


The core goal of the short video recommendation system is to drive DAU growth by improving user retention. Therefore, retention is one of the core business optimization indicators of each APP. However, retention is long-term feedback after multiple interactions between users and the system, and it is difficult to decompose it into a single item or a single list. Therefore, it is difficult for traditional point-wise and list-wise models to directly optimize retention.
The reinforcement learning (RL) method optimizes long-term rewards by interacting with the environment, and is suitable for directly optimizing user retention. This work models the retention optimization problem as a Markov decision process (MDP) with infinite horizon request granularity. Each time the user requests the recommendation system to decide an action, it is used to aggregate multiple different short-term feedback estimates (watch Duration, likes, attention, comments, retweets, etc.) ranking model scoring. The goal of this work is to learn policies, minimize the cumulative time interval between multiple user sessions, increase the frequency of app openings, and thereby increase user retention.
However, due to the characteristics of the retained signal, the direct application of existing RL algorithms has the following challenges: 1) Uncertainty: the retained signal is not only determined by the recommendation algorithm, but is also interfered by many external factors; 2) Bias: The retention signal has deviations in different time periods and user groups with different levels of activity; 3) Instability: Unlike game environments that return rewards immediately, retention signals usually return within hours to days, which will cause the RL algorithm to go online Training instability problem.
This work proposes the Reinforcement Learning for User Retention algorithm (RLUR) algorithm to solve the above challenges and directly optimize retention. Through offline and online verification, the RLUR algorithm can significantly improve the secondary retention index compared to the State of Art baseline. The RLUR algorithm has been fully implemented in the Kuaishou App and can continuously achieve significant secondary retention and DAU revenue. It is the first time in the industry that RL technology has been used to improve user retention in a real production environment. This work has been accepted into the WWW 2023 Industry Track.

## Author: Cai Qingpeng, Liu Shuchang, Wang Xueliang, Zuo Tianyou, Xie Wentao, Yang Bin, Zheng Dong, Jiang Peng
Paper address: https://arxiv.org/pdf/2302.01724.pdf
Problem ModelingAs shown in Figure 1(a), this work models the retention optimization problem as an infinite horizon request-based Markov Decision Process, in which the recommendation system is agent, the user is the environment. Every time the user opens the App, a new session i is opened. As shown in Figure 1(b), each time the user requests  the recommendation system decides a parameter vector
the recommendation system decides a parameter vector  based on the user status
based on the user status  , while n A ranking model that estimates different short-term indicators (viewing time, likes, attention, etc.) scores each candidate video j
, while n A ranking model that estimates different short-term indicators (viewing time, likes, attention, etc.) scores each candidate video j . Then the sorting function inputs the action and the scoring vector of each video to obtain the final score of each video, and selects the 6 videos with the highest scores to display to the user, and the user returns immediate feedback
. Then the sorting function inputs the action and the scoring vector of each video to obtain the final score of each video, and selects the 6 videos with the highest scores to display to the user, and the user returns immediate feedback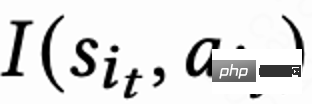 . When the user leaves the App, this session ends. The next time the user opens the App, session i 1 is opened. The time interval between the end of the previous session and the beginning of the next session is called return time (Returning time),
. When the user leaves the App, this session ends. The next time the user opens the App, session i 1 is opened. The time interval between the end of the previous session and the beginning of the next session is called return time (Returning time),  . The goal of this research is to train a strategy that minimizes the sum of callback times for multiple sessions.
. The goal of this research is to train a strategy that minimizes the sum of callback times for multiple sessions.
