Optimize the splicing performance of Ctrip's transfer transportation plan
WBOY
Release: 2023-04-25 18:31:09
forward
1336 people have browsed it
About the author
In short, Ctrip back-end development manager, focusing on technical architecture, performance optimization, transportation planning and other fields.
1. Background introduction
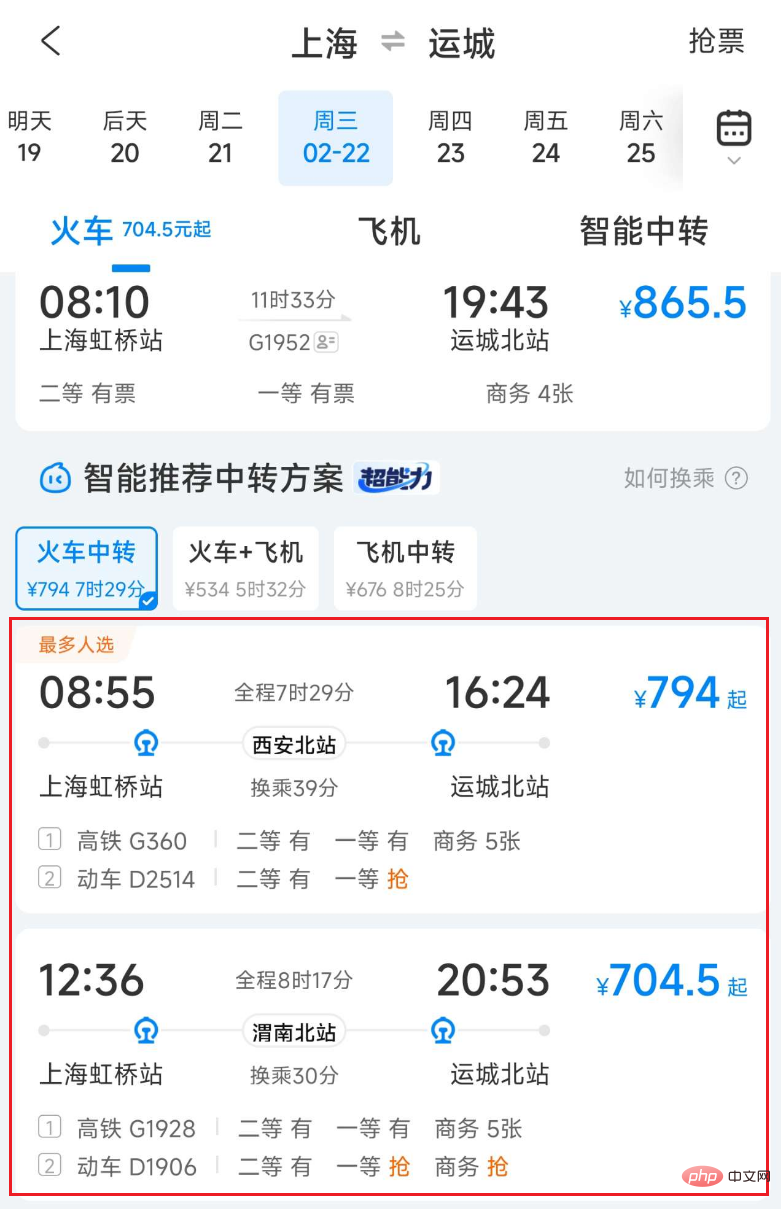
Due to the limitations of transportation planning and transportation capacity resources, there may be no direct transportation between the two places queried by the user, or during major holidays, direct transportationare all sold out. However, users can still reach their destination through two-way or multi-way transfers such as trains, planes, cars, ships, etc. In addition, transfer transportation is sometimes more advantageous in terms of price and time consumption. For example, from Shanghai to Yuncheng, connecting via train may be faster and cheaper than a direct train.
