



First normal form: field atomicity, second normal form: unique rows, with primary key columns, third normal form: each column is related to the primary key column.
In actual applications, a small number of redundant fields will be used to reduce the number of related tables and improve query efficiency.
The MySQL database itself is blocked, for example: insufficient system or network resources
SQL statements are blocked, for example : Table lock, row lock, etc., causing the storage engine not to execute the corresponding SQL statement
It is indeed that the index is used improperly and the index is not used
Due to the characteristics of the data in the table, the index is removed, but the number of table returns is huge
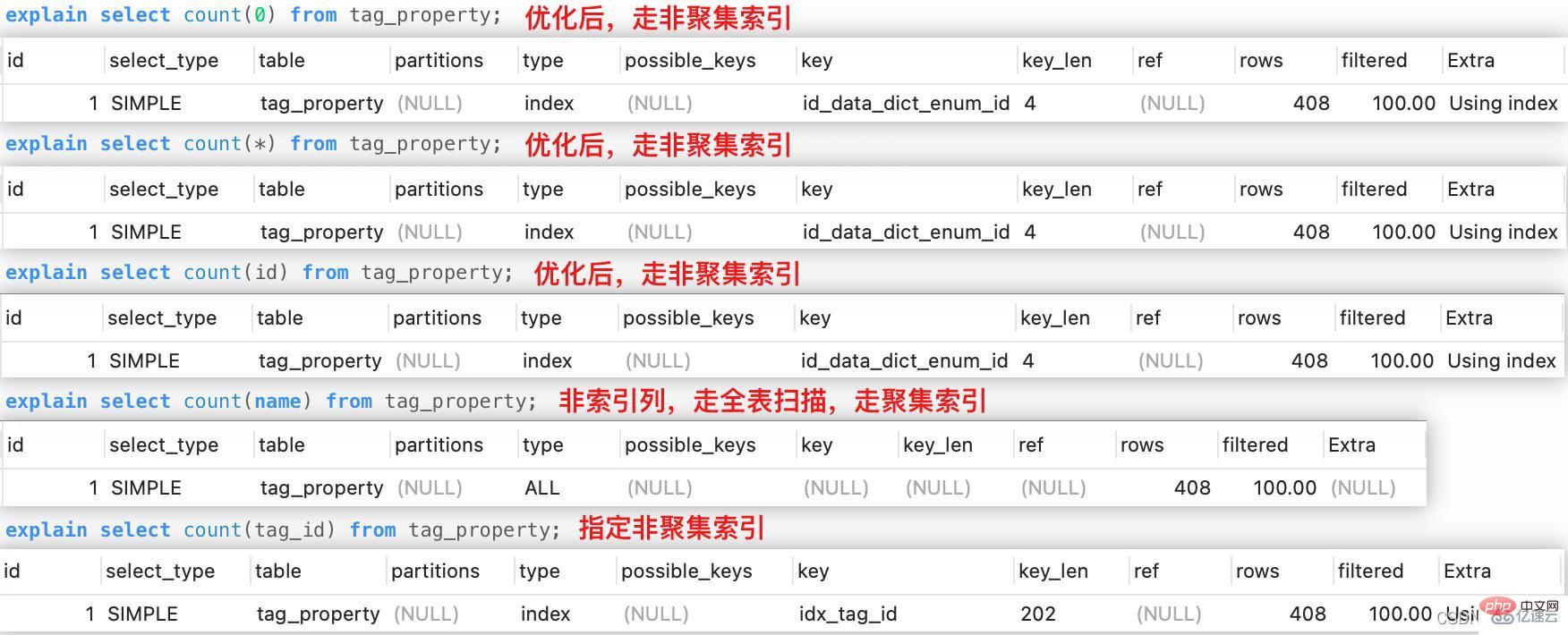
For count(*), count(constant), count(primary key) form For the count function, the optimizer can select the index with the smallest scan cost to execute the query, thereby improving efficiency. Their execution processes are the same.
For count (non-index column), the optimizer chooses a full table scan, which means that it can only sequentially scan the leaf nodes of the clustered index.
count (secondary index column)Only the index containing the columns we specify can be selected to execute the query, which may result in the execution cost of the index selected by the optimizer. Not the smallest.
