


The Image Rescaling (LR) task jointly optimizes image downsampling and upsampling operations. By reducing and restoring image resolution, it can be used to save storage space or transmission bandwidth. In practical applications, such as multi-level distribution of atlas services, low-resolution images obtained by downsampling are often subjected to lossy compression, and lossy compression often leads to a significant decrease in the performance of existing algorithms.
Recently, ByteDance-Volcano Engine Multimedia Laboratorytried for the first time to optimize image resampling performance under lossy compression and designed an asymmetric reversible Resampling framework, based on two observations under this framework, further proposes the anti-compression image resampling model SAIN. This study decouples a set of reversible network modules into two parts: resampling and compression simulation, uses a mixed Gaussian distribution to model the joint information loss caused by resolution degradation and compression distortion, and combines it with a differentiable JPEG operator for end-to-end training , which greatly improves the robustness to common compression algorithms.
Currently for image resampling research, the SOTA method is based on the Invertible Network to construct a bijective function (bijective function), and its positive operation converts the high resolution (HR) The image is converted into a low-resolution (LR) image and a series of hidden variables obeying the standard normal distribution. The inverse operation randomly samples the hidden variables and combines the LR image for upsampling restoration.
Due to the characteristics of the reversible network, the downsampling and upsampling operators maintain a high degree of symmetry, which makes it difficult for the compressed LR image to pass the originally learned upsampling. operator to restore. In order to enhance the robustness to lossy compression, this study proposes an anti-compression image resampling model SAIN (Self-AsymmetricI based on an asymmetric reversible frameworknvertibleNetwork).
The core innovations of the SAIN model are as follows:
The SAIN model has been verified for performance under JPEG and WebP compression, and its performance on multiple public data sets is significantly ahead of the SOTA model. Related research has been selected for the AAAI 2023 Oral.

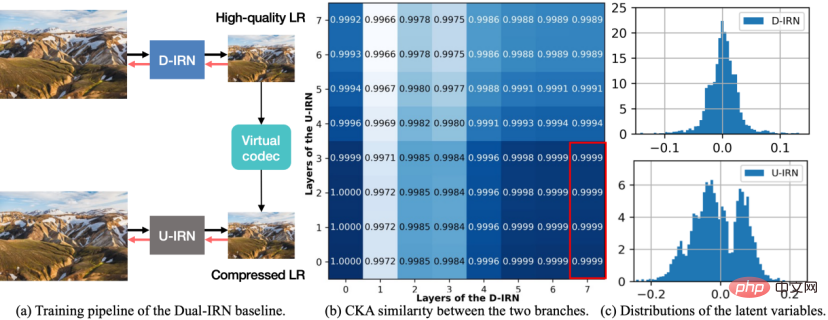
Figure 1 Dual-IRN model diagram.
In order to improve the anti-compression performance, this research first designed an asymmetric reversible image resampling framework, proposed the baseline scheme Dual-IRN model, and analyzed in depth After the shortcomings of this scheme, the SAIN model was proposed for further optimization. As shown in the figure above, the Dual-IRN model contains two branches, where D-IRN and U-IRN are two sets of reversible networks that learn the bijection between the HR image and the pre-compression/post-compression LR image respectively.
In the training phase, the Dual-IRN model passes the gradient between the two branches through the differentiable JPEG operator. In the testing phase, the model uses D-IRN to downsample to obtain high-quality LR images. After real compression in the real environment, the model then uses U-IRN with compression-aware to complete compression recovery and upsampling.
Such an asymmetric framework enables the upsampling and downsampling operators to avoid strict reversible relationships,fundamentally solves the problem caused by the compression algorithm destroying the symmetry of the upsampling and downsampling processes. The problemis that compared with SOTA's symmetrical solution, the anti-compression performance is greatly improved.
Subsequently, the researchers conducted further analysis on the Dual-IRN model and observed the following two phenomena:
Based on the above analysis, the researchers optimized the model from multiple aspects. The resulting SAIN model not only reduced the number of network parameters by nearly half, but also achieved further improvements. Performance improvements.
