The basic unit of computer storage is the byte, which is composed of 8 bits. Since English only consists of 26 letters plus a number of symbols, English characters can be stored directly in bytes. But other languages (such as Chinese, Japanese, Korean, etc.) have to use multiple bytes for encoding due to the large number of characters.
With the spread of computer technology, non-Latin character encoding technology continues to develop, but there are still two major limitations:
Does not support multiple languages: The encoding scheme of one language cannot be used for another language
There is no unified standard: for example, Chinese has multiple encoding standards such as GBK, GB2312, GB18030
Because the encoding methods are not uniform, developers need to convert back and forth between different encodings, and many errors will inevitably occur. In order to solve this kind of inconsistency problem, the Unicode standard was proposed. Unicode organizes and encodes most of the writing systems in the world, allowing computers to process text in a unified way. Unicode currently contains more than 140,000 characters and naturally supports multiple languages. (Unicode’s uni is the root of “unification”)
2 Unicode in Python
2.1 Benefits of Unicode objects
After Python 3, Unicode is used internally in the str object Represents, and therefore becomes a Unicode object in the source code. The advantage of using Unicode representation is that the core logic of the program uses Unicode uniformly, and only needs to be decoded and encoded at the input and output layers, which can avoid various encoding problems to the greatest extent.
The diagram is as follows:
##2.2 Python’s optimization of UnicodeProblem: Since Unicode contains more than 140,000 characters, each A character requires at least 4 bytes to save (this is probably because 2 bytes are not enough, so 4 bytes are used, and 3 bytes are generally not used). The ASCII code for English characters requires only 1 byte. Using Unicode will quadruple the cost of frequently used English characters. First of all, let’s take a look at the size difference of different forms of str objects in Python:
It can be seen that Python internally optimizes Unicode objects: according to the text content, the underlying storage unit is selected . The underlying storage of Unicode objects is divided into three categories according to the Unicode code point range of text characters:
PyUnicode_1BYTE_KIND: All character code points are between U 0000 and U 00FF
PyUnicode_2BYTE_KIND: All character code points are between U 0000 and U FFFF, and at least one character has a code point greater than U 00FF
