


With the popularity of the concept of digital people and the continuous development of generation technology, it is no longer a problem to make the characters in the photos move according to the audio input.
However, there are still many problems in "generating a talking avatar video through face images and a piece of voice audio", such as unnatural head movements and distorted facial expressions , the faces of the people in the videos and pictures are too different and other issues.
Recently, researchers from Xi'an Jiaotong University and others proposed the SadTalker model, which learns in a three-dimensional sports field to generate 3D motion coefficients of 3DMM (head) from audio. poses, expressions), and uses a new 3D facial renderer to generate head movements.

Paper link: https://arxiv.org/pdf/2211.12194.pdf
Project homepage: https://sadtalker.github.io/
Audio can be English, Chinese, songs , the characters in the video can also control the blinking frequency!
To learn realistic motion coefficients, the researchers explicitly model the connection between audio and different types of motion coefficients separately: through distilled coefficients and 3D-rendered faces , learn accurate facial expressions from audio; design PoseVAE through conditional VAE to synthesize different styles of head movements.
Finally, the generated three-dimensional motion coefficients are mapped to the unsupervised three-dimensional key point space of face rendering, and the final video is synthesized.
Finally, it was demonstrated in experiments that this method achieves state-of-the-art performance in terms of motion synchronization and video quality.
The current stable-diffusion-webui plug-in has also been released!
Many fields such as digital human creation and video conferencing require the technology of "using voice audio to animate still photos", but currently That's still a very challenging task.
Previous work has mainly focused on generating "lip movements" because the relationship between lip movements and speech is the strongest. Other work is also trying to generate other related movements (such as head movements). facial poses), but the quality of the resulting videos is still very unnatural and limited by preferred poses, blurring, identity modification, and facial distortion.
Another popular method is latent-based facial animation, which mainly focuses on specific categories of motion in conversational facial animation. It is also difficult to synthesize high-quality videos because Although the 3D facial model contains highly decoupled representations that can be used to independently learn the motion trajectories of different positions on the face, inaccurate expressions and unnatural motion sequences will still be generated.
Based on the above observations, researchers proposed SadTalker (Stylized Audio-Driven Talking-head), a stylized audio-driven video generation system through implicit three-dimensional coefficient modulation.
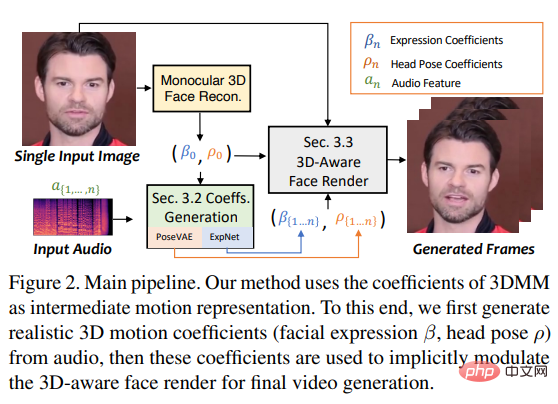
# To achieve this goal, the researchers treated the motion coefficients of 3DMM as intermediate representations and divided the task into The two main parts (expressions and poses) aim to generate more realistic motion coefficients (such as head poses, lip movements, and eye blinks) from audio, and learn each motion individually to reduce uncertainty.
Finally drives the source image through a 3D-aware face rendering inspired by face-vid2vid.
3D Face
Because real-life videos are shot in a three-dimensional environment, three-dimensional information is crucial to improve the authenticity of the generated video; however, previous work rarely considered three-dimensional space, because only one plane was used. It is difficult to obtain original three-dimensional sparse images, and high-quality facial renderers are difficult to design.
Inspired by recent single-image depth 3D reconstruction methods, the researchers used the space of predicted three-dimensional deformation models (3DMMs) as intermediate representations.
In 3DMM, the three-dimensional face shape S can be decoupled as:
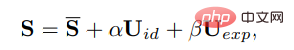
where S is the average shape of the three-dimensional human face, Uid and Uexp are the regularizations of the identity and expression of the LSFM morphable model. The coefficients α (80 dimensions) and β (64 dimensions) describe the identity and expression of the character respectively; in order to maintain the difference in posture, the coefficient r and t represent head rotation and translation respectively; in order to achieve identity-independent coefficient generation, only the parameters of the motion are modeled as {β, r, t}.
That is, the head pose ρ = [r, t] and expression coefficient β are learned separately from the driven audio, and then these motion coefficients are used to implicitly modulate facial rendering for Final video synthesis.
Motion sparse generation through audio
The three-dimensional motion coefficient contains head pose and expression, where the head pose is Global motion, while expressions are relatively local, so fully learning all coefficients will bring huge uncertainty to the network, because the relationship between head posture and audio is relatively weak, while the movement of lips is highly correlated with audio. .
