


In 2021, Microsoft, OpenAI, and Github jointly created a useful code completion and suggestion tool-Copilot.
It recommends lines of code within the developer's code editor, such as when developers enter code in integrated development environments such as Visual Studio Code, Neovim and JetBrains IDE. Be able to recommend the next line of code. In addition, Copilot can even provide advice on complete methods and complex algorithms, as well as assistance with template code and unit testing.
More than a year later, this tool has become an inseparable "programming partner" for many programmers. Andrej Karpathy, former director of artificial intelligence at Tesla, said, "Copilot has greatly accelerated my programming speed, and it is difficult to imagine how to go back to 'manual programming'. Currently, I am still learning how to use it, and it has programmed nearly 80% of my The code, the accuracy is close to 80%."
In addition to getting used to it, we also have some questions about Copilot, such as what does Copilot's prompt look like? How does it call the model? How is its recommendation success rate measured? Will it collect user code snippets and send them to its own server? Is the model behind Copilot a large model or a small model?
To answer these questions, a researcher from the University of Illinois at Urbana-Champaign roughly reverse-engineered Copilot and blogged about his observations.
Andrej Karpathy recommended this blog in his tweet.
The following is the original text of the blog.
Github Copilot is very useful to me. It often magically reads my mind and makes helpful suggestions. What surprised me the most was its ability to correctly "guess" functions/variables from surrounding code (including code in other files). This only happens when the Copilot extension sends valuable information from the surrounding code to the Codex model. I was curious about how it worked, so I decided to take a look at the source code.
In this post I try to answer specific questions about the internals of Copilot, while also describing some interesting observations I made while combing through the code.
The code for this project can be found here:
Code address: https: //github.com/thakkarparth007/copilot-explorer
The entire article is structured as follows:

A few months ago I did a very superficial "reverse engineering" of the Copilot extension, and I've been wanting to delve deeper ever since. I finally got around to doing this in the past few weeks. Basically, by using the extension.js file included with Copilot, I made some minor manual changes to simplify the automatic extraction of modules, and wrote a bunch of AST transformations to "beautify" each module, naming the modules, Also classify and manually annotate some of the most interesting parts.
You can explore the reverse-engineered copilot code base through the tools I built. It may not be comprehensive and refined, but you can still use it to explore Copilot's code.
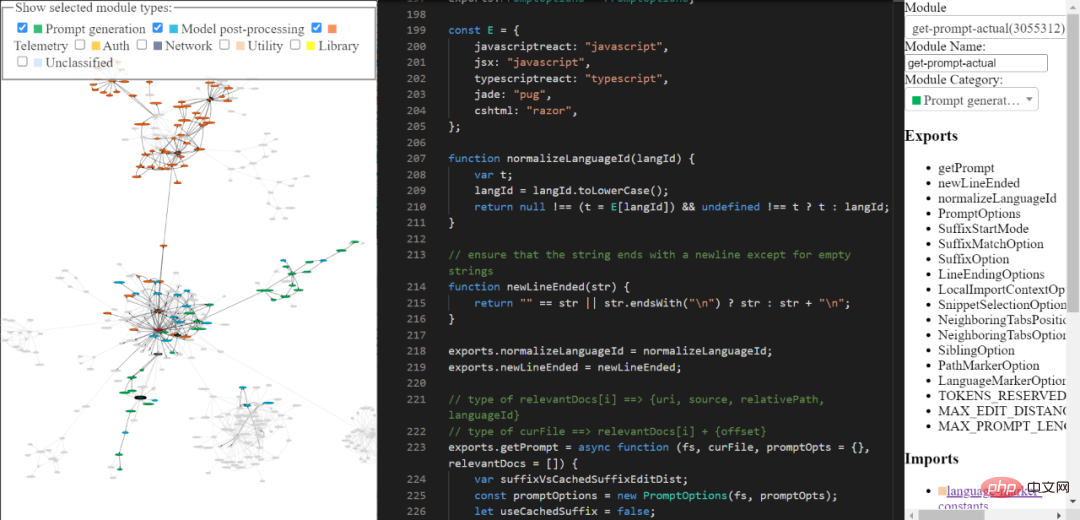
Tool link: https://thakkarparth007.github.io/copilot-explorer/
Github Copilot consists of the following two main parts:
Now, Codex has been trained on a large amount of public Github code, so it is reasonable that it can make useful suggestions . But Codex has no way of knowing what features exist in your current project. Even so, it can still make suggestions involving project features. How does it do that?