1) If the amount of data is relatively large, use physical backup xtrabackup. Regularly perform full backups of the database, and you can also perform incremental backups.
2) If the amount of data is small, use mysqldump or mysqldumper, and then use binlog to recover or set up a master-slave method to recover the data. You can recover from the following points:
DML misoperation statement: You can use flashback to first parse the binlog event and then reverse it.
DDL statement misoperation: Data can only be restored through full backup and binlog application. Once the amount of data is relatively large, the recovery time will be particularly long.
rm Deletion: Use backup across computer rooms, or preferably across cities.
The DELETE statement executes the deletion process from the table each time Delete a row and save the row deletion as a transaction record in the log for rollback operation.
TRUNCATE TABLE deletes all data from the table at once and does not record individual deletion operation records in the log. Deleted rows cannot be recovered. And the deletion trigger related to the table will not be activated during the deletion process, and the execution speed is fast.
The drop statement releases all the space occupied by the table.
MySQL is "sending while reading", which means that if the client receives slowly, the MySQL server will not be able to send the results due to this transaction. The execution time becomes longer.
The server does not need to save a complete result set. The processes of getting and sending data are all operated through a next_buffer.
Memory data pages are managed in Buffer Pool (BP).
InnoDB manages Buffer Pool using an improved LRU algorithm, which is implemented using a linked list. In InnoDB implementation, the entire LRU linked list is divided into young area and old area according to the ratio of 5:3 to ensure that hot data will not be washed away when cold data is loaded in large batches.
Use id optimization: first find the last paging The maximum ID, and then use the index on the id to query, similar to select * from user where id>1000000 limit 100.
Optimize with covering index: When a MySQL query completely hits the index, it is called a covering index, which is very fast because the query only needs to search on the index and can be returned directly afterwards without Then go back to the table to get the data. Therefore, we can first find out the ID of the index, and then get the data based on the Id.
Limit the number of pages if business permits
Add appropriate indexes: Create an index for the fields used as query conditions and order by, consider multiple query fields to establish a combined index, and pay attention to the order of the combined index fields. Place the columns most commonly used as restrictive conditions on the far left, in descending order. The indexes should not be too many, generally within 5.
Optimize table structure: Numeric fields are better than string types. Smaller data types are usually better. Try to use NOT NULL
Optimization Query statement: Analyze the SQl execution plan, whether the index is hit, etc. If the SQL is very complex, optimize the SQL structure. If the amount of table data is too large, consider splitting the table
In the result of executing show processlist, I saw thousands of connections, which refers to concurrent connections.
The statement "currently executing" is a concurrent query.
The number of concurrent connections affects memory.
Concurrent queries that are too high are detrimental to the CPU. A machine has a limited number of CPU cores and if all threads rush in, the cost of context switching will be too high.
It should be noted that after a thread enters the lock wait, the concurrent thread count is reduced by one, so threads waiting for row locks or gap locks are not included in the count range. That is to say, the thread waiting for the lock does not consume the CPU, thereby preventing the entire system from locking up.
When the same data is used, the update will not be performed.
However, the log processing methods are different for different binlog formats:
1) When based on row mode, server The layer matches the record to be updated and finds that the new value is consistent with the old value. It returns directly without updating and does not record the binlog.
2) When based on statement or mixed format, MySQL executes the update statement and records the update statement to binlog.