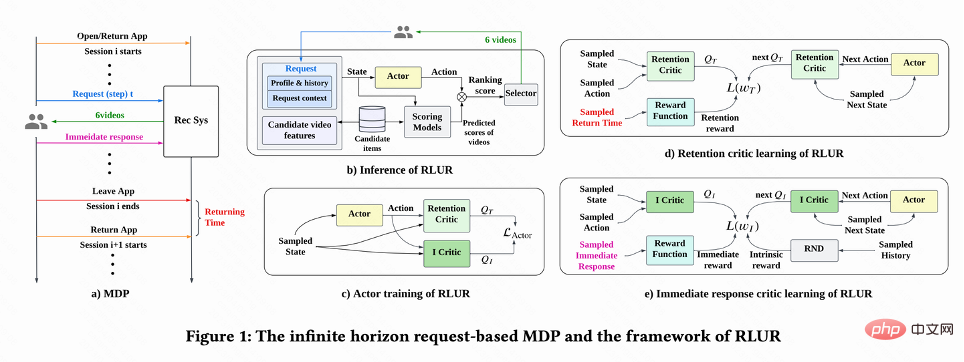
This work first discusses how to estimate the cumulative return visit time, and then proposes methods to solve several key challenges of retained signals. These methods are summarized into the Reinforcement Learning for User Retention algorithm, abbreviated as RLUR.
Estimation of return visit time
As shown in Figure 1(d), since the action is continuous, the The work adopts the temporal difference (TD) learning method of DDPG algorithm to estimate the return visit time.
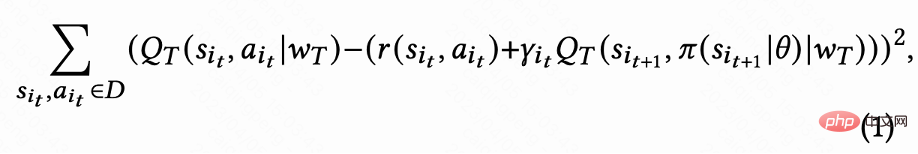
Since only the last request of each session has a return visit time reward, and the intermediate reward is 0, the author sets the discount factor The value of the last request in each session is
The value of the last request in each session is 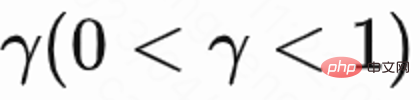 , and the value of other requests is 1. This setting can avoid the exponential decay of return visit time. And it can be theoretically proven that when loss (1) is 0, Q actually estimates the cumulative return time of multiple sessions,
, and the value of other requests is 1. This setting can avoid the exponential decay of return visit time. And it can be theoretically proven that when loss (1) is 0, Q actually estimates the cumulative return time of multiple sessions, 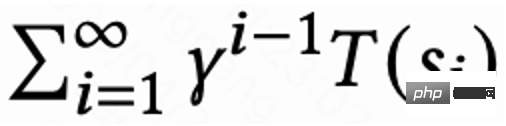 .
.
Solve the delayed reward problem
Since the return visit time only occurs at the end of each session , which will bring about the problem of low learning efficiency. The authors therefore use heuristic rewards to enhance policy learning. Since short-term feedback is positively related to retention, the author uses short-term feedback as the first heuristic reward. And the author adopts Random Network Distillation (RND) network to calculate the intrinsic reward of each sample as the second heuristic reward. Specifically, the RND network uses two identical network structures. One network is randomly initialized to fixed, and the other network fits the fixed network, and the fitting loss is used as an intrinsic reward. As shown in Figure 1(e), in order to reduce the interference of heuristic rewards on retention rewards, this work learns a separate critic network to estimate the sum of short-term feedback and intrinsic rewards. Right now 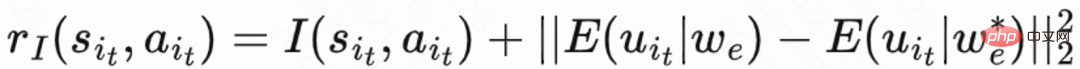 .
.
Solve the problem of uncertainty
Received many recommendations due to the time of return visit The uncertainty is high due to the influence of factors, which will affect the learning effect. This work proposes a regularization method to reduce variance: first estimate a classification model  to estimate the return visit time probability, that is, whether the estimated return visit time is shorter than
to estimate the return visit time probability, that is, whether the estimated return visit time is shorter than  ; Then use Markov's inequality to get the lower bound of the return visit time,
; Then use Markov's inequality to get the lower bound of the return visit time, 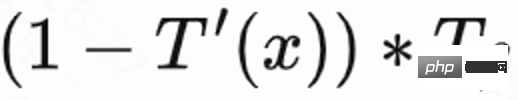 ; Finally, use the actual return visit time/estimated return visit time lower bound as the regularized return visit reward.