Let's answer this in two parts: first let's look at a real prompt example generated by copilot, and then we'll look at how it is generated.
What prompt looks like
The Copilot extension encodes a lot of information related to your project in the prompt. Copilot has a fairly complex prompt engineering pipeline. Here is an example of a prompt:
{"prefix": "# Path: codeviz\app.pyn# Compare this snippet from codeviz\predictions.py:n# import jsonn# import sysn# import timen# from manifest import Manifestn# n# sys.path.append(__file__ + "/..")n# from common import module_codes, module_deps, module_categories, data_dir, cur_dirn# n# gold_annots = json.loads(open(data_dir / "gold_annotations.js").read().replace("let gold_annotations = ", ""))n# n# M = Manifest(n# client_name = "openai",n# client_connection = open(cur_dir / ".openai-api-key").read().strip(),n# cache_name = "sqlite",n# cache_connection = "codeviz_openai_cache.db",n# engine = "code-davinci-002",n# )n# n# def predict_with_retries(*args, **kwargs):n# for _ in range(5):n# try:n# return M.run(*args, **kwargs)n# except Exception as e:n# if "too many requests" in str(e).lower():n# print("Too many requests, waiting 30 seconds...")n# time.sleep(30)n# continuen# else:n# raise en# raise Exception("Too many retries")n# n# def collect_module_prediction_context(module_id):n# module_exports = module_deps[module_id]["exports"]n# module_exports = [m for m in module_exports if m != "default" and "complex-export" not in m]n# if len(module_exports) == 0:n# module_exports = ""n# else:n# module_exports = "It exports the following symbols: " + ", ".join(module_exports)n# n# # get module snippetn# module_code_snippet = module_codes[module_id]n# # snip to first 50 lines:n# module_code_snippet = module_code_snippet.split("\n")n# if len(module_code_snippet) > 50:n# module_code_snippet = "\n".join(module_code_snippet[:50]) + "\n..."n# else:n# module_code_snippet = "\n".join(module_code_snippet)n# n# return {"exports": module_exports, "snippet": module_code_snippet}n# n# #### Name prediction ####n# n# def _get_prompt_for_module_name_prediction(module_id):n# context = collect_module_prediction_context(module_id)n# module_exports = context["exports"]n# module_code_snippet = context["snippet"]n# n# prompt = f"""\n# Consider the code snippet of an unmodule named.n# nimport jsonnfrom flask import Flask, render_template, request, send_from_directorynfrom common import *nfrom predictions import predict_snippet_description, predict_module_namennapp = Flask(__name__)nn@app.route('/')ndef home():nreturn render_template('code-viz.html')nn@app.route('/data/<filename>')ndef get_data_files(filename):nreturn send_from_directory(data_dir, filename)nn@app.route('/api/describe_snippet', methods=['POST'])ndef describe_snippet():nmodule_id = request.json['module_id']nmodule_name = request.json['module_name']nsnippet = request.json['snippet']ndescription = predict_snippet_description(nmodule_id,nmodule_name,nsnippet,n)nreturn json.dumps({'description': description})nn# predict name of a module given its idn@app.route('/api/predict_module_name', methods=['POST'])ndef suggest_module_name():nmodule_id = request.json['module_id']nmodule_name = predict_module_name(module_id)n","suffix": "if __name__ == '__main__':rnapp.run(debug=True)","isFimEnabled": true,"promptElementRanges": [{ "kind": "PathMarker", "start": 0, "end": 23 },{ "kind": "SimilarFile", "start": 23, "end": 2219 },{ "kind": "BeforeCursor", "start": 2219, "end": 3142 }]}</filename>As you can see, the above prompt includes a prefix and a suffix. Copilot then sends this prompt (after some formatting) to the model. In this case, because the suffix is non-empty, Copilot will call the Codex in "insert mode", that is, fill-in-middle (FIM) mode.
If you look at the prefix, you will see that it contains some code from another file in the project. See # Compare this snippet from codeviz\predictions.py: The line of code and the lines after it
#How is the prompt prepared?
