


Due to the rapid development of visual generative models such as Stable Diffusion, high-fidelity face images can be automatically forged, creating an increasingly serious DeepFake problem.
With the emergence of large language models such as ChatGPT, a large number of fake articles can also be easily generated and maliciously spread false information.
To this end, a series of single-modal detection models have been designed to deal with the forgery of the above AIGC technology in image and text modalities. However, these methods cannot cope well with multi-modal fake news tampering in new forgery scenarios.
Specifically, in multi-modal media tampering, the faces of important figures in pictures of various news reports (the face of the French President in Figure 1) are replaced, and the text Key phrases or words have been tampered with (in Figure 1, the positive phrase "is welcome to" has been tampered with the negative phrase "is forced to resign").
This will change or cover up the identity of key news figures, as well as modify or mislead the meaning of news text, creating multi-modal fake news that is spread on a large scale on the Internet.
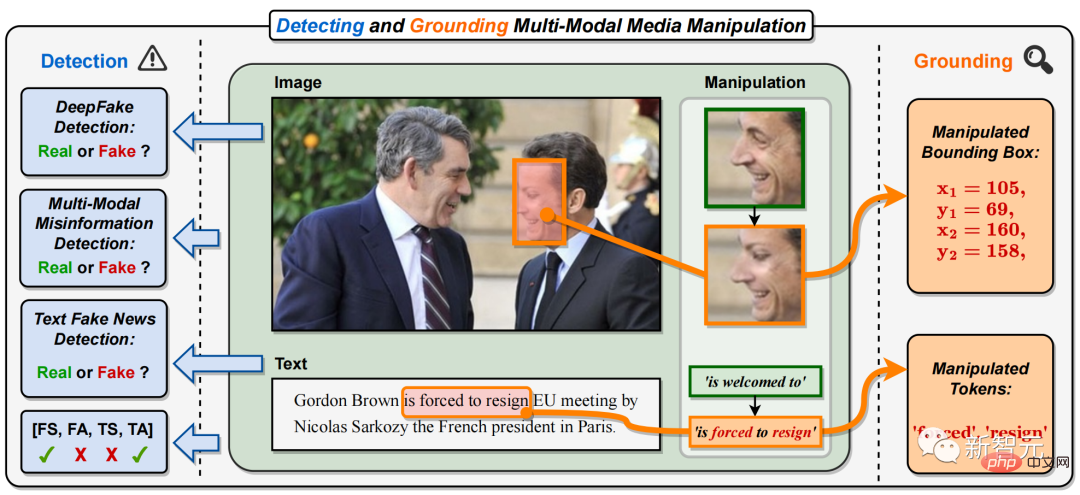
## Figure 1. This paper proposes the task of detecting and locating multi-modal media tampering (DGM4). Different from existing single-modal DeepFake detection tasks, DGM4 not only predicts whether the input image-text pair is true or false, but also attempts to detect more fine-grained tampering types and locate image tampered areas and text tampering. word. In addition to true and false binary classification, this task provides a more comprehensive explanation and deeper understanding of tamper detection.

Table 1: Proposed DGM4 versus existing image and text forgery detection Comparison of related tasks
Detecting and locating multi-modal media tampering tasksTo understand this new challenge, research from Harbin Institute of Technology (Shenzhen) and Nanyang Technological University The researchers proposed the task of detecting and locating multi-modal media tampering (DGM4), built and open sourced the DGM4 data set, and also proposed a multi-modal hierarchical tampering inference model. Currently, this work has been included in CVPR 2023.

On Article address: https://arxiv.org/abs /2304.02556
GitHub:https://github.com/rshaojimmy/MultiModal-DeepFake
Project homepage: https://rshaojimmy.github.io/Projects/MultiModal-DeepFake
As shown in Figure 1 and Table 1, detection And the difference between Detecting and Grounding Multi-Modal Media Manipulation (DGM4) and existing single-modal tampering detection is:
1) Different from existing DeepFake image detection and fake text detection methods that can only detect single-modal fake information, DGM4 requires simultaneous detection of multi-modality in image-text pairs. State tampering;
2) Unlike existing DeepFake detection that focuses on binary classification, DGM4 further considers locating image tampered areas and text tampered words. This requires the detection model to perform more comprehensive and in-depth reasoning for tampering between image-text modalities.
