


This article mainly introduces the machine learning model that powers ChatGPT. It will start with the introduction of large language models, delve into the revolutionary self-attention mechanism that enables GPT-3 to be trained, and then delve into reinforcement learning from human feedback. is the new technology that makes ChatGPT outstanding.
ChatGPT is a type of machine learning natural language processing model for inference, called a large language model (LLM). LLM digests large amounts of text data and infers relationships between words in the text. Over the past few years, these models have continued to evolve as computing power has advanced. As the size of the input data set and parameter space increases, the capabilities of LLM also increase.
The most basic training of a language model involves predicting a word in a sequence of words. Most commonly, this is observed for next token prediction and masking language models.
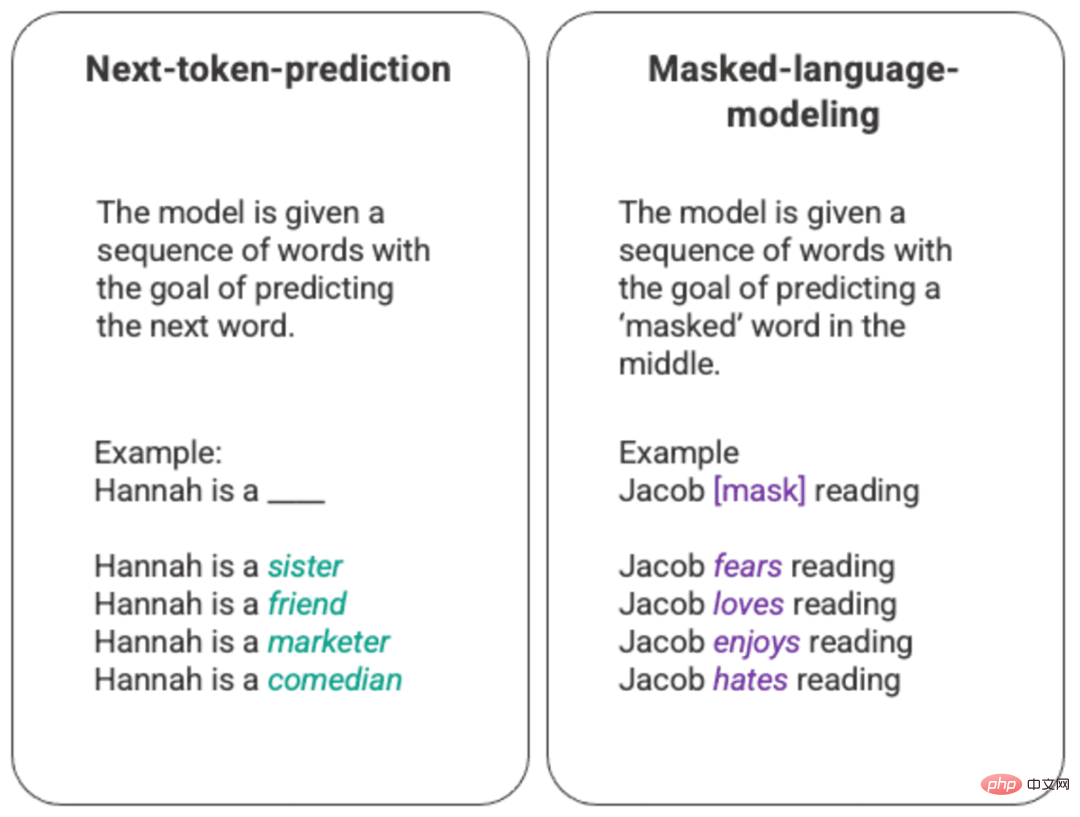
Generated next token prediction and arbitrary example of masked language model
In this basic ranking technique, usually through long short memory (LSTM) ) model, which fills in the gaps with the statistically most likely words given the environment and context. This sequential modeling structure has two main limitations.
To deal with this problem, in 2017, a team at Google Brain introduced converters. Unlike LSTM, the transformer can process all input data simultaneously. Using a self-attention mechanism, the model can assign different weights to different parts of the input data relative to any position in the language sequence. This feature enables large-scale improvements in injecting meaning into LLM and the ability to handle larger data sets.