Roughly, the following sequence of steps are executed to generate the prompt:
Generally speaking, prompt passes the following series Step-by-step generation:
#1. Entry point: prompt The extraction occurs at the given document and cursor position. The main entry point generated is extractPrompt (ctx, doc, insertPos)
2. Query the relative path and language ID of the document from VSCode. See: getPromptForRegularDoc (ctx, doc, insertPos)
3. Related documents: Then, query the 20 most recently accessed files of the same language from VSCode. See getPromptHelper (ctx, docText, insertOffset, docRelPath, docUri, docLangId) . These files are later used to extract similar snippets to be included in prompt. I personally think it's weird to use the same language as a filter since multi-language development is quite common. But I guess that still covers most cases.
4. Configuration: Next, set some options. Specifically include:
#5. Prefix calculation: Now, create a "Prompt Wishlist" to calculate the prefix part of prompt. Here, we add different "elements" and their priorities. For example, an element could be something like "Compare this fragment from ", or the context of a local import, or the language ID and/or path of each file. This all happens in getPrompt (fs, curFile, promptOpts = {}, relevantDocs = []) .
6. Suffix calculation: The previous step is for prefixes, but the logic of suffixes is relatively simple - just fill the token budget with any available suffix from the cursor. . This is the default setting, but the starting position of the suffix will vary slightly depending on the SuffixStartMode option, which is also controlled by the AB experiment framework. For example, if SuffixStartMode is a SiblingBlock, Copilot will first find the closest functional sibling of the function being edited and write the suffix from there.
Looking closely at the fragment extraction
To me, the most complete parts of the prompt generation seem to be extracted from other files fragment. It is called here and defined by neighbor-snippet-selector.getNeighbourSnippets. Depending on the options, this will use the "Fixed window Jaccard matcher" or the "Indentation based Jaccard Matcher". I'm not 100% sure, but it doesn't look like the Indentation based Jaccard Matcher is actually used.
By default, we use fixed window Jaccard Matcher. In this case, the given file (from which the fragments will be extracted) is split into fixed-size sliding windows. Then calculate the Jaccard similarity between each window and the reference file (the file you are typing into). Only the optimal window is returned for each "related file" (although there is a requirement to return the top K fragments, this is never followed). By default, FixedWindowJaccardMatcher will be used in "Eager mode" (that is, the window size is 60 lines). However, this mode is controlled by the AB Experimentation framework, so we may use other modes.
Copilot provides completion through two UIs: Inline/GhostText and Copilot Panel. In both cases, there are some differences in how the model is called.
Inline/GhostText
Main module: https://thakkarparth007.github.io/copilot-explorer/ codeviz/templates/code-viz.html#m9334&pos=301:14
In it, the Copilot extension requires the model to provide very few suggestions (1-3 items) to speed up. It also actively caches the model's results. Additionally, it takes care of adjusting the suggestions if the user continues typing. If the user is typing very fast, it will also request the model to turn on function debouncing.
This UI also sets some logic to prevent requests from being sent under certain circumstances. For example, if the user cursor is in the middle of a line, the request will only be sent if the character to the right of it is a space, closing brace, etc.
1. Block bad requests through contextual filter
What’s more interesting is that after generating the prompt, the module checks whether the prompt is “good enough” to call the model. This is achieved by calculating the “context filtering score”. This score appears to be based on a simple logistic regression model, which contains 11 features such as language, whether the previous suggestion was accepted/rejected, the duration between previous acceptances/rejections, the length of the last line in the prompt, the last character etc. This model weight is contained in the extension code itself.
If the score is below the threshold (default 15%), the request will not be made. It would be interesting to explore this model, I have observed that some languages have a higher weight than others (e.g. php > js > python > rust > dart…php). Another intuitive observation is that if the prompt ends with ) or ], the score is lower than if it ends with ( or [. This makes sense, because the former is more likely to indicate that it has already been "done", while the latter clearly indicates that the user will Benefit from auto-completion.
Copilot Panel
##Main module: https://thakkarparth007.github. io/copilot-explorer/codedeviz/templates/code-viz.html#m2990&pos=12:1
Core logic 1: https://thakkarparth007.github.io/copilot-explorer /codeviz/templates/code-viz.html#m893&pos=9:1
Core logic 2: https://thakkarparth007.github.io/copilot-explorer/codeviz/templates/ code-viz.html#m2388&pos=67:1
This UI requests more samples from the model (10 by default) than the Inline UI. This UI There seems to be no contextual filtering logic (makes sense, you wouldn't want to not prompt the model if the user explicitly calls it).