Detect and locate multi-modal media tampering data setIn order to support the research on DGM4, as shown in Figure 2, the contribution of this work Developed the world's firstdetection and location of multi-modal media tampering (DGM4) data set.
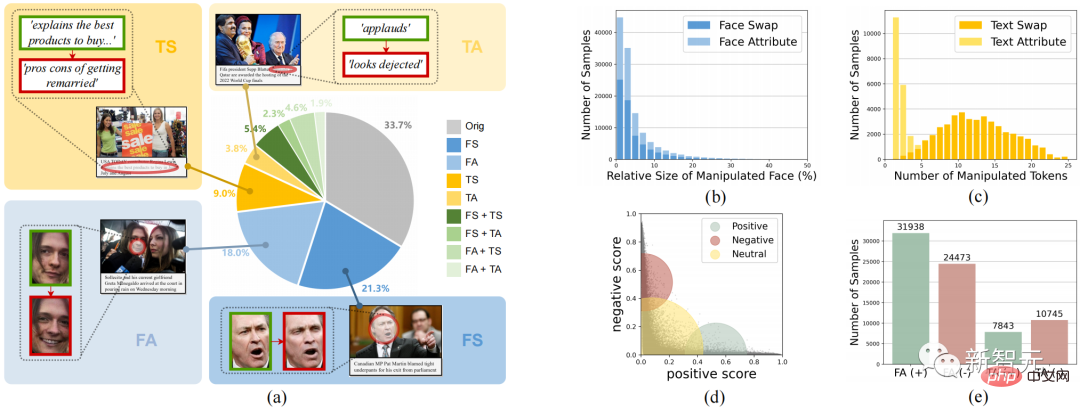
Figure 2. DGM4Dataset
DGM The 4 data set investigates 4 types of tampering, face replacement tampering (FS), face attribute tampering (FA), text replacement tampering (TS), and text attribute tampering (TA).
Figure 2 shows the overall statistical information of DGM4, including (a) the distribution of the number of tampering types; (b) the tampered areas of most images are small in size , especially for face attribute tampering; (c) text attribute tampering has fewer tampered words than text replacement tampering; (d) distribution of text sentiment scores; (e) number of samples for each tampering type.
This data generated a total of 230,000 image-text pair samples, including 77,426 original image-text pairs and 152,574 tampered sample pairs. The tampered sample pairs include 66722 face replacement tampering, 56411 face attribute tampering, 43546 text replacement tampering and 18588 text attribute tampering.
This article believes that multimodal tampering will cause subtle semantic inconsistencies between modalities. Therefore, detecting the cross-modal semantic inconsistency of tampered samples by fusing and inferring semantic features between modalities is the main idea of this article to deal with DGM4.
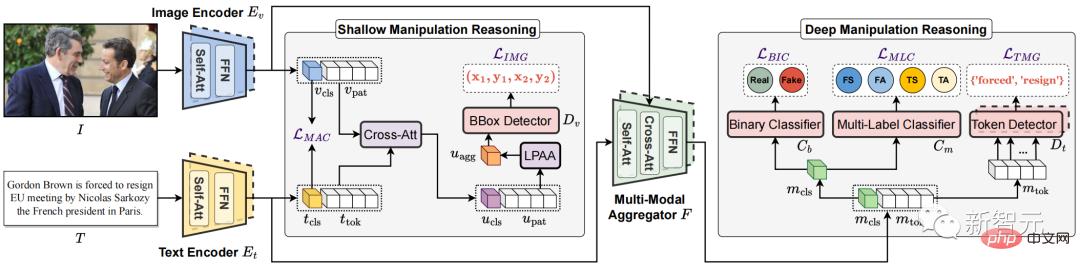
Figure 3. The proposed multi-modal hierarchical tampering inference model HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER)
Based on this idea, as shown in Figure 3, this article proposes a multi-modal hierarchical tampering inference model HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER).