Figure 1 Ctrip train transfer transportation list
When providing transfer transportation solutions, it is very important One link is to stitch together two or more journeys of trains, planes, cars, ships, etc. to form a feasible transfer plan. The first difficulty in splicing transit traffic is that the splicing space is huge. Just considering Shanghai as a transit city, nearly 100 million combinations can be generated. Another difficulty lies in the requirement of real-time performance, because the production line data changes at any time and needs to be constantly updated. Query data on trains, planes, cars, and ships. Transit traffic splicing requires a lot of computing resources and IO overhead, so optimizing its performance is particularly important.
This article will combine examples to introduce the principles, analysis and optimization methods followed in the process of optimizing the performance of transfer traffic splicing, aiming to provide readers with valuable reference and inspiration.
2. Optimization Principles
Performance optimization requires balancing and making trade-offs among various resources and constraints on the premise of meeting business needs, and following some major principles Helps eliminate uncertainty and approach the optimal solution to the problem. Specifically, the following three principles are mainly followed in the transfer traffic splicing optimization process:
2.1 Performance optimization is a means rather than an end
Although this article is about performance optimization , but it still needs to be emphasized at the beginning: don’t optimize for the sake of optimization. There are many ways to meet business needs, and performance optimization is just one of them. Sometimes the problem is very complex and there are many restrictions. Without significantly affecting the user experience, reducing the impact on users by relaxing restrictions or adopting other processes is also a good way to solve performance problems. In software development, there are many examples of significant cost reductions achieved by sacrificing a small amount of performance. For example, the HyperLogLog algorithm used for cardinality statistics (duplication removal) in Redis can count 264 data in only 12K space with a standard error of 0.81%.
Back to the problem itself, since production line data needs to be queried frequently and massive splicing operations are performed, if each user is required to immediately return the freshest transfer plan when querying, The cost will be very high. To reduce costs, a balance needs to be struck between response time and data freshness. After careful consideration, we choose to accept minute-level data inconsistencies. For some unpopular routes and dates, there may not be a good transfer plan when querying for the first time. In this case, just guide the user to refresh the page.
2.2 Incorrect optimization is the root of all evil
Donald Knuth mentioned in "Structured Programming With Go To Statements": "Programmers waste a lot of time Thinking and worrying about the performance of non-critical paths and trying to optimize this part of performance will have a very serious negative impact on the debugging and maintenance of the overall code, so in 97% of cases, we should forget small optimization points." In short, before the real performance problem is discovered, excessive and ostentatious optimization at the code level will not only not improve performance, but may lead to more errors. However, the author also emphasized: "For the remaining critical 3%, we should not miss the opportunity to optimize." Therefore, you need to always pay attention to performance issues, not make decisions that will affect performance, and make correct optimizations when necessary.
2.3 Quantitatively analyze performance and clarify the direction of optimization
As mentioned in the previous section, before optimizing, you must first quantify the performance and identify bottlenecks, so that the optimization can be more targeted. Quantitative analysis of performance can use time-consuming monitoring, Profiler performance analysis tools, Benchmark benchmark testing tools, etc., focusing on areas that take a particularly long time or have a particularly high execution frequency. As Amdahl's law states: "The degree of system performance improvement that can be obtained by using a faster execution method for a certain component in the system depends on the frequency with which this execution method is used, or the proportion of the total execution time."
In addition, it is also important to note that performance optimization is a protracted battle. As the business continues to develop, the architecture and code are constantly changing, so it is even more necessary to continuously quantify performance, continuously analyze bottlenecks, and evaluate optimization effects.
3. The road to performance analysis
3.1 Sort out the business process
Before performance analysis, we must first sort out the business process. The splicing of transfer transportation plans mainly includes the following four steps:
#a. Load the route map, such as Beijing to Shanghai via Nanjing transfer, only the information of the route itself is considered, and has nothing to do with the specific flight;
b. Check the production line data of trains, planes, cars and ships, including departure time, arrival time, departure station, arrival station, price and remaining ticket information, etc.;
c. To stitch together all feasible transfer transportation options, the main consideration is that the transfer time should not be too short to avoid being unable to complete the transfer; at the same time, it should not be too long to avoid waiting too long. After splicing out feasible solutions, you still need to improve the business fields, such as total price, total time taken, transfer information, etc.;
d. According to certain rules, from all the spliced out From the feasible transfer solutions, some solutions that may be of interest to users are selected.