The date range of datetime is 1001-9999; the time range of timestamp is 1970-2038
datetime storage Time has nothing to do with time zone; timestamp storage time is related to time zone, and the displayed value also depends on time zone
The storage space of datetime is 8 bytes; the storage space of timestamp is 4 bytes
The default value of datetime is null; the default value of timestamp field is not null (not null), and the default value is the current time (current_timestamp)
"Read Uncommitted" is the lowest level and cannot be guaranteed under any circumstances
"Read Uncommitted" ( Read Committed) can avoid the occurrence of dirty reads
"Repeatable Read" can avoid the occurrence of dirty reads and non-repeatable reads
"Serializable" can avoid the occurrence of dirty reads, non-repeatable reads, and phantom reads
The default transaction isolation level of Mysql is "Repeatable Read" )
kill query thread id, which means to terminate this thread The statement being executed in
kill connection thread id, where connection can be defaulted, means disconnecting this thread
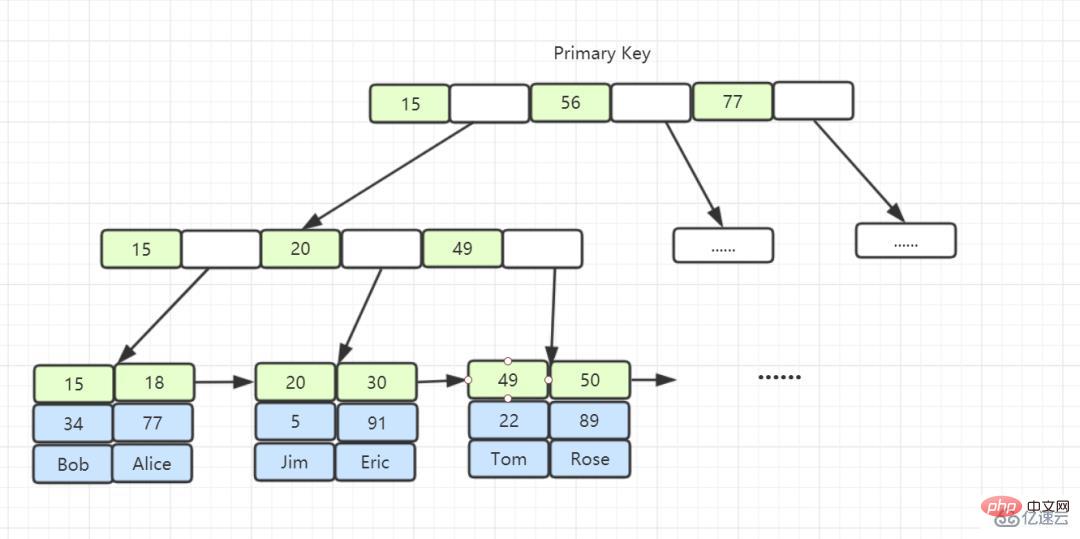
According to the content of the leaf node, the index type is divided into primary key index and non-primary key index.
The leaf node of the primary key index stores the entire row of data. In InnoDB, the primary key index is also called a clustered index.
The leaf node content of a non-primary key index is the value of the primary key. In InnoDB, non-primary key indexes are also called secondary indexes.
Clustered index: The clustered index is an index created with the primary key. The clustered index stores the data in the table in the leaf nodes.
##Non-clustered index: Indices created with non-primary keys store primary keys and index columns in leaf nodes. Use non-clustered indexes. When the clustered index queries the data, get the primary key on the leaf and then find the data you want to find. (The process of getting the primary key and then searching for it is called table return).
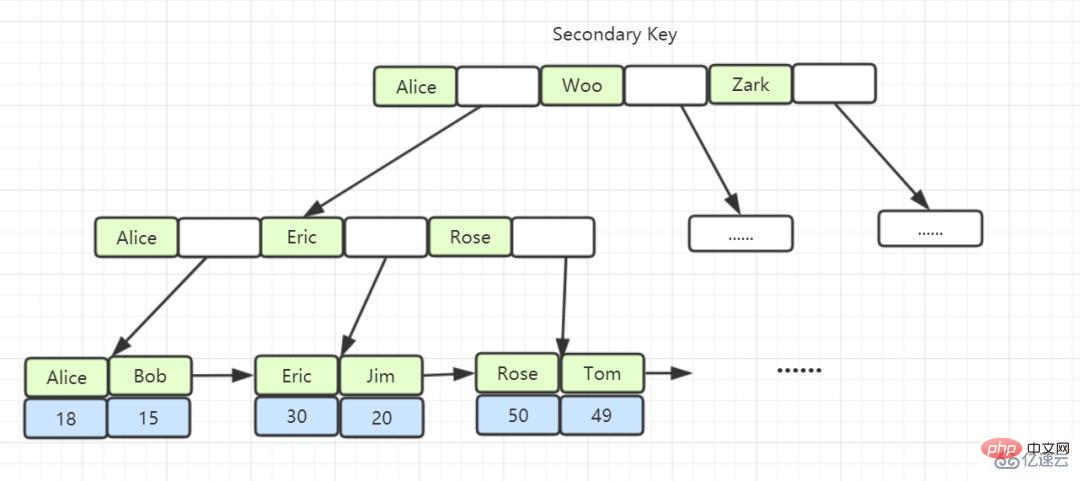
Covering index: Assuming that the columns being queried happen to be the columns corresponding to the index, there is no need to go back to the table to check. Then this index column is called a covering index.
