


Recently, EMNLP 2022, the top conference in the field of natural language processing, was held in Abu Dhabi, the capital of the United Arab Emirates.

A total of 4190 papers were submitted to this year’s conference. In the end, 829 papers were accepted (715 long papers, 114 papers), and the overall acceptance rate was 20%, not much different from previous years.
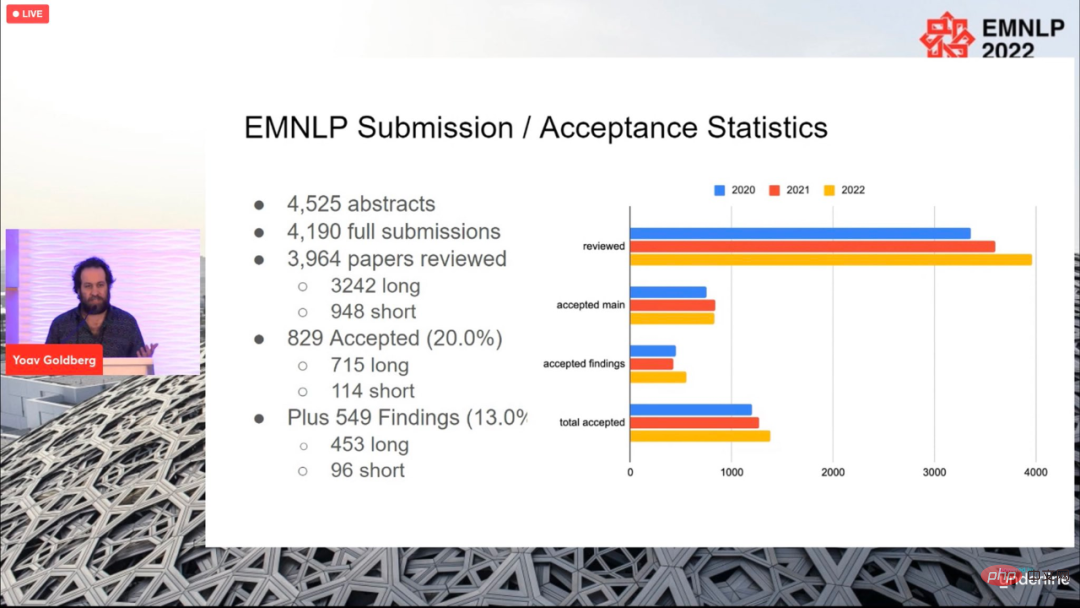
The conference ended on December 11, local time, and the paper awards for this year were also announced, including Best Long Paper (1), Best Short Paper (1 piece), Best Demo Paper (1 piece).

