


Java distributed Kafka message queue instance analysis

Introduction
Apache Kafka is a distributed publish-subscribe messaging system. The definition of kafka on the kafka official website is: a distributed publish-subscribe messaging system. It was originally developed by LinkedIn, which was contributed to the Apache Foundation in 2010 and became a top open source project. Kafka is a fast, scalable, and inherently distributed, partitioned, and replicable commit log service.
Note: Kafka does not follow the JMS specification (), it only provides publish and subscribe communication methods.
Kafka core related names
Broker: Kafka node, a Kafka node is a broker, multiple brokers can form a Kafka cluster
Topic: A type of message. The directory where the message is stored is the topic. For example, page view logs, click logs, etc. can exist in the form of topics. The Kafka cluster can be responsible for the distribution of multiple topics at the same time.
massage: The most basic delivery object in Kafka.
Partition: The physical grouping of topics. A topic can be divided into multiple partitions, and each partition is an ordered queue. Partitioning is implemented in Kafka, and a broker represents a region.
Segment: Partition is physically composed of multiple segments. Each segment stores message information.
Producer: Producer, produces messages and sends them. Go to topic
- ##Consumer: consumer, subscribe to topic and consume messages, consumer consumes as a thread
- Consumer Group: consumer group, A Consumer Group contains multiple consumers
- Offset: offset, understood as the index position of the message in the message partition
- Install jdk1.8 environment on each server
- Install Zookeeper cluster environment
- Install kafka cluster environment
- Run environment test
tar -zxvf kafka_2.11 -1.0.0.tgz3. Modify kafka’s configuration file config/server.propertiesConfiguration file modification content:
- zookeeper connection address:
zookeeper.connect=192.168.1.19:2181
- The listening ip is changed to the local ip
listeners=PLAINTEXT:// 192.168.1.19:9092
- #kafka’s brokerid, each broker’s id is different
broker.id=0
./kafka-server-start.sh -daemon config/server.properties
./kafka-topics.sh --create --zookeeper localhost: 2181 --replication-factor 1 --partitions 3 --topic kaico
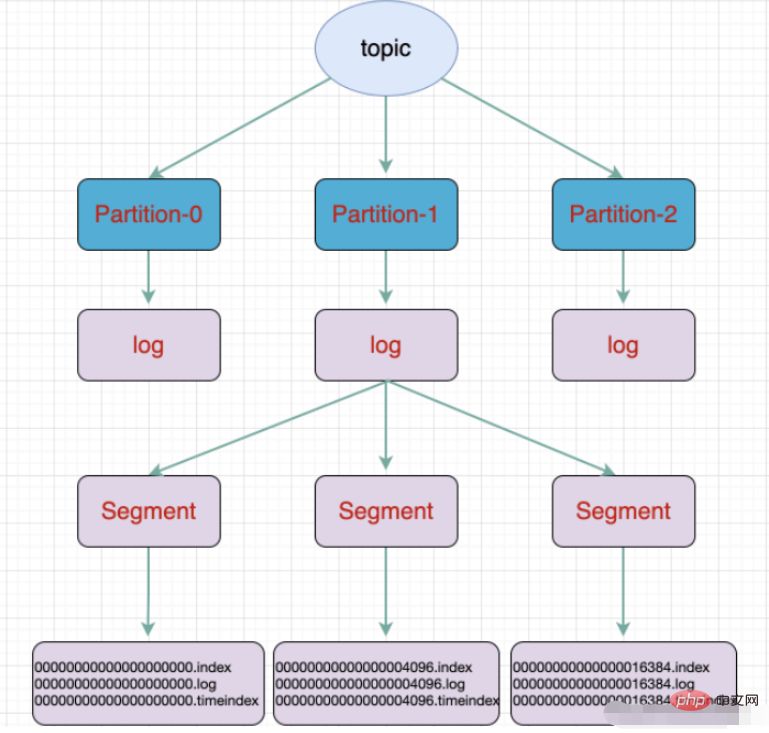
- ##a partition Divided into multiple segments
- .log log file
- .index offset index file
- .timeindex timestamp index file
- Other files (partition.metadata, leader-epoch-checkpoint)
- Springboot integration kafka
maven dependency
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>yml configuration
# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094producer
@RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}consumer
@Component
public class TopicKaicoConsumer {
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topics = "kaico") //监听的主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
//输出key对应的value的值
System.out.println(consumer.value());
}
}The above is the detailed content of Java distributed Kafka message queue instance analysis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 python argparse required argument example
Aug 11, 2025 pm 09:42 PM
python argparse required argument example
Aug 11, 2025 pm 09:42 PM
When using the argparse module, the parameters that must be provided can be achieved by setting required=True. 1. Use required=True to set optional parameters (such as --input) to be required. If not provided when running the script, an error will be reported; 2. Position parameters are required by default, and there is no need to set required=True; 3. It is recommended to use position parameters for necessary parameters. Occasionally, the optional parameters of required=True are used to maintain flexibility; 4. required=True is the most direct way to control parameters. After use, the user must provide corresponding parameters when calling the script, otherwise the program will prompt an error and exit.