This model is built on the model architecture of multi-modal semantic fusion and reasoning based on the dual-tower structure, and integrates the detection and location of multi-modal tampering in a fine-grained and hierarchical manner through shallow Layer and deep tamper reasoning are implemented.
Specifically, as shown in Figure 3, the HAMMER model has the following two characteristics:
1) In shallow tampering inference , through Manipulation-Aware Contrastive Learning to align the single-modal semantic features of images and texts extracted by the image encoder and text encoder. At the same time, the single-modal embedded features use the cross-attention mechanism for information interaction, and a local patch attention aggregation mechanism (Local Patch Attentional Aggregation) is designed to locate the image tampering area;
2) In deep tamper reasoning, the modality-aware cross-attention mechanism in the multi-modal aggregator is used to further fuse multi-modal semantic features. On this basis, special multi-modal sequence tagging and multi-modal multi-label classification are performed to locate text tampered words and detect altered words. Fine-grained tampering types.
As shown below, the experimental results show that the HAMMER proposed by the research team can detect more accurately compared with multi-modal and single-modal detection methods and locating multimodal media tampering.

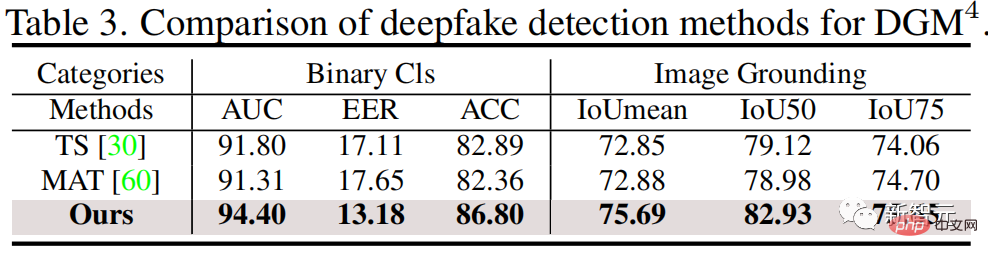
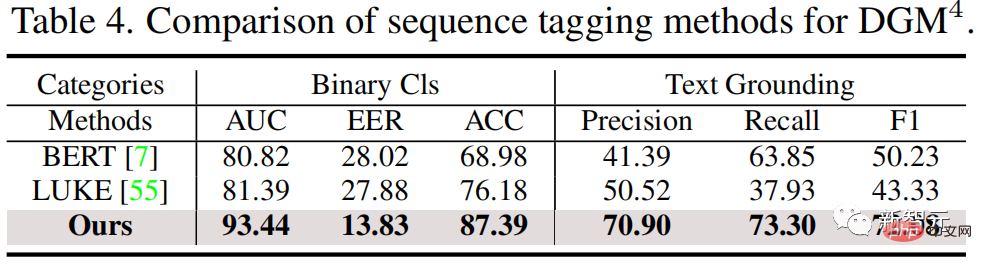
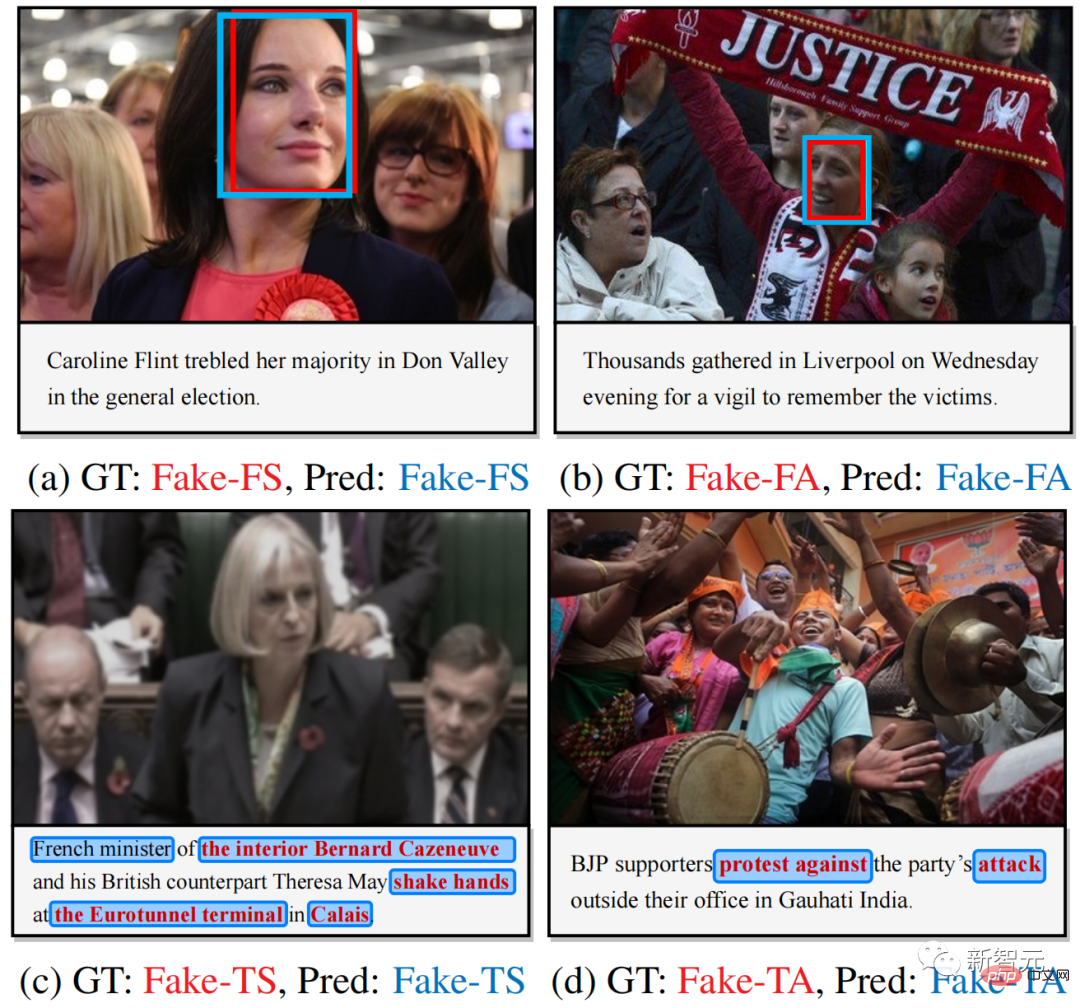
Figure 4. Visualization of multi-modal tamper detection and location results

Figure 5 . Model Tamper Detection Attention Visualization on Tampered Text