So SadTalker uses the following PoseVAE and ExpNet to generate the movement of head posture and expression respectively.
ExpNet
It is very useful to learn a general model that can "generate accurate expression coefficients from audio" Difficult for two reasons:
1) Audio-to-expression is not a one-to-one mapping task for different characters;
2) There are some audio-related actions in the expression coefficient, which will affect the accuracy of prediction.
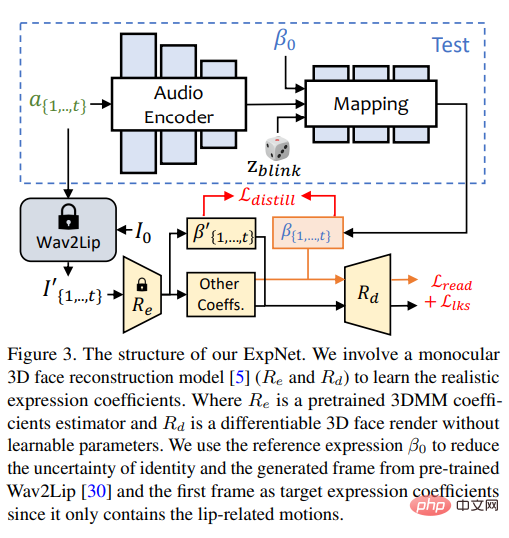
The design goal of ExpNet is to reduce these uncertainties; as for the character identity problem, the researchers moved the expression through the expression coefficient of the first frame associated with a specific person.
In order to reduce the motion weight of other facial components in natural conversations, only lip motion coefficients (lip motion only) are used as coefficient targets through the pre-trained network of Wav2Lip and deep 3D reconstruction.
As for other subtle facial movements (such as eye blinks), etc., they can be introduced in the additional landmark loss on the rendered image.
PoseVAE
Researchers designed a VAE-based model to learn real, identity-related images in conversation videos (identity-aware) stylized head movements.
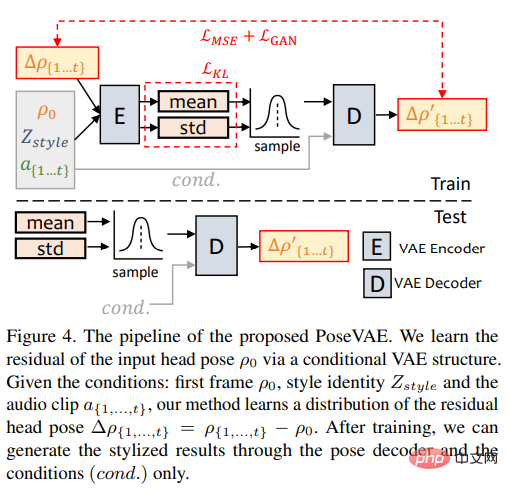
#In training, pose VAE is trained on fixed n frames using an encoder-decoder based structure. , where the encoder and decoder are both two-layer MLPs, and the input contains a continuous t-frame head pose, which is embedded into a Gaussian distribution; in the decoder, the network learns to generate t-frame poses from the sampling distribution.
It should be noted that PoseVAE does not directly generate poses, but learns the residual of the conditional pose of the first frame, which also allows this method to generate longer lengths under the conditions of the first frame in the test. , more stable and continuous head movement.
According to CVAE, corresponding audio features and style identifiers are also added to PoseVAE as conditions for rhythm awareness and identity style.
The model uses KL divergence to measure the distribution of generated motion; it uses mean square loss and adversarial loss to ensure the quality of generation.
3D-aware facial rendering
After generating realistic three-dimensional motion coefficients, the researchers passed a carefully designed 3D image animator to render the final video.
The recently proposed image animation method face-vid2vid can implicitly learn 3D information from a single image, but this method requires a real video as an action driving signal; and this paper The face rendering proposed in can be driven by 3DMM coefficients.
The researchers proposed mappingNet to learn the relationship between explicit 3DMM motion coefficients (head pose and expression) and implicit unsupervised 3D keypoints.
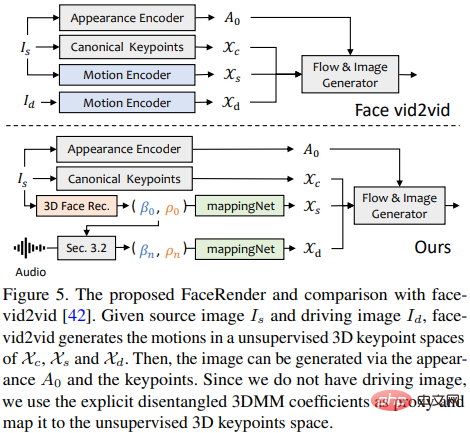
mappingNet is built through several one-dimensional convolutional layers, and uses the time coefficient of the time window for smoothing like PIRenderer; the difference is that the research The researchers found that the face-aligned motion coefficients in PIRenderer will greatly affect the naturalness of motion in audio-driven video generation, so mappingNet only uses coefficients for expressions and head poses.