The Generative Pretrained Transformer (GPT) model was first launched by OpenAI in 2018 and is called GPT -1. These models continued to evolve in GPT-2 in 2019, GPT-3 in 2020, and most recently, InstructGPT and ChatGPT in 2022. Before incorporating human feedback into the system, the biggest advances in GPT model evolution were driven by achievements in computational efficiency, which allowed GPT-3 to train on significantly more data than GPT-2, giving it a greater Diverse knowledge base and ability to perform a wider range of tasks.

Comparison of GPT-2 (left) and GPT-3 (right).
All GPT models utilize a transformer structure, which means they have an encoder to process the input sequence and a decoder to generate the output sequence. Both the encoder and decoder feature multi-headed self-attention mechanisms, allowing the model to weight various parts of the sequence differently to infer meaning and context. Additionally, the encoder utilizes masked language models to understand the relationships between words and produce more understandable responses.
The self-attention mechanism that drives GPT works by converting a token (a text fragment, which can be a word, a sentence, or other text grouping) into a vector that represents the importance of the token in the input sequence. . To do this, this model:
query, key, and value vector for each token in the input sequence. query vector in step 1 and the key vector of each other tag by taking the dot product of the two vectors. softmax function. value vector of each token, a final vector is produced that represents the importance of the token in the sequence. The "multi-head" attention mechanism used by GPT is an evolution of self-attention. Instead of executing steps 1-4 all at once, the model iterates this mechanism multiple times in parallel, each time generating a new query, key, and valueLinear projection of vector. By extending self-attention in this way, the model is able to grasp sub-meanings and more complex relationships in the input data.

Screenshot generated from ChatGPT.
Although GPT-3 introduces significant advances in natural language processing, it is limited in its ability to align with user intent. For example, GPT-3 might produce the following output:
Innovative training methods are introduced in ChatGPT to offset some of the inherent problems of standard LLM.
ChatGPT is a derivative of InstructGPT that introduces a novel method of incorporating human feedback into the training process to make the model The output is better integrated with the user's intent. Reinforcement learning from human feedback (RLHF) is described in depth in openAI's 2022 paper "Training language models to follow instructions with human feedback" and is briefly explained below.
The first development involved fine-tuning the GPT-3 model, employing 40 contractors to create a supervised training dataset where the input has a known output for the model to learn from. Input or prompts are collected from actual user input to the open API. The tagger then writes appropriate responses to the prompts, creating a known output for each input. The GPT-3 model is then fine-tuned using this new, supervised dataset to create GPT-3.5, also known as the SFT model.
To maximize the diversity of the prompts dataset, only 200 prompts can come from any given user ID, and any prompts sharing long common prefixes are removed. Finally, all tips containing personally identifiable information (PII) were removed.
After aggregating the prompt information from the OpenAI API, labelers were also asked to create prompt information samples to fill those categories with very few real sample data. Categories of interest include:
When generating a response, taggers are required to do their best to infer what the user's instructions were. This document describes the three main ways in which prompts can request information.
A compilation of prompts from the OpenAI API and handwritten prompts from labellers, resulting in 13,000 input/output samples for use in supervised models.