Before MySQL 5.6, you could only return tables one by one starting from the ID. Find the data row on the primary key index, and then compare the field values.
The index pushdown optimization (index condition pushdown) introduced in MySQL 5.6 can be used to judge the fields included in the index first during the index traversal process and directly filter out the fields that do not meet the conditions. records to reduce the number of table returns.
If the table uses an auto-increment primary key, then every time a new record is inserted, the record will be added to the subsequent position of the current index node in sequence. When the page is full, A new page will be opened automatically. If a non-auto-increasing primary key is used (such as ID number or student number, etc.), since the value of the primary key inserted each time is approximately random, each new record must be inserted somewhere in the middle of the existing index page, frequently. Moving and paging operations caused a large amount of fragmentation and resulted in an index structure that was not compact enough. Subsequently, OPTIMIZE TABLE (optimize table) had to be used to rebuild the table and optimize the filled pages.
"Atomicity": It is implemented using undo log. If an error occurs during transaction execution or the user performs rollback, the system returns the status of the transaction start through the undo log. .
"Persistence": Use redo log to achieve this. As long as the redo log is persisted, when the system crashes, the data can be recovered through the redo log.
"Isolation": Transactions are isolated from each other through locks and MVCC.
"Consistency": Achieve consistency through rollback, recovery, and isolation in concurrent situations.
InnoDB storage engine: the leaf nodes of the B-tree index save the data itself;
MyISAM storage engine: the leaves of the B-tree index The physical address where the node saves the data;
InnoDB, its data file itself is an index file. Compared with MyISAM, the index file and data file are separated, and its table data file itself is by B An index structure organized by Tree. The node data field of the tree saves complete data records. The key of this index is the primary key of the data table. Therefore, the InnoDB table data file itself is the primary index. This is called "clustered index" or clustering. index, and the rest of the indexes are used as auxiliary indexes. The data field of the auxiliary index stores the value of the corresponding record's primary key instead of the address. This is also different from MyISAM.
According to the content of the leaf node, the index type is divided into primary key index and non-primary key index.
The leaf node of the primary key index stores the entire row of data. In InnoDB, the primary key index is also called a clustered index.
The leaf node content of a non-primary key index is the value of the primary key. In InnoDB, non-primary key indexes are also called secondary indexes.
Background: The fast positioning capability provided by B-tree comes from the orderliness of sibling nodes on the same layer. Therefore, if this orderliness is destroyed, it will most likely fail. The details are as follows: This situation:
Use left or left fuzzy matching on the index: that is, like %xx or like %xx%. Both of these methods will cause index failure. The reason is that the query results may be "Chen Lin, Zhang Lin, Zhou Lin" and so on, so we don't know which index value to start comparing with, so we can only query through full table scan.
Use functions for indexes/Expression calculations for indexes: Because the index saves the original value of the index field, rather than the value calculated by the function, there is no way to use the index. .
Implicit type conversion for the index: equivalent to using a new function
OR in the WHERE clause: means two as long as Just satisfy one, so it makes no sense if only one conditional column is an index column. As long as the conditional column is not an index column, a full table scan will be performed.
Stop expansion (not recommended)
Double-write migration plan: Design the expanded table structure plan, and then perform single-write migration The library and sub-library implement dual writing. After observing for a week that there is no problem, turn off the read traffic of the single library. After observing for a period of time, after it continues to be stable, turn off the write traffic of the single library and smoothly switch to the sub-database and tables.