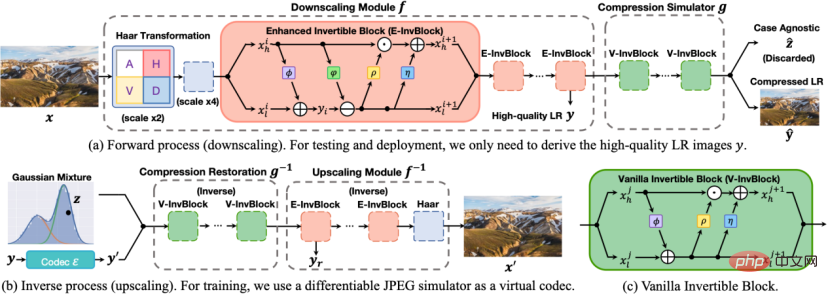
##Figure 2 SAIN model diagram.
The architecture of the SAIN model is shown in the figure above, and the following four main improvements have been made:
1. Overall framework. Based on the similarity of the middle layer features, a set of reversible network modules is decoupled into two parts: resampling and compression simulation, forming a self-asymmetric architecture to avoid using two complete sets of reversible networks. In the testing phase, use forward transformation
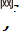
to obtain high-quality LR images, and first use inverse transformation
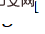
Perform compression recovery, and then use inverse transformation
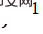
for upsampling.
#2. Network structure. E-InvBlock is proposed based on the assumption that compression loss can be recovered with the help of high-frequency information. An additive transformation is added to the module, so that two sets of LR images before and after compression can be efficiently modeled while sharing a large number of operations.
3. Information loss modeling. Based on the true distribution of latent variables, it is proposed to use the learnable mixed Gaussian distribution to model the joint information loss caused by downsampling and lossy compression, and optimize the distribution parameters end-to-end through re-parameterization techniques.
4. Objective function. Multiple loss functions are designed to constrain the reversibility of the network and improve reconstruction accuracy. At the same time, real compression operations are introduced into the loss function to enhance the robustness to real compression schemes.
Experiment and Effect EvaluationThe evaluation data set is the DIV2K verification set and the four standard test sets Set5, Set14, BSD100 and Urban100.
The quantitative evaluation indicators are:
In the comparative experiments in Table 1 and Figure 3, SAIN’s PSNR and SSIM scores on all data sets are significantly ahead of SOTA’s image resampling model. At relatively low QF, existing methods generally experience severe performance degradation, while theSAIN model still maintains optimal performance.
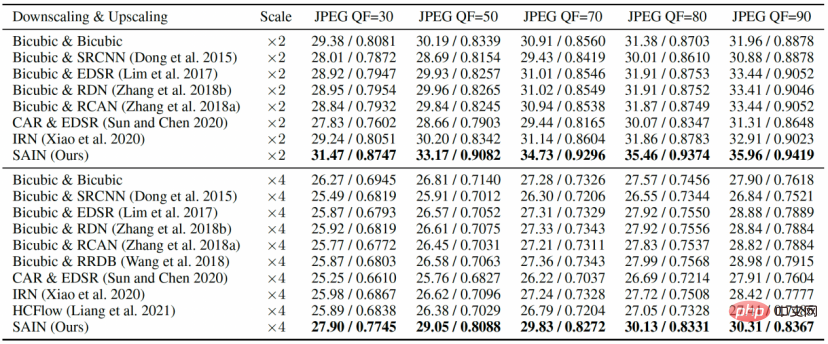
Table 1 Comparative experiment, comparing different JPEG compression qualities (QF) on the DIV2K data set Reconstruction quality (PSNR/SSIM).
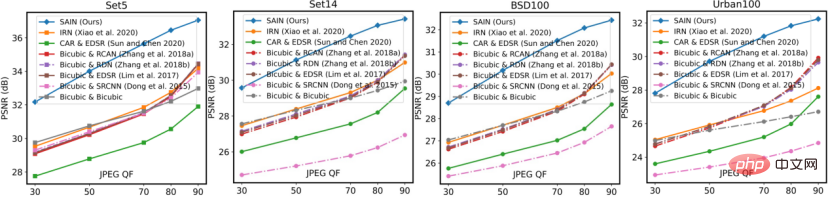
Figure 3 Comparative experiment, comparing different JPEG QF on four standard test sets reconstruction quality (PSNR).
In the visualization results in Figure 4, it can be clearly seen that the HR image restored by SAIN isclearer and more accurate.

Figure 4 Comparison of visualization results of different methods under JPEG compression (×4 magnification).