3.2 Quantitative analysis performance
(1) Increase time-consuming monitoring
Time-consuming Monitoring is the most intuitive way to observe the time-consuming situation of each stage from a macro perspective. It can not only view the time-consuming value and proportion of time-consuming at each stage of the business process, but also observe the time-consuming change trend over a long period of time.
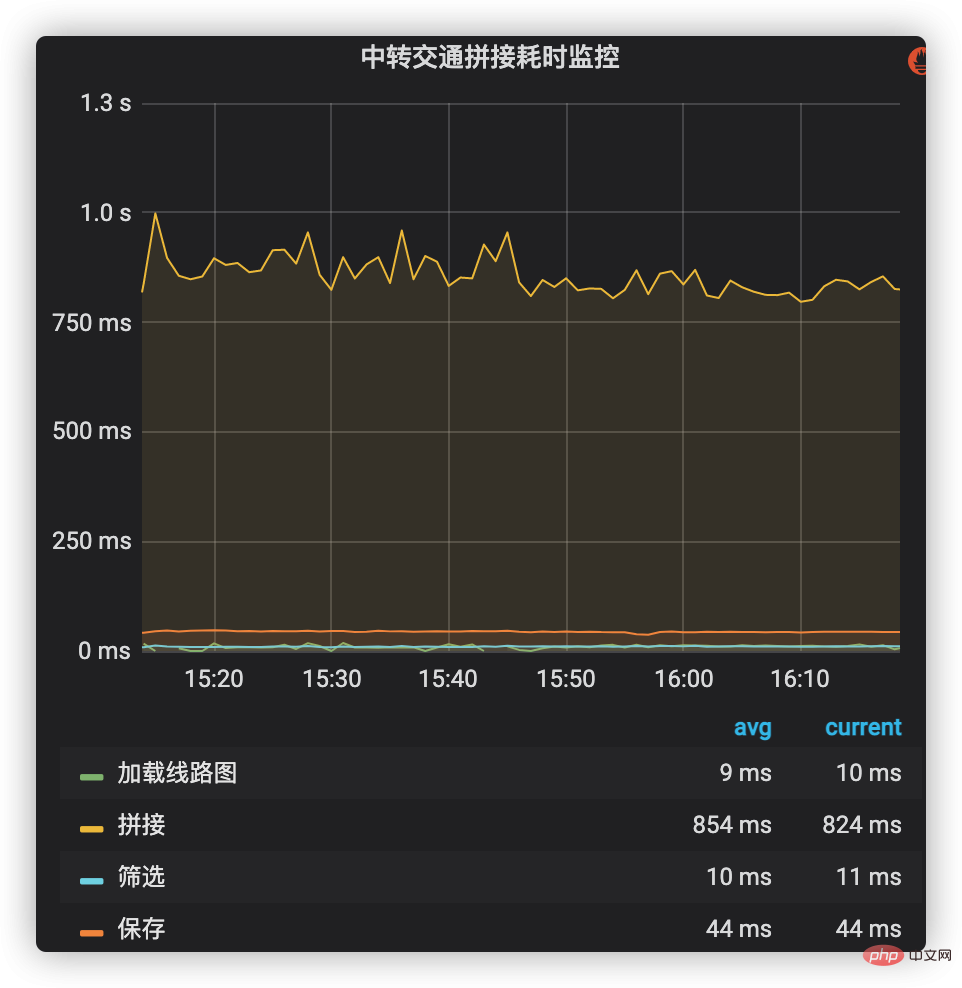
Time-consuming monitoring can use the company’s internal indicator monitoring and alarm system to add time-consuming management to the main process of connecting transit transportation solutions. These processes include loading route maps, querying shift data and splicing it, filtering and saving splicing plans, etc. The time-consuming situation of each stage is shown in Figure 2. It can be seen that splicing (including production line data) takes the highest proportion of time-consuming, so it has become a key optimization target in the future.