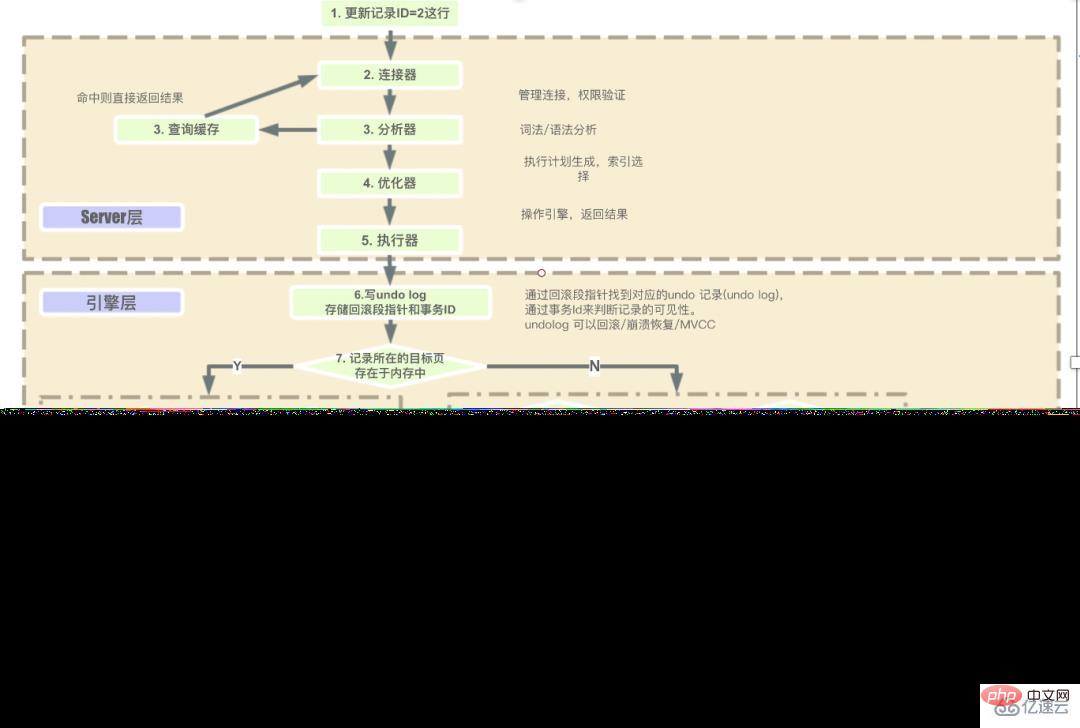
The steps for the Server layer to execute sql in sequence are:
Client request- > Connector (verify user identity and grant permissions) -> Query cache (return directly if cache exists, perform subsequent operations if it does not exist) -> Analyzer (perform lexical analysis and syntax analysis of SQL) -> Optimizer (mainly selects the optimal execution plan method for executing SQL optimization) -> Executor (during execution, it will first check whether the user has execution permission, and only then can use the interface provided by this engine) -> Go to the engine layer Get the data to return (if the query cache is turned on, the query results will be cached).
#MySQL will allocate a memory (sort_buffer) for each thread for sorting. The memory size is sort_buffer_size.
If the amount of data to be sorted is less than sort_buffer_size, the sorting will be completed in memory.
If the amount of sorted data is large and cannot be stored in memory, temporary files on disk will be used to assist sorting, also known as external sorting.
When using external sorting, MySQL will divide it into several separate temporary files to store the sorted data, and then merge these files into one large file.
MVCC (Multiversion concurrency control) is a way to retain multiple versions of the same data, thereby achieving concurrency control. When querying, find the data of the corresponding version through the read view and version chain.
Function: Improve concurrency performance. For high-concurrency scenarios, MVCC is less expensive than row-level locks.
The implementation of MVCC relies on the version chain, which is implemented through three hidden fields of the table.
#1) DB_TRX_ID: Current transaction id, the time sequence of the transaction is judged by the size of the transaction id.
2) DB_ROLL_PRT: The rollback pointer points to the previous version of the current row record. Through this pointer, multiple versions of the data are connected together to form an undo log version chain.