Paper: Abstract Visual Reasoning with Tangram Shapes
Paper abstract: In this paper, the researcher introduces "KiloGram", a user A resource library for studying abstract visual reasoning in humans and machines. KiloGram greatly improves existing resources in two ways. First, the researchers curated and digitized 1,016 shapes, creating a collection that was two orders of magnitude larger than those used in existing work. This collection greatly increases coverage of the entire range of naming variation, providing a more comprehensive perspective on human naming behavior. Second, the collection treats each tangram not as a single overall shape, but as a vector shape made up of the original puzzle pieces. This decomposition enables reasoning about whole shapes and their parts. The researchers used this new collection of digital jigsaw puzzle graphics to collect a large amount of textual description data, reflecting the high diversity of naming behavior.
We leveraged crowdsourcing to extend the annotation process, collecting multiple annotations for each shape to represent the distribution of annotations it elicited rather than a single sample. A total of 13,404 annotations were collected, each describing a complete object and its divided parts.
KiloGram’s potential is extensive. We used this resource to evaluate the abstract visual reasoning capabilities of recent multimodal models and observed that pre-trained weights exhibited limited abstract reasoning capabilities that improved greatly with fine-tuning. They also observed that explicit descriptions facilitate abstract reasoning by both humans and models, especially when jointly encoding language and visual input.
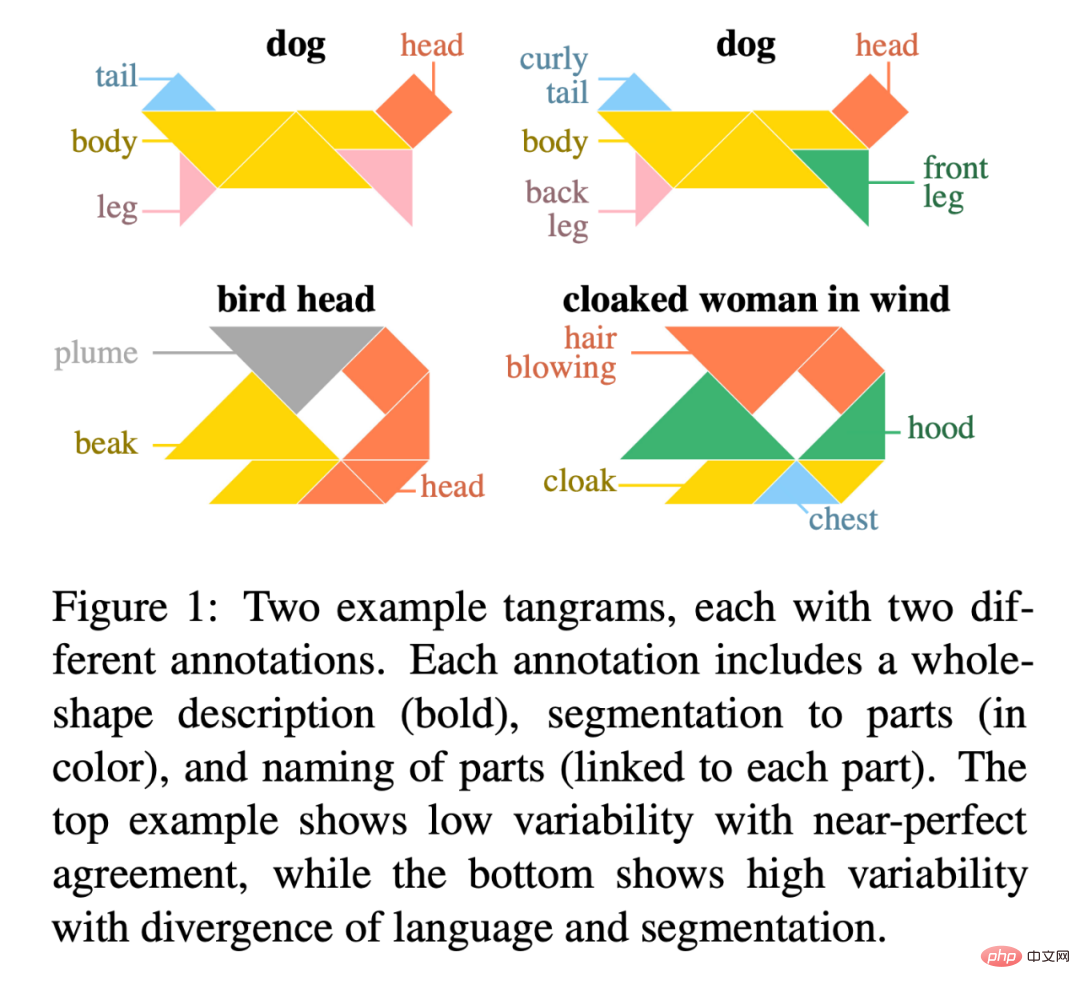
Figure 1 is an example of two tangrams, each with two different annotations. Each annotation includes a description of the entire shape (in bold), a segmentation of the parts (in color), and a name for each part (connected to each part). The upper example shows low variability for near perfect agreement, while the lower example shows high variability for language and segmentation divergence.
##KiloGram Address: https://lil.nlp .cornell.edu/kilogram
The best long paper nomination for this conference was won by two researchers, Kayo Yin and Graham Neubig.
Paper: Interpreting Language Models with Contrastive Explanations
Paper abstract: Model interpretability methods are often used to explain the decisions of NLP models on tasks such as text classification. , the output space of these tasks is relatively small. However, when applied to language generation, the output space often consists of tens of thousands of tokens, and these methods cannot provide informative explanations. Language models must consider various features to predict a token, such as its part of speech, number, tense, or semantics. Because existing explanatory methods combine evidence for all these features into a single explanation, this is less interpretable to human understanding.
To distinguish between different decisions in language modeling, researchers have explored language models that focus on contrastive explanations. They look for input tokens that stand out and explain why the model predicted one token but not another. Research demonstrates that contrastive explanations are much better than non-contrastive explanations at validating major grammatical phenomena, and that they significantly improve contrastive model simulatability for human observers. The researchers also identified groups of contrastive decisions for which the model used similar evidence and were able to describe which input tokens the model used in various language generation decisions.
Code address: https://github.com/kayoyin/interpret-lm

Paper: Topic-Regularized Authorship Representation Learning
Abstract :In this study, the researchers proposed Authorship Representation Regularization, a distillation framework that can improve cross-topic performance and can also handle unseen authors. This approach can be applied to any authorship representation model. Experimental results show that in the cross-topic setting, 4/6 performance is improved. At the same time, researchers' analysis shows that in data sets with a large number of topics, training shards set across topics have topic information leakage problems, thus weakening their ability to evaluate cross-topic attributes.
Best Demo Paper
Paper: Evaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
Paper abstract:Evaluation is a key part of machine learning (ML), and this study introduces Evaluate and Evaluation on Hub - a set of tools that help evaluate Tools for models and datasets in ML. Evaluate is a library for comparing different models and datasets, supporting various metrics. The Evaluate library is designed to support reproducibility of evaluations, document the evaluation process, and expand the scope of evaluations to cover more aspects of model performance. It includes more than 50 efficient specification implementations for a variety of domains and scenarios, interactive documentation, and the ability to easily share implementation and evaluation results.
Project address: https://github.com/huggingface/evaluate
In addition, the researcher also launched Evaluation on the Hub, the platform enables free, large-scale evaluation of over 75,000 models and 11,000 datasets on Hugging Face Hub with the click of a button.The above is the detailed content of EMNLP 2022 conference officially concluded, best long paper, best short paper and other awards announced. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



