


ICLR (International Conference on Learning Representations) is recognized as one of the most influential international academic conferences on machine learning.
At this year's ICLR 2023 conference, Microsoft Research Asia published the latest research results in areas such as machine learning robustness and responsible artificial intelligence.
Among them, the scientific research cooperation results between Microsoft Research Asia and the Korea Advanced Institute of Science and Technology (KAIST) under the framework of academic cooperation between the two parties have been recognized for their outstanding clarity, insight, creativity and potential. The lasting impact was awarded the ICLR 2023 Outstanding Paper Award.

##Paper address: https://arxiv.org/abs/2303.14969
VTM: the first few-shot learner adapted to all dense prediction tasksDense prediction tasks are an important class of tasks in the field of computer vision, such as semantic segmentation, depth estimation, edge detection and key point detection wait. For such tasks, manual annotation of pixel-level labels faces prohibitively high costs. Therefore, how to learn from a small amount of labeled data and make accurate predictions, that is, small sample learning, is a topic of great concern in this field. In recent years, research on small sample learning has continued to make breakthroughs, especially some methods based on meta-learning and adversarial learning, which have attracted much attention and welcome from the academic community.
However, existing computer vision small sample learning methods are generally aimed at a specific type of task, such as classification tasks or semantic segmentation tasks. They often exploit prior knowledge and assumptions specific to these tasks in designing the model architecture and training process, and are therefore not suitable for generalization to arbitrary dense prediction tasks. Researchers at Microsoft Research Asia wanted to explore a core question: whether there is a general few-shot learner that can learn dense prediction tasks for arbitrary segments of unseen images from a small number of labeled images.
The goal of a dense prediction task is to learn a mapping from input images to labels annotated in pixels, which can be defined as:
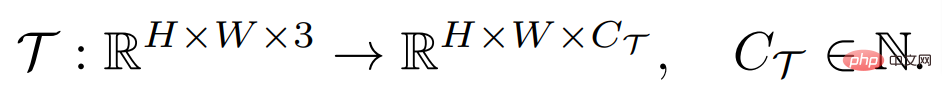
where H and W are the height and width of the image respectively. The input image generally contains three RGB channels, and C_Τ represents the number of output channels. Different dense prediction tasks may involve different output channel numbers and channel attributes. For example, the output of a semantic segmentation task is multi-channel binary, while the output of a depth estimation task is a single-channel continuous value. A general few-sample learner F, for any such task Τ, given a small number of labeled sample support sets S_Τ (including N groups of samples X^i and labels Y^i), can learn for unseen Querying the image Expectations:
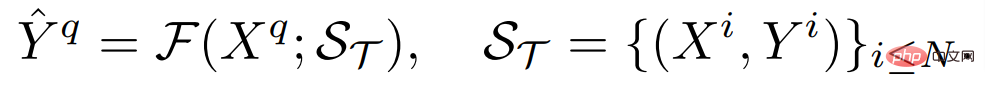 First, it must have a unified architecture. This structure is capable of handling arbitrarily dense prediction tasks and shares the parameters required for most tasks in order to obtain generalizable knowledge, enabling learning of any unseen task with a small number of samples.
First, it must have a unified architecture. This structure is capable of handling arbitrarily dense prediction tasks and shares the parameters required for most tasks in order to obtain generalizable knowledge, enabling learning of any unseen task with a small number of samples.
Second, the learner should flexibly adjust its prediction mechanism to solve unseen tasks with various semantics while being efficient enough to prevent overfitting.