Figure 2 Time-consuming monitoring of transit traffic splicing
(2) Profiler performance analysis
Time-consuming management may invade business code and affect performance, so it should not be too many and is more suitable for monitoring main processes. The corresponding Profiler performance analysis tool (such as Async-profiler) can generate a more specific call tree and the CPU usage ratio of each function, thereby helping to analyze and locate critical paths and performance bottlenecks.
Figure 3 Splicing call tree and CPU ratio
As shown in Figure 3, the splicing scheme (combineTransferLines) accounts for 53.80%, and query production line data (querySegmentCacheable, cache used) accounts for 21.45%. In the splicing scheme, calculating scheme score (computeTripScore, accounting for 48.22%), creating scheme entity (buildTripBO, accounting for 4.61%) and checking splicing feasibility (checkCombineMatchCondition, accounting for 0.91%) are the three largest links.
Figure 4 Solution scoring call tree and CPU ratio
When we continued to analyze the calculation plan score (computeTripScore) with the highest proportion, we found that it was mainly related to the custom string formatting function (StringUtils.format), including direct calls (used to display plan score details), As well as an indirect call via getTripId (used to generate the ID of the scheme). The highest proportion of customized StringUtils.format is java/lang/String.replace. Java 8’s native string replacement is implemented through regular expressions, which is relatively inefficient (this problem has been improved after Java 9).
With the help of Benchmark benchmark test tool, you can measure the performance of the code more accurately execution time. In Table 1, we use JMH (Java Microbenchmark Harness) to conduct time-consuming tests on three string formatting methods and one string splicing method. The test results show that string formatting using Java8's replace method has the worst performance, while using Apache's string splicing function has the best performance.
Table 1 Comparison of string formatting and splicing performance
##Implementation
Average time taken to execute 1000 times (us)
StringUtils.format implemented using Java8's replace
1988.982
StringUtils.format implemented using Apache replace
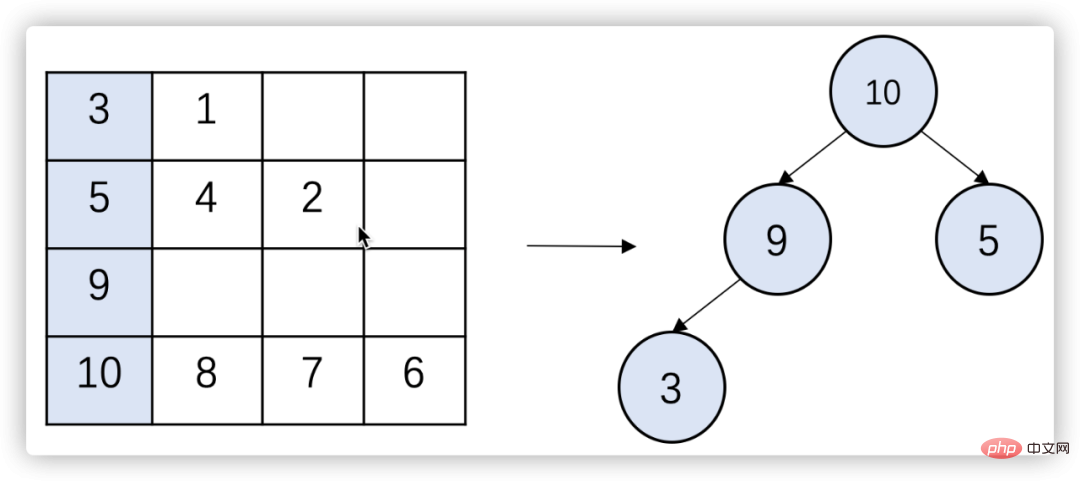
b. Take the largest element from the top of the big root heap and put it into the result set;
c. If there are remaining elements in the queue where the element is located, then Add the next element to the heap;
d. Repeat steps 2 and 3 until the result set contains K elements or all queues are empty.