3) DB_ROLL_ID: primary key. If the data table does not have a primary key, InnoDB will automatically generate a primary key.
As long as redolog and binlog ensure persistent disks, MySQL exceptions can be ensured Data recovery binlog writing mechanism after restart.
redolog ensures that lost data can be redone after a system exception, and binlog archives the data to ensure that lost data can be recovered.
Write redolog before transaction execution. During transaction execution, the log is first written to the binlog cache. When the transaction is submitted, the binlog cache is written to the binlog file. .
After the data item is deleted, InnoDB marks page A and it will be marked as reusable.
delete command deletes the data of the entire table Woolen cloth? As a result, all data pages will be marked as reusable. But on disk, the file does not get smaller.
Tables that have undergone a large number of additions, deletions, and modifications may have holes. These holes also take up space, so if these holes can be removed, the purpose of shrinking the table space can be achieved.
Rebuilding the table can achieve this purpose. You can use the alter table A engine=InnoDB command to rebuild the table.
The primary key id of the operation row recorded in the binlog format of row and the primary key id of each row The real value of each field, so there will be no inconsistency in the primary and secondary operation data.
statement: the recorded source SQL statement
mixed: the first two are mixed, why do you need a file in mixed format, because some statements The binlog format may cause inconsistency between the primary and secondary servers, so the row format must be used. But the disadvantage of the row format is that it takes up a lot of space. MySQL has taken a compromise. MySQL itself will judge whether this SQL statement may cause inconsistency between the primary and secondary servers. If possible, use the row format, otherwise use the statement format.
Principle 1: The basic unit of locking is next-key lock. next-key lock is an open and closed interval.
Principle 2: Only the objects accessed during the search process will be locked
Optimization 1: Equivalent query on the index, give unique When the index is locked, the next-key lock degenerates into a row lock.
Optimization 2: For equivalent queries on the index, when traversing to the right and the last value does not meet the equality condition, the next-key lock degenerates into a gap lock
A bug: a range query on a unique index will access the first value that does not meet the condition.
"Dirty reading": Dirty reading refers to reading uncommitted data from other transactions. Uncommitment means that the data may be rolled back, which means that it may not be used in the end. Will be stored in the database, that is, data that does not exist. Reading data that may not eventually exist is called dirty reading.
"Non-repeatable read": Non-repeatable read means that within a transaction, the data read at the beginning is inconsistent with the same batch of data read at any time before the end of the transaction. Case.
"Phantom reading": Phantom reading does not mean that the result sets obtained by two reads are different. The focus of phantom reading is the data status of the result obtained by a certain select operation. Unable to support subsequent business operations. To be more specific: select whether a certain record exists. If it does not exist, prepare to insert the record. However, when executing insert, it is found that the record already exists and cannot be inserted. At this time, a phantom read occurs.
In terms of lock categories, there are shared locks and exclusive locks.
#1) Shared lock: Also called read lock. When the user wants to read data, a shared lock is added to the data. Multiple shared locks can be added at the same time .
2) Exclusive lock: Also called write lock. When the user wants to write data, add an exclusive lock to the data. Only one exclusive lock can be added, he and other Exclusive locks and shared locks are mutually exclusive.
The granularity of locks depends on the specific storage engine. InnoDB implements row-level locks, page-level locks, and table-level locks.
Their locking overhead increases from large to small, and their concurrency capabilities also increase from large to small.
