs The value of n.

The above is the detailed content of How to split PDF documents using PyPDF2 module in Python. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