; Finally, use the actual return visit time/estimated return visit time lower bound as the regularized return visit reward.
Solve the bias problem
Due to the large differences in behavioral habits of different active groups, highly active users The retention rate is high and the number of training samples is significantly larger than that of low-active users, which will cause model learning to be dominated by high-active users. To solve this problem, this work learns 2 independent strategies for different groups of high activity and low activity, and uses different data streams for training. The Actor minimizes the return visit time while maximizing the auxiliary reward. As shown in Figure 1(c), taking the high-activity group as an example, the Actor loss is:
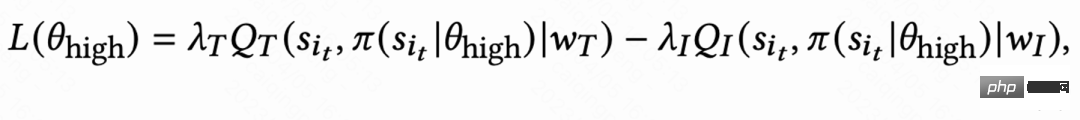
Solving the instability problem
Due to the signal delay in return visit time, Generally returns within a few hours to days, which can lead to instability in RL online training. Directly using existing behavior cloning methods either greatly limits the learning speed or cannot guarantee stable learning. Therefore, this work proposes a new soft regularization method, that is, multiplying the actor loss by a soft regularization coefficient:
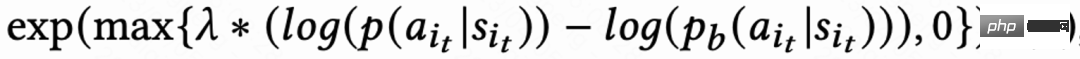
This regularization method is essentially a braking effect: if the current learning strategy and the sample strategy deviate greatly, the loss will become smaller and the learning will tend to be stable; if the learning speed tends to be stable, the loss will re- The bigger you get, the faster you learn. When  , it means there is no restriction on the learning process.
, it means there is no restriction on the learning process.
This work combines RLUR and State of the Art’s reinforcement learning algorithm TD3, as well as the black-box optimization method Cross Entropy Method (CEM) in The public data set KuaiRand is used for comparison. This work first builds a retention simulator based on the KuaiRand data set: including three modules: user immediate feedback, user leaving the session, and user return visit to the app, and then evaluating the retention simulator method.
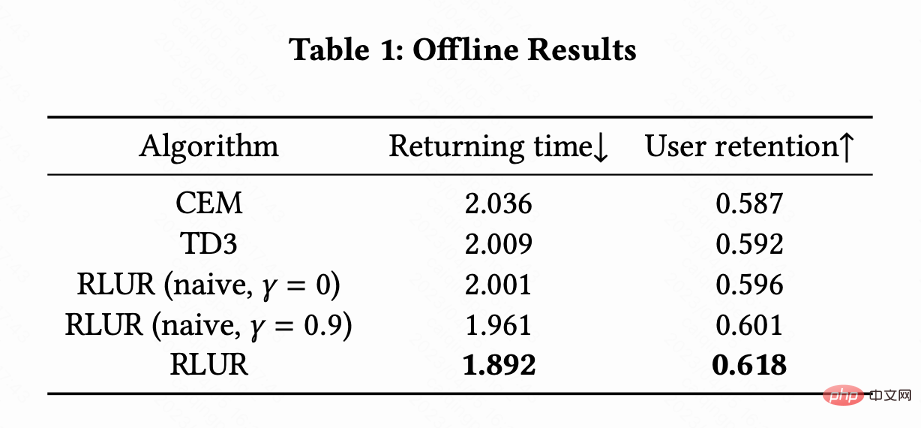
Table 1 illustrates that RLUR is significantly better than CEM and TD3 in terms of return visit time and secondary retention indicators. This study conducts ablation experiments to compare RLUR with only the retention learning part (RLUR (naive)), which can illustrate the effectiveness of this study's approach to solving retention challenges. And through the comparison of  and
and  , it is shown that the algorithm of minimizing the return visit time of multiple sessions is better than minimizing the return visit time of a single session.