There are two main interesting things here:
Does not show useless complements Full recommendations:
Before displaying recommendations (via either UI), Copilot performs two checks:
If the output is Duplicate (such as: foo = foo = foo = foo...), which is a common failure mode of language models, then this suggestion will be discarded. This may happen in Copilot proxy server or client.
If the user has already typed the suggestion, the suggestion will also be discarded.
Secret 3: telemetryGithub claimed in a previous blog that 40% of the code written by programmers is written by Copilot (for Python and other popular languages). I was curious how they measured this number, so wanted to insert something into the telemetry code.
I would also like to know what telemetry data it collects, especially if it collects code snippets. I wonder about this because while we could easily point the Copilot extension to the open source FauxPilot backend instead of the Github backend, the extension might still send code snippets to Github via telemetry, discouraging some people who have concerns about code privacy from using it. Copilot. I wonder if this is the case.
Question 1: How is the 40% figure measured?
Measuring the success of Copilot is not simply a matter of counting acceptances/rejections, as people often accept recommendations with some modifications. Therefore, Github staff checks whether the accepted suggestion still exists in the code. Specifically, they check at 15 seconds, 30 seconds, 2 minutes, 5 minutes, and 10 minutes after the suggested code is inserted.
Exact searches for accepted suggestions are now too restrictive, so they measure the edit distance (at character level and word level) between the suggested text and the window around the insertion point ). A suggestion is considered "still in code" if the word-level edit distance between the insert and window is less than 50% (normalized to the suggestion size).
Of course, all this only applies to accepted codes.
Question 2: Does telemetry data contain code snippets?
Yes, included.
Thirty seconds after accepting or rejecting a suggestion, copilot "captures" a snapshot near the insertion point. Specifically, the extension calls the prompt extraction mechanism to collect a "hypothetical prompt" that can be used to make suggestions at that insertion point. copilot also captures "hypothetical completion" by capturing the code between the insertion point and the "guessed" endpoint. I don't quite understand how it guesses this endpoint. As mentioned before, this happens after acceptance or rejection.
I suspect these snapshots may be used as training data to further improve the model. However, 30 seconds seems too short a time to assume that the code has "settled down." But I guess, given that telemetry contains the github repo corresponding to the user's project, even if a 30-second period produces noisy data points, GitHub staff can clean this relatively noisy data offline. Of course, all of this is just speculation on my part.
Note that GitHub will let you choose whether to agree to use your code snippets to "improve the product." If you do not agree, the telemetry containing these snippets will not be sent to the server ( At least that's the case in v1.57 I checked, but I verified v1.65 as well). I check this by looking at the code and logging telemetry data points before they are sent over the network.
I modified the extension code slightly to enable verbose logging (no configurable parameter found). I found out that this model is called "cushman-ml", which strongly suggests that Copilot may be using a 12B parameter model instead of a 175B parameter model. For open source workers, this is very encouraging, meaning that a modestly sized model can provide such excellent advice. Of course, the huge amount of data held by Github is still inaccessible to open source workers.
In this article, I have not covered the worker.js file that is distributed with the extension. At first glance, it seems to basically only provide a parallel version of prompt-extraction logic, but it may have more capabilities.
File address: https://thakkarparth007.github.io/copilot-explorer/muse/github.copilot-1.57.7193/dist/worker_expanded.js
Enable verbose logging
If you want to enable verbose logging, you can do so by modifying the extension code:
If you want a ready-made patch, just copy Extension code: https://thakkarparth007.github.io/copilot-explorer/muse/github.copilot-1.57.7193/dist/extension.js
Note, this is for 1.57 .7193 version.
There are more detailed links in the original text, interested readers can check the original text.
The above is the detailed content of After reverse engineering Copilot, I found that it may only use a small model with 12B parameters.. For more information, please follow other related articles on the PHP Chinese website!
 How to make charts and data analysis charts in PPT
How to make charts and data analysis charts in PPT
 Android voice playback function implementation method
Android voice playback function implementation method
 AC contactor use
AC contactor use
 The difference between vscode and visual studio
The difference between vscode and visual studio
 The difference between Java and Java
The difference between Java and Java
 Introduction to hard disk interface types
Introduction to hard disk interface types
 nagios configuration method
nagios configuration method
 How to delete a folder in linux
How to delete a folder in linux








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