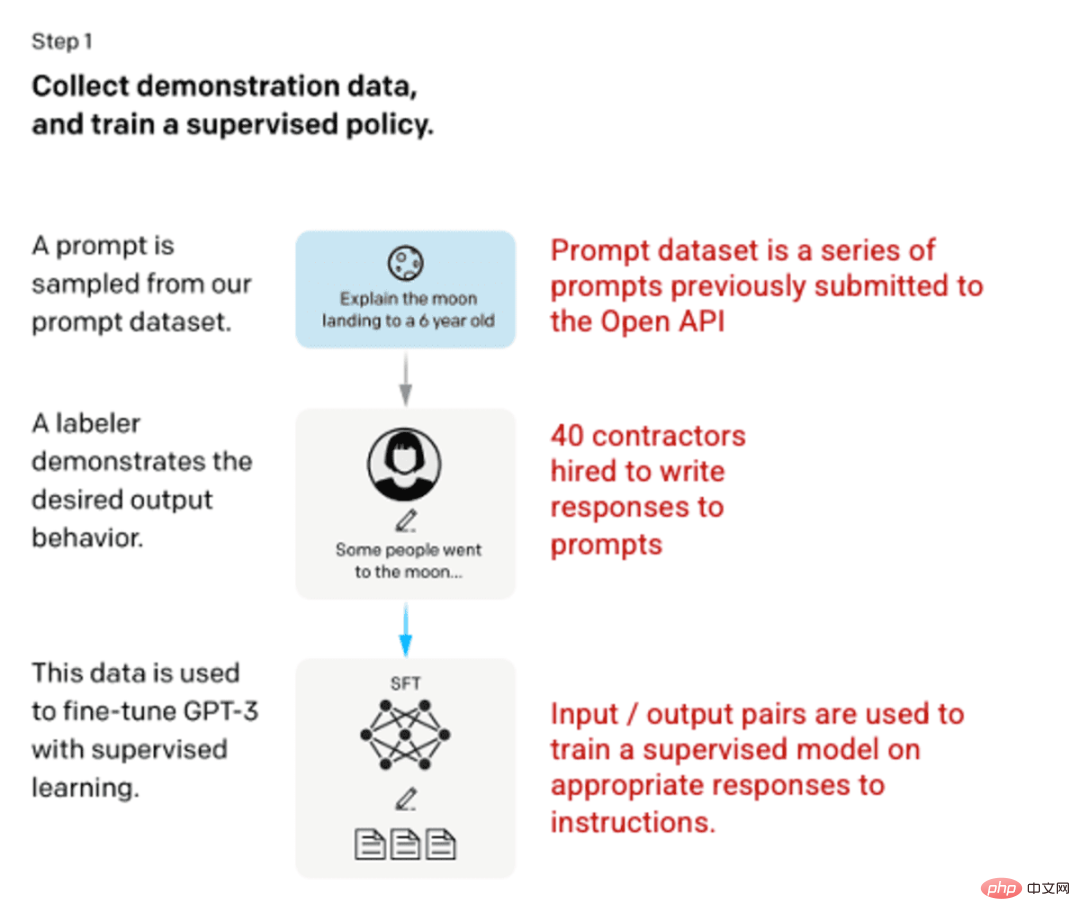
Image (left) inserted from "Training language models to follow instructions with human feedback" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Right) Additional context added in red.
After training the SFT model in step 1, the model produces better prompts for users , consistent response. The next improvement came in the form of training reward models, where the input to the model is a sequence of cues and responses, and the output is a scaled value called the reward. A reward model is required in order to take advantage of Reinforcement Learning, where the model learns to produce outputs that maximize its reward (see step 3).
To train the reward model, labelers provide 4 to 9 SFT model outputs for a single input prompt. They were asked to rank these outputs from best to worst, creating output-ranked combinations as follows:

Example of response-ranked combinations.
Including each combination in the model as a separate data point leads to overfitting (the inability to infer what is beyond the data seen). To solve this problem, the model is built using each set of rankings as a separate batch of data points.
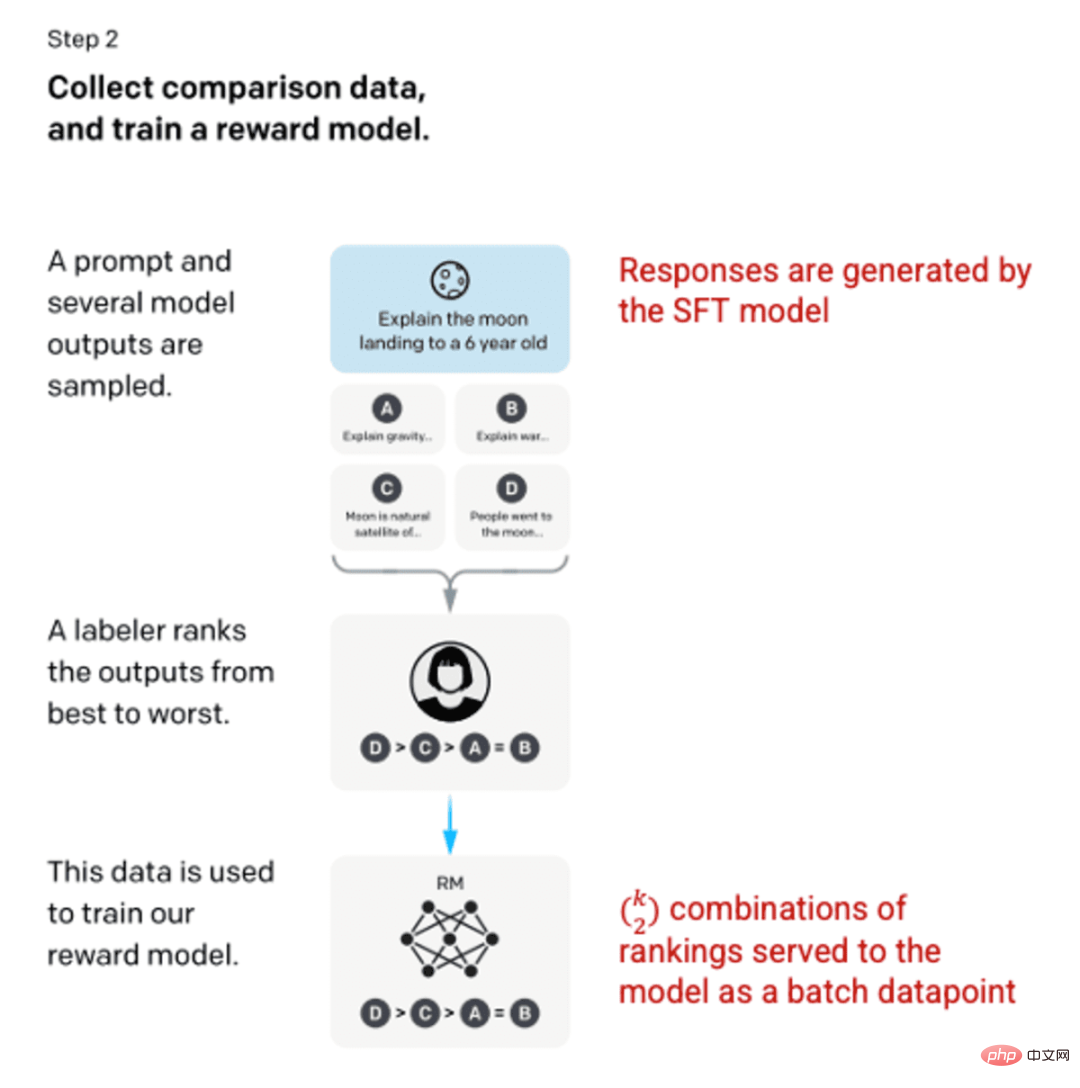
Image (left) inserted from "Training language models to follow instructions with human feedback" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Right) Additional context added in red.
In the final stage, the model is presented with a random prompt and a response is returned. The response is generated using the "policy" learned by the model in step 2. The policy represents the strategy the machine has learned to use to achieve its goal; in this case, maximizing its reward. Based on the reward model developed in step 2, a scaled reward value is then determined for the cue and response pairs. The rewards are then fed back into the model to develop the strategy.
In 2017, Schulman et al. introduced Proximal Policy Optimization (PPO), a method for updating the model’s policy as each response is generated. PPO incorporates the Kullback-Leibler (KL) penalty in the SFT model. KL divergence measures the similarity of two distribution functions and penalizes extreme distances. In this case, using KL penalty can reduce the distance of the response from the output of the SFT model trained in step 1 to avoid over-optimizing the reward model and deviating too much from the human intent dataset.