Figure 7 Multi-path merge Top-K algorithm
4.2 Build multi-level cache
Caching is a typical space-for-time strategy that can cache data and calculation results. Caching data can improve access efficiency, and caching results avoids repeated calculations. While caching brings performance improvements, it also introduces new problems:
The cache capacity is limited, and the data loading, updating, invalidation and replacement strategies need to be carefully considered;
Design of cache architecture: Generally speaking, memory caches (such as HashMap, Caffeine, etc.) have the highest performance, followed by distributed caches such as Redis, RocksDB is relatively slow, and the upper limit of capacity is just the opposite. , need to be carefully selected and used together;
How to solve the cache inconsistency problem and how long the inconsistency can be accepted.
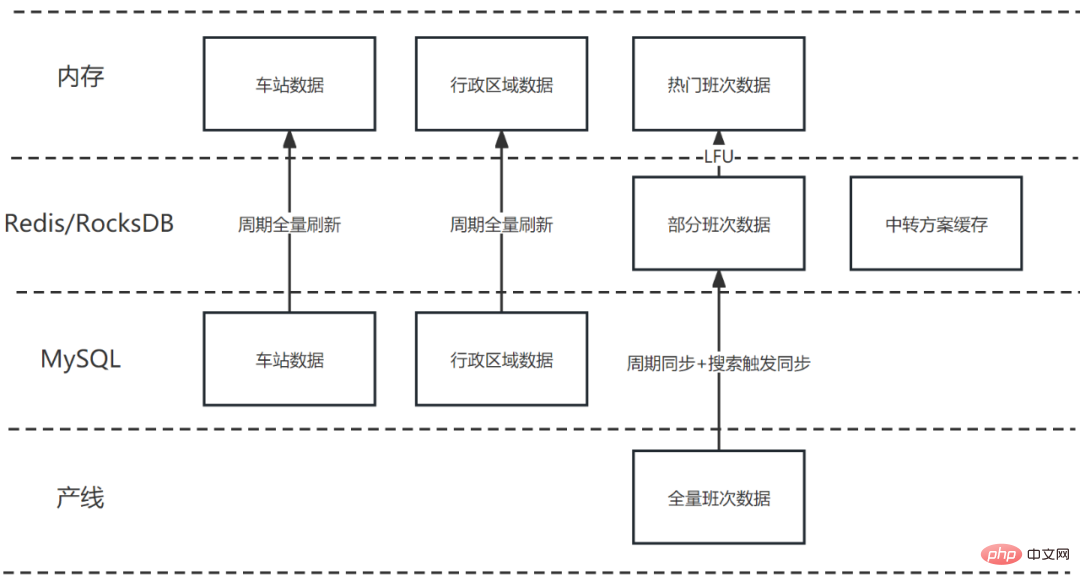
In the process of splicing transfer transportation solutions, a large amount of basic data (such as stations, administrative areas, etc.) and massive dynamic data (such as shift data) need to be used. Based on the above factors and combined with the business characteristics of transit transportation splicing, the cache architecture is designed as follows:
Basic data (such as stations, administrative areas, etc.), due to the small amount of data, changes The frequency is low, the entire amount is saved in HashMap, and the entire amount is updated periodically;
# Some train, plane, car, and ship schedule data are cached in Redis to improve access efficiency and stability. The caching strategies adopted by different production lines are slightly different, but in general they are a combination of scheduled updates and search-triggered updates;
Hundreds of product queries may be queried in one splicing process. For line data, the cumulative millisecond delay of Redis is also very large. Therefore, it is hoped to build another layer of memory cache on top of Redis to improve performance. Through analysis, it was found that there are very obvious hot data in the splicing process. The proportion of queries on popular dates and routes is very high and the number is relatively limited. Therefore, this part of hotspot data can be saved in the memory cache and replaced with LFU (Least Frequently Used). The final production line data memory cache hit rate reaches more than 45%, which is equivalent to reducing nearly half of the IO overhead.