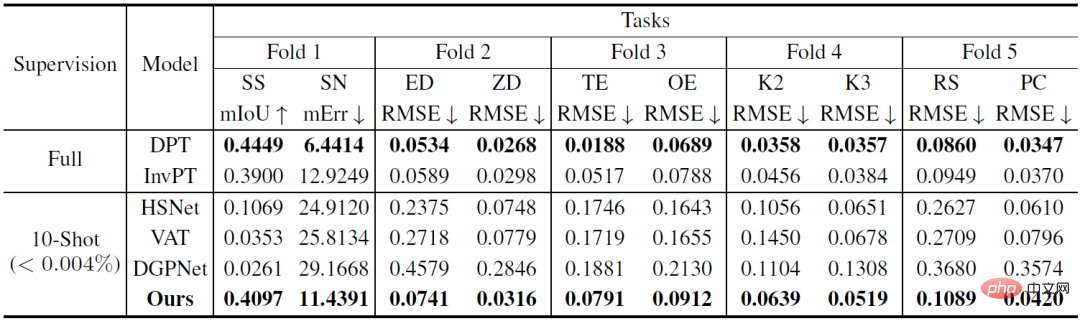
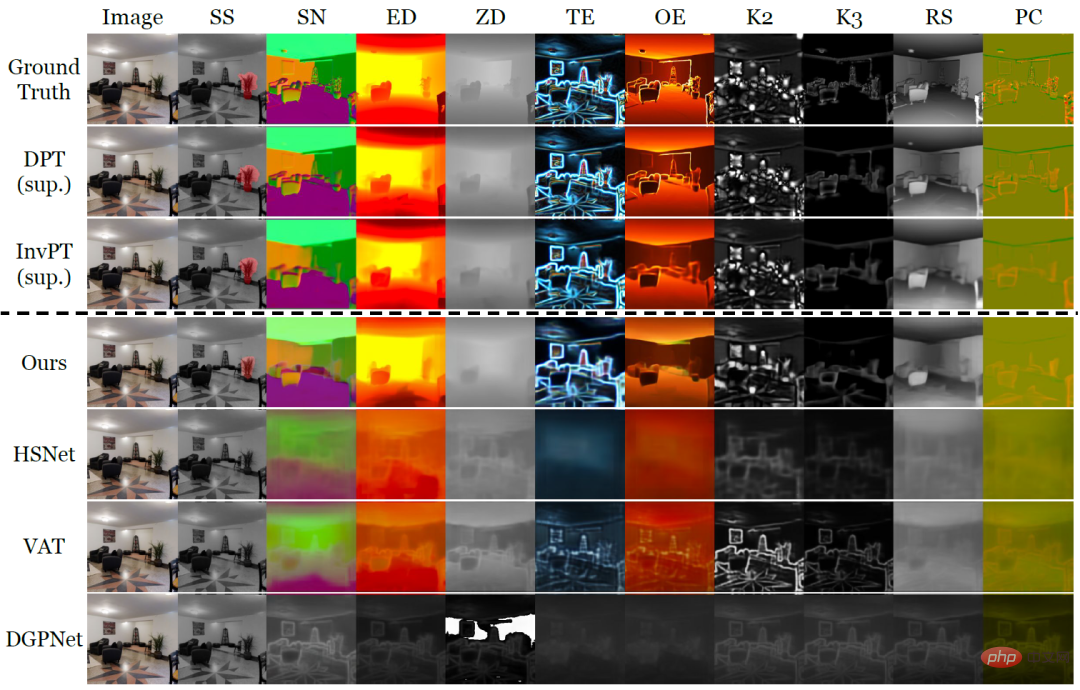
The design of VTM is inspired by analogy to the human thinking process: given a small number of examples of a new task, humans can quickly assign similar outputs to similar inputs based on the similarity between the examples, and can also Flexibly adapt the levels at which inputs and outputs are similar based on a given context. The researchers implemented an analogy process for dense prediction using non-parametric matching based on patch levels. Through training, the model is inspired to capture similarities in image patches. Given a small number of labeled examples for a new task, VTM first adjusts its understanding of similarity based on the given example and the label of the example, locking in the example image patch with the to-be- Predict similar image patches and predict the labels of unseen image patches by combining their labels. Figure 1: Overall architecture of VTM VTM adopts layering The encoder-decoder architecture implements patch-based non-parametric matching at multiple levels. It mainly consists of four modules, namely image encoder f_Τ, label encoder g, matching module and label decoder h. Given a query image and a support set, the image encoder first extracts image patch-level representations for each query and support image independently. The tag encoder will similarly extract each tag that supports tags. Given the labels at each level, the matching module performs non-parametric matching, and the label decoder finally infers the label of the query image. The essence of VTM is a meta-learning method. Its training consists of multiple episodes, each episode simulates a small sample learning problem. VTM training uses the meta-training dataset D_train, which contains a variety of labeled examples of dense prediction tasks. Each training episode simulates a few-shot learning scenario for a specific task T_train in the dataset, with the goal of producing the correct label for the query image given the support set. Through the experience of learning from multiple small samples, the model can learn general knowledge to adapt to new tasks quickly and flexibly. At test time, the model needs to perform few-shot learning on any task T_test that is not included in the training data set D_train. When dealing with arbitrary tasks, since the output dimension C_Τ of each task in meta-training and testing is different, it becomes a huge challenge to design unified general model parameters for all tasks. To provide a simple and general solution, the researchers transformed the task into C_Τ single-channel subtasks, learned each channel separately, and modeled each subtask independently using a shared model F. To test VTM, the researchers also specially constructed a variant of the Taskonomy data set to simulate small-shot learning of unseen dense prediction tasks. Taskonomy contains a variety of annotated indoor images, from which the researchers selected ten dense prediction tasks with different semantics and output dimensions and divided them into five parts for cross-validation. In each split, two tasks are used for small-shot evaluation (T_test) and the remaining eight tasks are used for training (T_train). The researchers carefully constructed the partitions so that the training and test tasks were sufficiently different from each other, such as grouping edge tasks (TE, OE) into test tasks to allow for the evaluation of tasks with new semantics. Table 1: Quantitative comparison on the Taskonomy dataset (Few-shot baseline after