Figure 4 provides some visualization results of multi-modal tamper detection and localization, illustrating that HAMMER can accurately and simultaneously Tamper detection and localization tasks. Figure 5 provides the model attention visualization results on tampered words, further demonstrating that HAMMER performs multi-modal tampering detection and localization by focusing on image areas that are semantically inconsistent with the tampered text.
The code and data set link of this work have been shared on the GitHub of this project. Everyone is welcome to Star this GitHub Repo and use the DGM4 data set and HAMMER Let’s study the DGM4 problem. The field of DeepFake is not only about single-modality detection of images, but also a broader multi-modal tampering detection problem that needs to be solved urgently!
The above is the detailed content of Harbin Institute of Technology and Nanyang Institute of Technology propose the world's first 'Multi-modal DeepFake Detection and Positioning' model: giving AIGC no place to hide fakes. For more information, please follow other related articles on the PHP Chinese website!
 Convert text to numeric value
Convert text to numeric value
 Bitcoin exchange
Bitcoin exchange
 Windows 10 startup password setting tutorial
Windows 10 startup password setting tutorial
 How to solve the problem of not being able to create a new folder in Win7
How to solve the problem of not being able to create a new folder in Win7
 what is h5
what is h5
 How to check dead links on your website
How to check dead links on your website
 How to recover files emptied from Recycle Bin
How to recover files emptied from Recycle Bin
 Introduction to the plug-ins required for vscode to run java
Introduction to the plug-ins required for vscode to run java








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