PyUnicode_1BYTE_KIND: All character code points are between U 0000 and U 10FFFF, and at least one character has a code point greater than U FFFF
##The corresponding enumeration is as follows:
enum PyUnicode_Kind {
/* String contains only wstr byte characters. This is only possible
when the string was created with a legacy API and _PyUnicode_Ready()
has not been called yet. */
PyUnicode_WCHAR_KIND = 0,
/* Return values of the PyUnicode_KIND() macro: */
PyUnicode_1BYTE_KIND = 1,
PyUnicode_2BYTE_KIND = 2,
PyUnicode_4BYTE_KIND = 4
};
Copy after login
According to different Classification, select different storage units:
/* Py_UCS4 and Py_UCS2 are typedefs for the respective
unicode representations. */
typedef uint32_t Py_UCS4;
typedef uint16_t Py_UCS2;
typedef uint8_t Py_UCS1;
Copy after login
The corresponding relationship is as follows:
Text type
Character storage unit
Character storage unit size (bytes)
PyUnicode_1BYTE_KIND
Py_UCS1
1
PyUnicode_2BYTE_KIND
Py_UCS2
2
PyUnicode_4BYTE_KIND
Py_UCS4
4
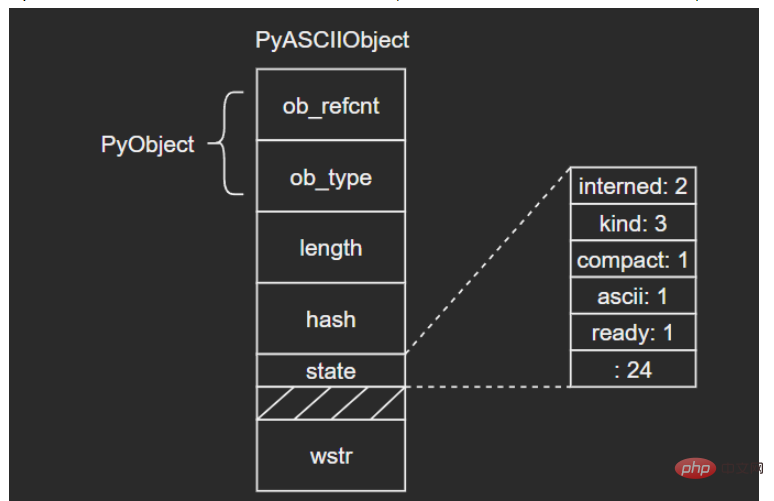
Since the Unicode internal storage structure varies depending on the text type, the type kind must be saved as a Unicode object public field. Python internally defines some flag bits as Unicode public fields: (Due to the author's limited level, all the fields here will not be introduced in the subsequent content. You can learn about it yourself later. Hold your fist~)
interned: Whether to maintain the interned mechanism
kind: type, used to distinguish the size of the underlying storage unit of characters
compact: memory allocation method, whether the object and the text buffer are separated
asscii: Whether the text is all pure ASCII
Through the PyUnicode_New function, according to the number of text characters size and the maximum character maxchar initializes the Unicode object. This function mainly selects the most compact character storage unit and underlying structure for Unicode objects based on maxchar: (The source code is relatively long, so it will not be listed here. You can understand it by yourself. It is shown in table form below)
maxchar < 128
128 <= maxchar < 256
256 <= maxchar < 65536
65536 <= maxchar < MAX_UNICODE
##kind
PyUnicode_1BYTE_KIND
PyUnicode_1BYTE_KIND
PyUnicode_2BYTE_KIND
PyUnicode_4BYTE_KIND
ascii
1
0
0
0
Character storage unit size (bytes)
1
1
2
4
Underlying structure
PyASCIIObject
PyCompactUnicodeObject
PyCompactUnicodeObject
PyCompactUnicodeObject
3 Unicode对象的底层结构体
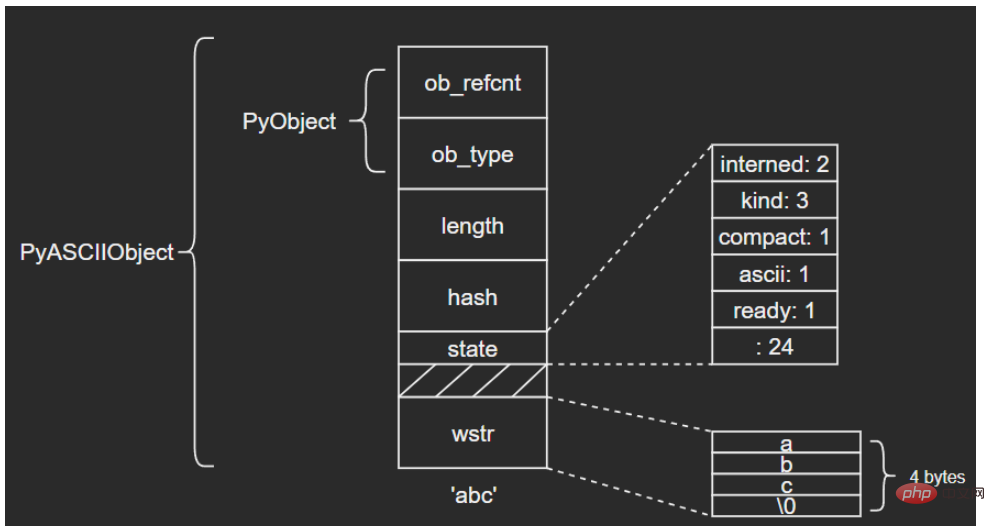
3.1 PyASCIIObject
C源码:
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
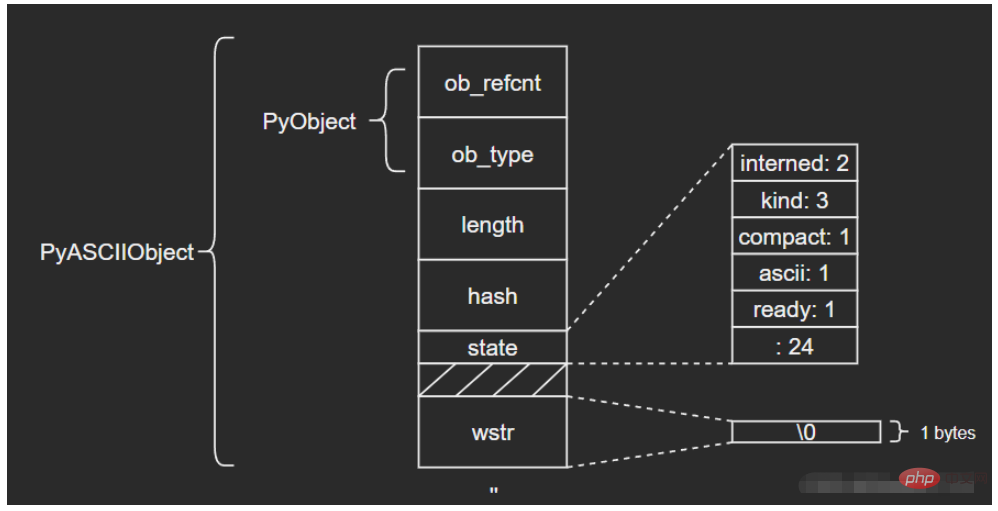
wchar_t *wstr; /* wchar_t representation (null-terminated) */