, it is shown that the algorithm of minimizing the return visit time of multiple sessions is better than minimizing the return visit time of a single session.
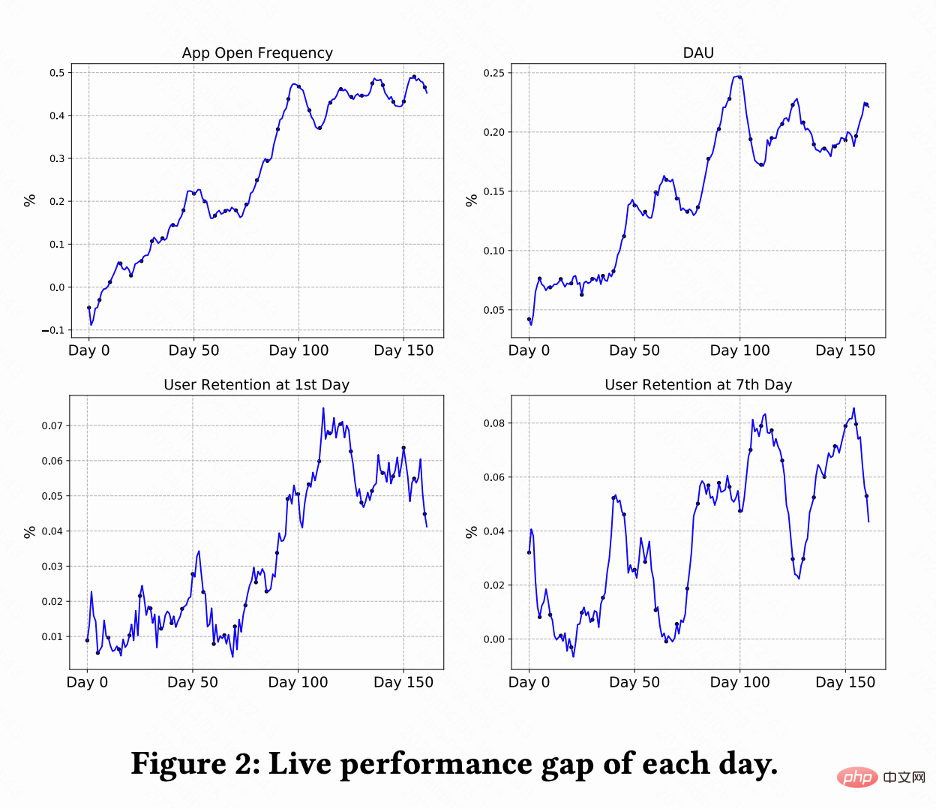
This work conducts A/B testing on the Kuaishou short video recommendation system to compare the RLUR and CEM methods . Figure 2 shows the improvement percentages of app opening frequency, DAU, first retention, and 7th retention compared to RLUR and CEM respectively. It can be found that the frequency of app opening gradually increases and even converges from 0 to 100 days. And it also drives the improvement of the second retention, 7th retention and DAU indicators (a 0.1% DAU and 0.01% improvement in second retention are considered statistically significant).
This paper studies how to improve user retention of recommendation systems through RL technology. This work models retention optimization as a Marko with infinite horizon request granularity. This work proposes the RLUR algorithm to directly optimize retention and effectively address several key challenges of retention signals. The RLUR algorithm has been fully implemented in Kuaishou App and can achieve significant secondary retention and DAU revenue. Regarding future work, how to use offline reinforcement learning, Decision Transformer and other methods to more effectively improve user retention is a promising direction.
The above is the detailed content of How to use reinforcement learning to improve Kuaishou user retention?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