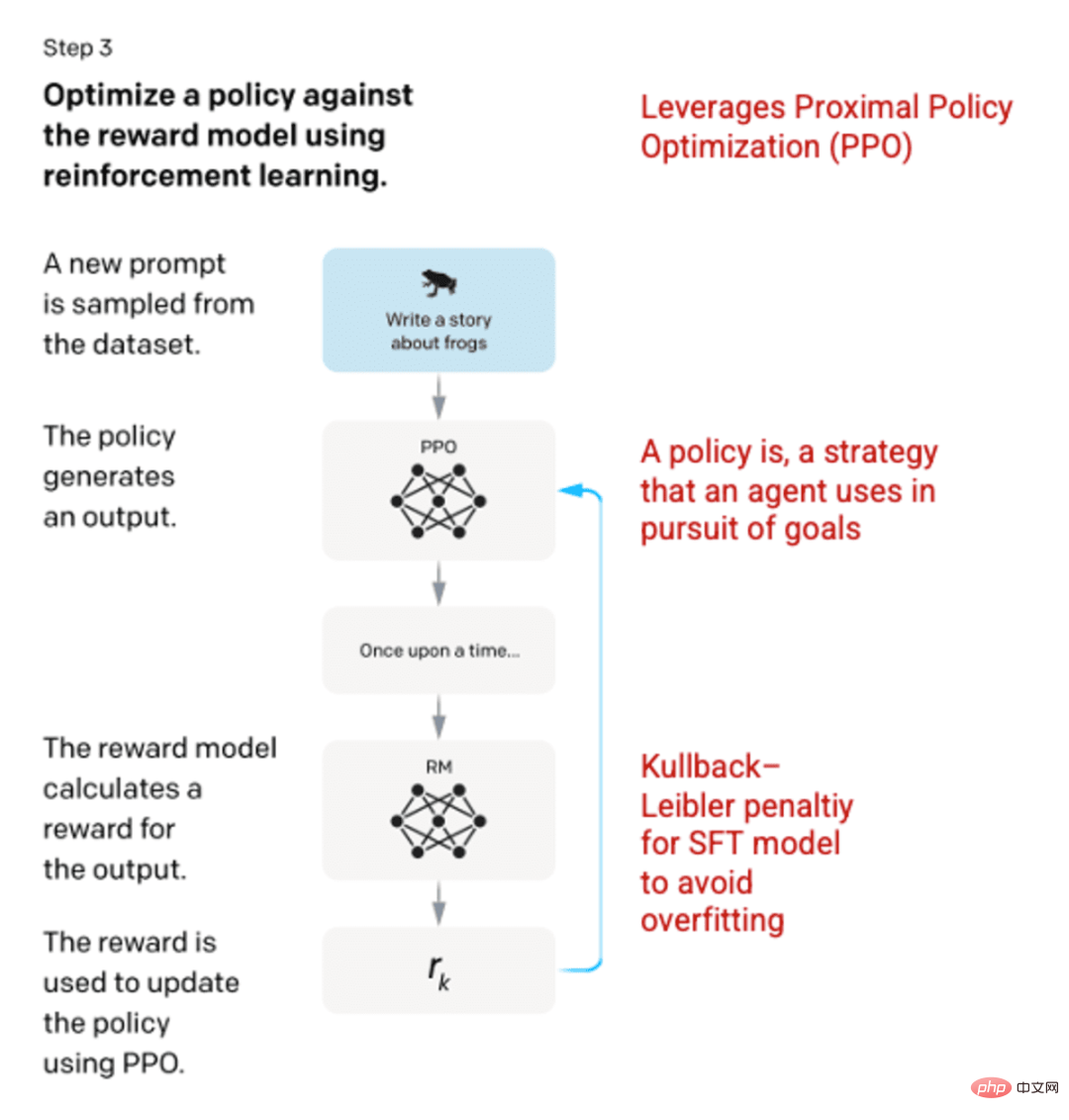
Image (left) inserted from "Training language models to follow instructions with human feedback" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Right) Additional context added in red.
Steps 2 and 3 of the process can be iterated over and over again, although this is not yet widely done in practice.

Screenshot generated from ChatGPT.
The evaluation of the model is performed by reserving a test set that the model has not seen during training. On the test set, a series of evaluations are conducted to determine whether the model performs better than its predecessor, GPT-3.
Usefulness: The model’s ability to infer and follow user instructions. Labelers preferred InstructGPT's output to GPT-3 85±3% of the time.
Authenticity: The tendency of the model to hallucinate. When evaluated using the TruthfulQA dataset, the PPO model produces outputs with a small increase in both truthfulness and informativeness.
Harmlessness: A model’s ability to avoid inappropriate, derogatory, and slanderous content. Harmlessness is tested using the RealToxicityPrompts data set. The test was conducted under three conditions.
For more information on the methods used to create ChatGPT and InstructGPT, please read the original paper "Training language models to follow instructions with human feedback" published by OpenAI, 2022 https://arxiv .org/pdf/2203.02155.pdf.
Screenshot generated from ChatGPT.
The above is the detailed content of ChatGPT: the fusion of powerful models, attention mechanisms and reinforcement learning. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