} PyASCIIObject;
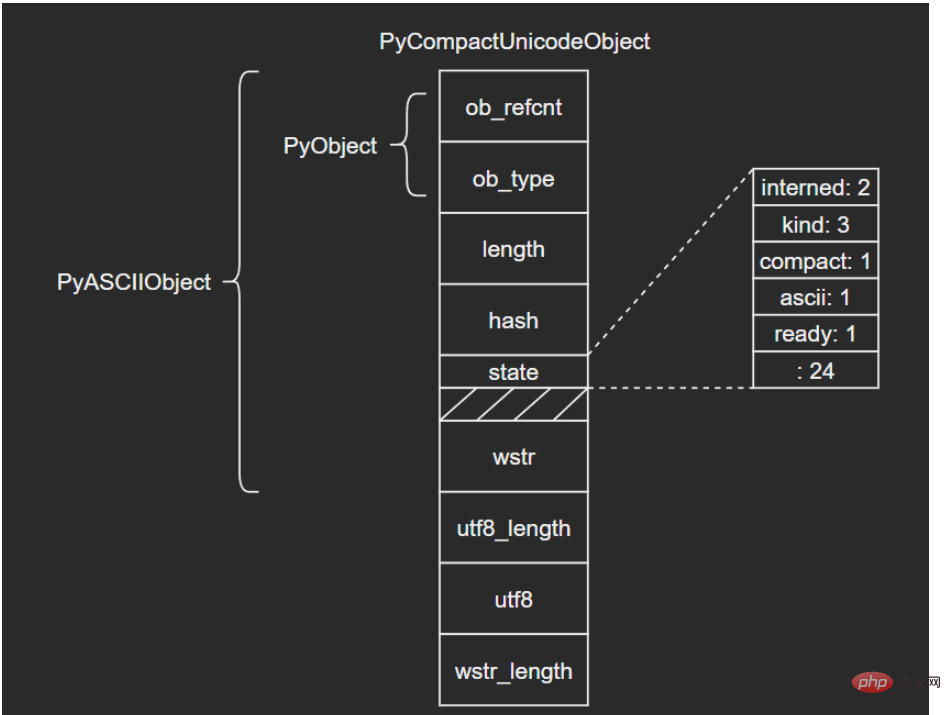
/* Non-ASCII strings allocated through PyUnicode_New use the
PyCompactUnicodeObject structure. state.compact is set, and the data
immediately follow the structure. */
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;
/* Strings allocated through PyUnicode_FromUnicode(NULL, len) use the
PyUnicodeObject structure. The actual string data is initially in the wstr
block, and copied into the data block using _PyUnicode_Ready. */
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
Copy after login
3.4 示例
在日常开发时,要结合实际情况注意字符串拼接前后的内存大小差别:
>>> import sys
>>> text = 'a' * 1000
>>> sys.getsizeof(text)
1049
>>> text += '????'
>>> sys.getsizeof(text)
4080
/* This dictionary holds all interned unicode strings. Note that references
to strings in this dictionary are *not* counted in the string's ob_refcnt.
When the interned string reaches a refcnt of 0 the string deallocation
function will delete the reference from this dictionary.
Another way to look at this is that to say that the actual reference
count of a string is: s->ob_refcnt + (s->state ? 2 : 0)
*/
static PyObject *interned = NULL;
void
PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
#ifdef Py_DEBUG
assert(s != NULL);
assert(_PyUnicode_CHECK(s));
#else
if (s == NULL || !PyUnicode_Check(s))
return;
#endif
/* If it's a subclass, we don't really know what putting
it in the interned dict might do. */
if (!PyUnicode_CheckExact(s))
return;
if (PyUnicode_CHECK_INTERNED(s))
return;
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
Py_ALLOW_RECURSION
t = PyDict_SetDefault(interned, s, s);
Py_END_ALLOW_RECURSION
if (t == NULL) {
PyErr_Clear();
return;
}
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
/* The two references in interned are not counted by refcnt.
The deallocator will take care of this */
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}
>>> a = 'abc'
>>> b = 'ab' + 'c'
>>> id(a), id(b), a is b
(2752416949872, 2752416949872, True)
Copy after login
The above is the detailed content of Python built-in type str source code analysis. For more information, please follow other related articles on the PHP Chinese website!
Statement of this Website
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
The key to running Jupyter Notebook in VS Code is to ensure that the Python environment is properly configured, understand that the code execution order is consistent with the cell order, and be aware of large files or external libraries that may affect performance. The code completion and debugging functions provided by VS Code can greatly improve coding efficiency and reduce errors.