Because minute-level data inconsistency can be accepted, the splicing results are cached. During the validity period, if the next user queries the same route on the same departure date, the cached data can be used directly. . Because the spliced transfer scheme data is relatively large, the splicing results are saved in RocksDB. Although the performance is not as good as Redis, the impact on a single query is acceptable.
Figure 8 Multi-level cache structure
4.3 Preprocessing
Although in theory you can choose any city as a transit point between the two places, in fact most transit cities are unable to splice high-quality solutions. Therefore, some high-quality transfer points are first screened out through offline preprocessing, thereby reducing the solution space from thousands to tens. Compared with dynamically changing shifts, line data is relatively fixed and can be calculated once a day. In addition, offline preprocessing can use big data technology to process massive data and is relatively insensitive to time consumption.
4.4 Multi-threaded processing
In a splicing process, dozens of lines with different transfer points need to be processed. The splicing of each line is independent of each other, so multi-threading can be used, which minimizes processing time. However, due to the influence of the number of line shifts and cache hit rate, the splicing time of different lines is difficult to be consistent. Many times, when two threads are assigned the same number of tasks, even if one thread finishes executing quickly, it must wait for the other thread to finish executing before proceeding to the next step. To avoid this situation, the work-stealing mechanism of ForkJoinPool is used. This mechanism can ensure that after each thread completes its own task, it will share the unfinished work of other threads, improve concurrency efficiency, and reduce idle time.
But multi-threading is not omnipotent. When using it, you need to pay attention to:
The execution of subtasks needs to be independent of each other and independent of each other. Influence. If there are dependencies, you need to wait for the previous task to be executed before starting the next task, which will make multi-threading meaningless;
The number of CPU cores determines the upper limit of concurrency. Too many threads will reduce performance due to frequent context switching. Special attention needs to be paid to indicators such as the number of threads, CPU usage, and CPU Throttled time.
4.5 Delayed calculation
By deferring calculation to the necessary moment, it is possible to avoid a lot of redundant overhead. For example, after splicing the transfer plan, you need to build the plan entity and improve the business fields. This part also consumes resources. And not all spliced solutions will be screened out, which means that these unscreened solutions still need to consume computing resources. Therefore, the construction of the complete solution entity object is delayed. Tens of thousands of solutions in the splicing process are first saved as lightweight intermediate objects, and the complete solution entity is only built for the hundreds of intermediate objects after screening.
4.6 JVM Optimization
The transit traffic splicing project is based on Java 8 and uses the G1 (Garbage-First) garbage collector and is deployed on 8C8G machines. G1 achieves high throughput while meeting pause time requirements as much as possible. The default parameters set by the system architecture department are already suitable for most scenarios and usually do not require special optimization.
However, there are too many line transfer schemes, resulting in packets that are too large, exceeding half of the Region size (8G, the default Region size is 2M), resulting in many large objects that should enter the young generation directly Entering the old age, in order to avoid this situation, change the Region size to 16M.