In the ablation experiments in Table 2, the researchers also compared several other candidates for training combined with real compression. These candidates are more resistant to compression than the fully symmetric existing model (IRN), but are still inferior to the SAIN model in terms of number of parameters and accuracy.
Table 2 Ablation experiments for the overall framework and training strategy.
In the visualization results in Figure 5, the researchers compared the reconstruction results of different image resampling models under WebP compression distortion. It can be found that the SAIN model also shows the highest reconstruction score under the WebP compression scheme and can clearly and accurately restore image details, provingSAIN's compatibility with different compression schemes.
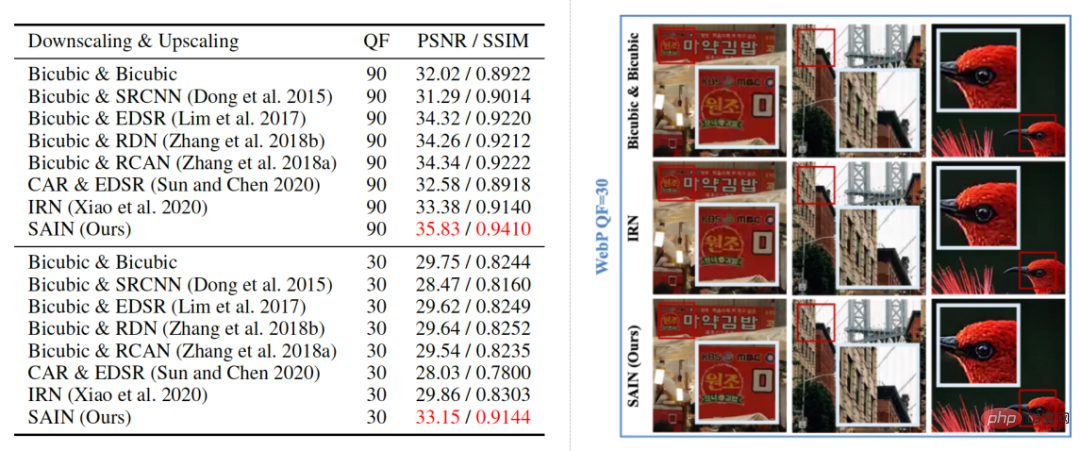
Figure 5 Qualitative and quantitative comparison of different methods under WebP compression (×2 magnification).
In addition, this study also conducted ablation experiments on the mixed Gaussian distribution, E-InvBlock and loss function, proving that these improvements have a positive impact on the results. contribute.
Volcano Engine Multimedia Laboratory proposed a model based on an asymmetric reversible framework for anti-compression image resampling: SAIN. The model consists of two parts: resampling and compression simulation. It uses a mixed Gaussian distribution to model the joint information loss caused by resolution reduction and compression distortion. It is combined with a differentiable JPEG operator for end-to-end training, and E-InvBlock is proposed to enhance the model. The fitting ability greatly improves the robustness to common compression algorithms.
The Volcano Engine Multimedia Laboratory is a research team under ByteDance. It is committed to exploring cutting-edge technologies in the multimedia field and participating in international standardization work. Its many innovative algorithms and software and hardware solutions have been widely used in Douyin, Douyin, etc. Multimedia business for Xigua Video and other products, and provides technical services to enterprise-level customers of Volcano Engine. Since the establishment of the laboratory, many papers have been selected into top international conferences and flagship journals, and have won several international technical competition championships, industry innovation awards and best paper awards.
In the future, the research team will continue to optimize the performance of the image resampling model under lossy compression, and further explore more complex application scenarios such as anti-compression video resampling and arbitrary magnification resampling. .
The above is the detailed content of Byte proposes an asymmetric image resampling model, with anti-compression performance leading SOTA on JPEG and WebP. For more information, please follow other related articles on the PHP Chinese website!
 Introduction to the framework used by vscode
Introduction to the framework used by vscode python environment variable configuration
python environment variable configuration What is fil coin?
What is fil coin? Where should I fill in my place of birth: province, city or county?
Where should I fill in my place of birth: province, city or county? Usage of DWZ framework
Usage of DWZ framework How to export excel files from Kingsoft Documents
How to export excel files from Kingsoft Documents How to open dwg file
How to open dwg file How to use the length function in Matlab
How to use the length function in Matlab




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