 The Best IDEs for Java Development: A Comparative Review
Aug 12, 2025 pm 02:55 PM
The Best IDEs for Java Development: A Comparative Review
Aug 12, 2025 pm 02:55 PM
ThebestJavaIDEin2024dependsonyourneeds:1.ChooseIntelliJIDEAforprofessional,enterprise,orfull-stackdevelopmentduetoitssuperiorcodeintelligence,frameworkintegration,andtooling.2.UseEclipseforhighextensibility,legacyprojects,orwhenopen-sourcecustomizati
 What are comments in Java?
Aug 12, 2025 am 08:20 AM
What are comments in Java?
Aug 12, 2025 am 08:20 AM
CommentsinJavaareignoredbythecompilerandusedforexplanation,notes,ordisablingcode.Therearethreetypes:1)Single-linecommentsstartwith//andlastuntiltheendoftheline;2)Multi-linecommentsbeginwith/andendwith/andcanspanmultiplelines;3)Documentationcommentsst
 How to use the HttpClient API in Java
Aug 12, 2025 pm 02:27 PM
How to use the HttpClient API in Java
Aug 12, 2025 pm 02:27 PM
The core of using the JavaHttpClientAPI is to create an HttpClient, build an HttpRequest, and process HttpResponse. 1. Use HttpClient.newHttpClient() or HttpClient.newBuilder() to configure timeouts, proxy, etc. to create clients; 2. Use HttpRequest.newBuilder() to set URI, method, header and body to build requests; 3. Send synchronous requests through client.send() or send asynchronous requests through client.sendAsync(); 4. Use BodyHandlers.ofStr
 How to compare Strings in Java
Aug 12, 2025 am 10:00 AM
How to compare Strings in Java
Aug 12, 2025 am 10:00 AM
Use .equals() to compare string content, because == only compare object references rather than actual characters; 2. Use .equalsIgnoreCase() when comparing ignoring case; 3. Use .compareTo() when sorting alphabetically, and .compareToIgnoreCase() when ignoring case; 4. Avoid calling strings that may be null. Equals() should be used to use "literal".equals(variable) or Objects.equals(str1,str2) to safely handle null values; in short, always pay attention to content comparison rather than reference,
 What is a LinkedList in Java?
Aug 12, 2025 pm 12:14 PM
What is a LinkedList in Java?
Aug 12, 2025 pm 12:14 PM
LinkedList is a bidirectional linked list in Java, implementing List and Deque interfaces. It is suitable for scenarios where elements are frequently inserted and deleted. Especially when operating on both ends of the list, it has high efficiency, but the random access performance is poor and the time complexity is O(n). Insertion and delete can reach O(1) at known locations. Therefore, it is suitable for implementing stacks, queues, or situations where structures need to be dynamically modified, and is not suitable for read-intensive operations that frequently access by index. The final conclusion is that LinkedList is better than ArrayList when it is frequently modified but has fewer accesses.
 Fix: Ethernet 'Unidentified Network'
Aug 12, 2025 pm 01:53 PM
Fix: Ethernet 'Unidentified Network'
Aug 12, 2025 pm 01:53 PM
Restartyourrouterandcomputertoresolvetemporaryglitches.2.RuntheNetworkTroubleshooterviathesystemtraytoautomaticallyfixcommonissues.3.RenewtheIPaddressusingCommandPromptasadministratorbyrunningipconfig/release,ipconfig/renew,netshwinsockreset,andnetsh
 edge not saving history
Aug 12, 2025 pm 05:20 PM
edge not saving history
Aug 12, 2025 pm 05:20 PM
First,checkif"Clearbrowsingdataonclose"isturnedoninSettingsandturnitofftoensurehistoryissaved.2.Confirmyou'renotusingInPrivatemode,asitdoesnotsavehistorybydesign.3.Disableextensionstemporarilytoruleoutinterferencefromprivacyorad-blockingtoo