training tasks from other partitions) 10-shot learning was performed on the partitioned task to be tested, where the fully supervised baseline was trained and evaluated on each fold (DPT) or all folds (InvPT)) Table 1 and Figure 2 quantitatively and qualitatively demonstrate the small-sample learning performance of VTM and the two types of baseline models on ten intensive prediction tasks respectively. Among them, DPT and InvPT are the two most advanced supervised learning methods. DPT can be trained independently for each single task, while InvPT can jointly train all tasks. Since there was no dedicated small-sample method developed for general dense prediction tasks before VTM, the researchers compared VTM with three state-of-the-art small-sample segmentation methods, namely DGPNet, HSNet and VAT, and extended them to handle A general label space for dense prediction tasks. VTM did not have access to the test task T_test during training and only used a small number (10) of labeled images at test time, but it performed best among all small-shot baseline models and performed well on many tasks. Competitiveness compared to fully supervised baseline models. Figure 2: A small sample of only ten labeled images on the new task out of Taskonomy’s ten intensive prediction tasks A qualitative comparison of learning methods. Where other methods failed, VTM successfully learned all new tasks with different semantics and different label representations. In Figure 2, above the dotted line are the real labels and the two supervised learning methods DPT and InvPT respectively. Below the dotted line is the small sample learning method. Notably, other small-sample baselines suffered from catastrophic underfitting on new tasks, while VTM successfully learned all tasks. Experiments demonstrate that VTM can now perform similarly competitively with fully supervised baselines on a very small number of labeled examples ( In summary, although the underlying idea of VTM is very simple, it has a unified architecture and can be used for any dense prediction task, because the matching algorithm is essentially Contains all tasks and label structures (e.g., continuous or discrete). In addition, VTM only introduces a small number of task-specific parameters, allowing it to be resistant to overfitting and flexible. In the future, researchers hope to further explore the impact of task type, data volume, and data distribution on model generalization performance during the pre-training process, thereby helping us build a truly universal small-sample learner. 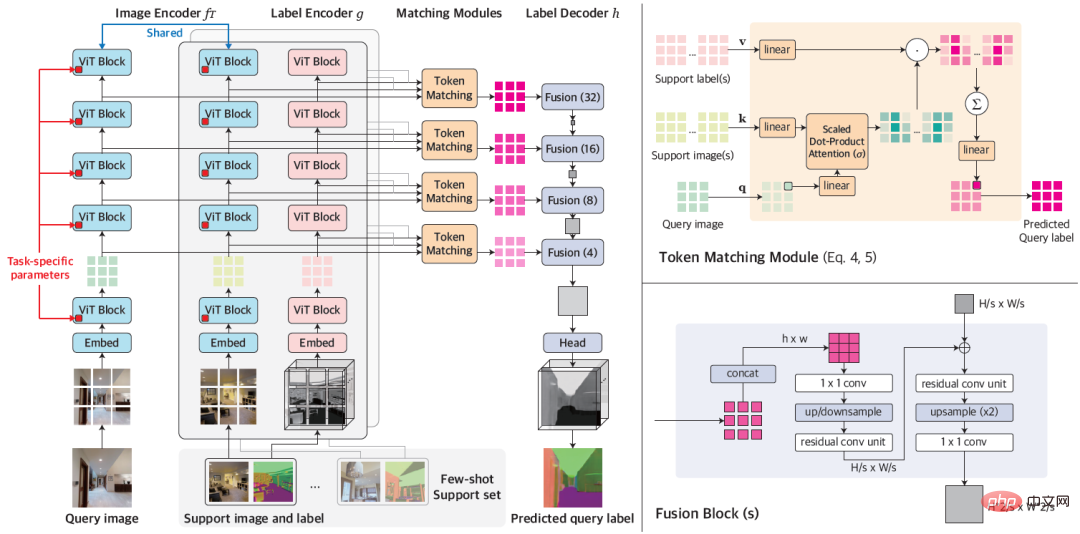
The above is the detailed content of Universal few-shot learner: a solution for a wide range of dense prediction tasks. For more information, please follow other related articles on the PHP Chinese website!
 Computer Languages
Computer Languages
 Computer application areas
Computer application areas
 What is the encoding used inside a computer to process data and instructions?
What is the encoding used inside a computer to process data and instructions?
 The main reason why computers use binary
The main reason why computers use binary
 What are the main characteristics of computers?
What are the main characteristics of computers?
 What are the basic components of a computer?
What are the basic components of a computer?
 What keys do arrows refer to in computers?
What keys do arrows refer to in computers?
 How to recover browser history on computer
How to recover browser history on computer








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