5. Summary
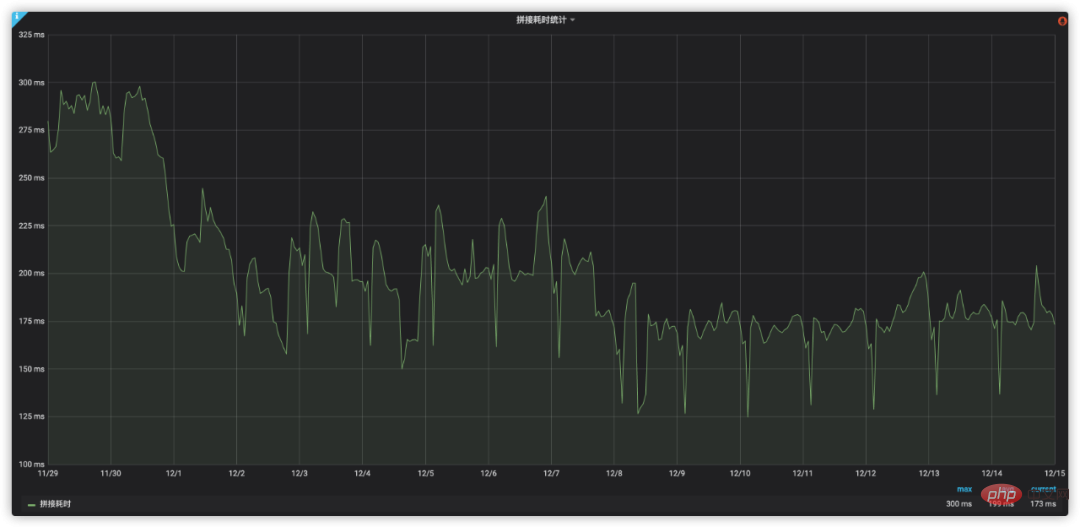
Through the above analysis and optimization, the changes in splicing time consumption are shown in Figure 9:
Figure 9 Performance optimization effect of transfer transportation scheme splicing
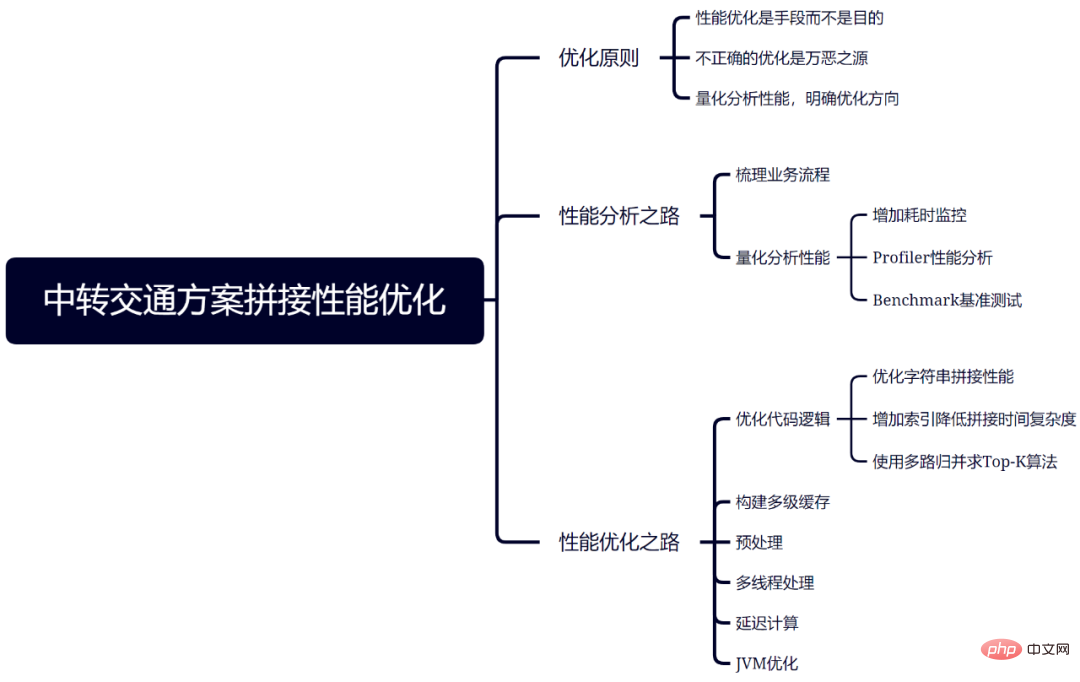
Although each business and scenario has its own characteristics, performance optimization also requires specific analysis. However, the principles are the same, and you can still refer to the analysis and optimization methods described in this article. A summary of all analysis and optimization methods in this article is shown in Figure 10.
Figure 10 Summary of splicing optimization of transfer transportation plan
The above is the detailed content of Optimize the splicing performance of Ctrip's transfer transportation plan. For more information, please follow other related articles on the PHP Chinese website!
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