The training phase consists of two steps: first follow the original paper and train face-vid2vid in a self-supervised manner; then freeze the appearance encoder, canonical keypoint estimator and image generator After all parameters, mappingNet is trained on the 3DMM coefficients of the ground truth video in a reconstructed manner for fine-tuning.
Uses L1 loss for supervised training in the domain of unsupervised keypoints, and gives the final generated video as per its original implementation.
In order to prove the superiority of this method, the researchers selected the Frechet Inception Distance (FID) and Cumulative Probability Blur Detection (CPBD) indicators to evaluate the image The quality, where FID mainly evaluates the authenticity of the generated frames, and CPBD evaluates the clarity of the generated frames.
To evaluate the degree of identity preservation, ArcFace is used to extract the identity embedding of the image, and then the cosine similarity (CSIM) of the identity embedding between the source image and the generated frame is calculated.
To evaluate lip synchronization and lip shape, researchers evaluated the perceptual differences of lip shapes from Wav2Lip, including distance score (LSE-D) and confidence score (LSE-C) .
In the evaluation of head motion, the diversity of generated head motions is calculated using the standard deviation of the head motion feature embeddings extracted by Hopenet from the generated frames; Beat Align is calculated Score to evaluate the consistency of audio and generated head movements.
In the comparison method, several of the most advanced talking avatar generation methods were selected, including MakeItTalk, Audio2Head and audio-to-expression generation methods (Wav2Lip, PC-AVS), using public Checkpoint weights are evaluated.
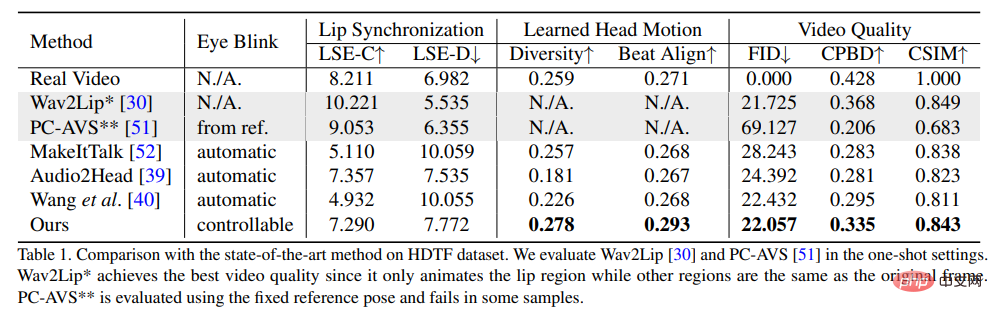
It can be seen from the experimental results that the method proposed in the article can show better overall video quality and header. diversity of head poses, while also showing comparable performance to other fully speaking head generation methods in terms of lip synchronization metrics.
The researchers believe that these lip sync metrics are too sensitive to audio, so that unnatural lip movements may get better scores, but the method proposed in the article achieved The similar scores to real videos also demonstrate the advantages of this method.

As can be seen in the visual results generated by the different methods, the visual quality of this method is very similar to the original target video, and different from the expected The posture is also very similar.
Compared with other methods, Wav2Lip generates blurry half-faces; PC-AVS and Audio2Head have difficulty retaining the identity of the source image; Audio2Head can only generate frontal speaking faces; MakeItTalk and Audio2Head generates distorted face videos due to 2D distortion.
The above is the detailed content of Pictures + audios turn into videos in seconds! Xi'an Jiaotong University's open source SadTalker: supernatural head and lip movements, bilingual in Chinese and English, and can also sing. For more information, please follow other related articles on the PHP Chinese website!
 How to insert audio into ppt
How to insert audio into ppt
 How to modify the text in the picture
How to modify the text in the picture
 What to do if the embedded image is not displayed completely
What to do if the embedded image is not displayed completely
 Java-based audio processing methods and practices
Java-based audio processing methods and practices
 How to make ppt pictures appear one by one
How to make ppt pictures appear one by one
 How to make a round picture in ppt
How to make a round picture in ppt
 How to use debug.exe
How to use debug.exe
 Baidu keyword optimization software
Baidu keyword optimization software








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