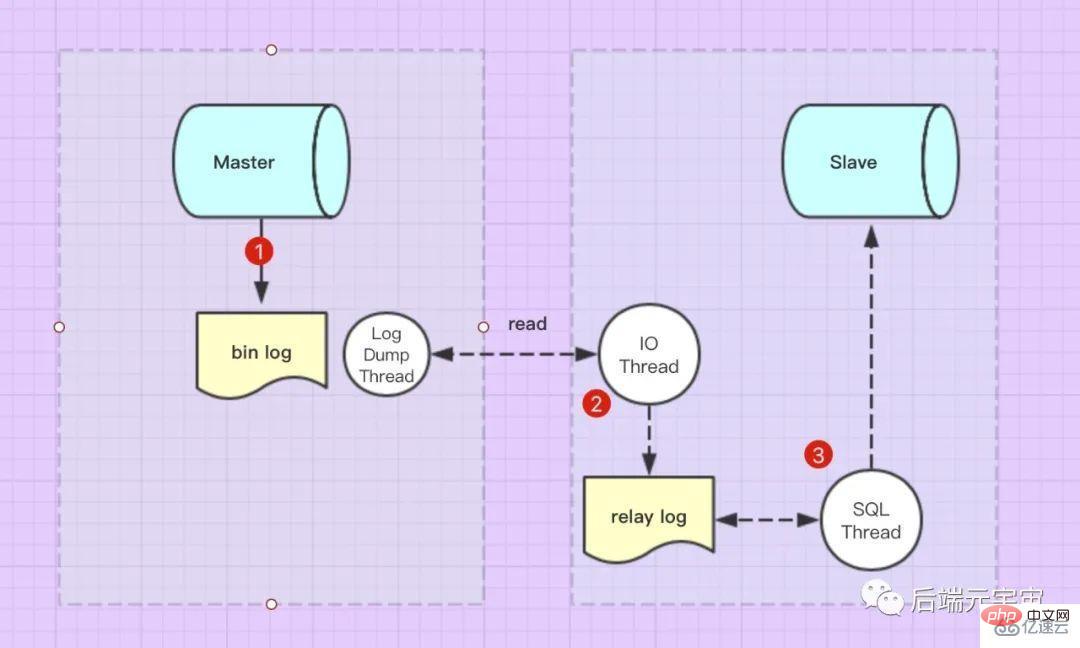
Master’s update events (update, insert, delete) will be written to bin-log in order. When the Slave is connected to the Master, the Master machine will open the binlog dump thread for the Slave, and this thread will read the bin-log log.
After the Slave is connected to the Master, the Slave library has an I/O thread Read the bin-log log by requesting the binlog dump thread, and then write it to the slave library relay logIn the log.
Slave also has a SQL thread, which monitors the relay-log log content in real time for updates, parses the SQL statements in the file, and executes them in the Slave database.
Asynchronous replication: Mysql master-slave synchronization The default is asynchronous replication. That is, among the above three steps, only the first step is synchronous (that is, Mater writes the bin log log), that is, the master library can successfully return to the client after writing the binlog log, without waiting for the binlog log to be transferred to the slave library.
Synchronous replication: For synchronous replication, after the Master host sends the event to the Slave host, a wait will be triggered until all Slave nodes (if there are multiple Slave) returns information about successful data replication to the Master.
Semi-synchronous replication: For semi-synchronous replication, after the Master host sends the event to the Slave host, a wait will be triggered until one of the Slave nodes (if (There are multiple Slaves) returns information about successful data replication to the Master.
If the master node executes a large transaction, it will have a greater impact on the master-slave delay
Network Delay, large log, too many slaves
Multi-thread writing on the master, only single-thread synchronization on the slave node
Machine performance issues , whether the slave node uses a "bad machine"
Lock conflict problems may also cause the slave's SQL thread to execute slowly
Large transactions: Divide large transactions into small transactions and update data in batches
Reduce the number of Slave to no more than 5 to reduce the size of a single transaction
After Mysql 5.7, you can use multi-threaded replication and use the MGR replication architecture
In disk, raid If there is a problem with the card or scheduling strategy, a single IO delay may be very high. You can use the iostat command to check the IO situation of the DB data disk and then make further judgments
For lock problems, you can Check by grabbing the processlist and looking at the tables related to locks and transactions under information_schema.
bin log is a file at the Mysql database level. It records all operations that modify the Mysql database. Select and show statements will not be recorded.
What is recorded in the redo log is the data to be updated. For example, if a piece of data is submitted successfully, it will not be synchronized to the disk immediately. Instead, it will be recorded in the redo log first and wait for the appropriate Refresh the disk when the opportunity arises, in order to achieve transaction durability.
undo log is used for data recall operations. It retains the content before the record is modified. Transaction rollback can be achieved through undo log, and MVCC can be implemented by tracing back to a specific version of data based on undo log.
The above is the detailed content of What are the basic issues with MySQL?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



