



Why do AI chatbots make up nonsense, and can we fully trust their output? To this end, we asked a few experts and dug deeper How these AI models work to find answers.
AI chatbots (such as OpenAI's ChatGPT) rely on a type of artificial intelligence called a "large language model" (LLM) intelligence to generate their responses. LLM is a computer program trained on millions of text sources to read and generate "natural language" textual language, just as humans naturally write or talk. Unfortunately, they also make mistakes.
In the academic literature, AI researchers often call these errors "hallucinations." As the topic has become mainstream, the label has become increasingly controversial, as some believe it anthropomorphizes AI models (suggesting they have human-like characteristics), or assigns them to AI models when it shouldn't imply this. They have power (implying that they can make their own choices). Furthermore, the creators of commercial LLMs may also use illusion as an excuse to blame the AI model for erroneous outputs rather than taking responsibility for the outputs themselves.
Still, generative AI is a very new field, and we need to borrow metaphors from existing ideas to explain these highly technical concepts to the wider public. In this case, we feel that the word "confabulation", although equally imperfect, is a better metaphor than the metaphor "hallucination." In human psychology, "fiction" refers to a gap in someone's memory, and the brain fills in the forgotten experience with a convincing fictional fact without intentionally deceiving others. ChatGPT does not operate like the human brain, but the term "fiction" is arguably a better metaphor because it works on the principle of creatively filling gaps (rather than deliberately deceiving), which we will explore below.
It’s a big problem when AI bots produce false information that may have misleading or defamatory effects. Recently, The Washington Post reported on a law professor who discovered that ChatGPT had included him on a list of legal scholars who sexually harassed others. But this matter is false and completely fabricated by ChatGPT. On the same day, Ars also reported that an Australian mayor discovered that ChatGPT’s claim that he had been convicted of bribery and jailed was also completely fabricated.
Soon after the launch of ChatGPT, people began to advocate the end of search engines. However, at the same time, many fictitious cases of ChatGPT began to circulate widely on social media. AI bots invented non-existent books and studies, publications that professors did not write, fake academic papers, fake legal citations, non-existent Linux system features, unreal retail mascots, and meaningless technical details.
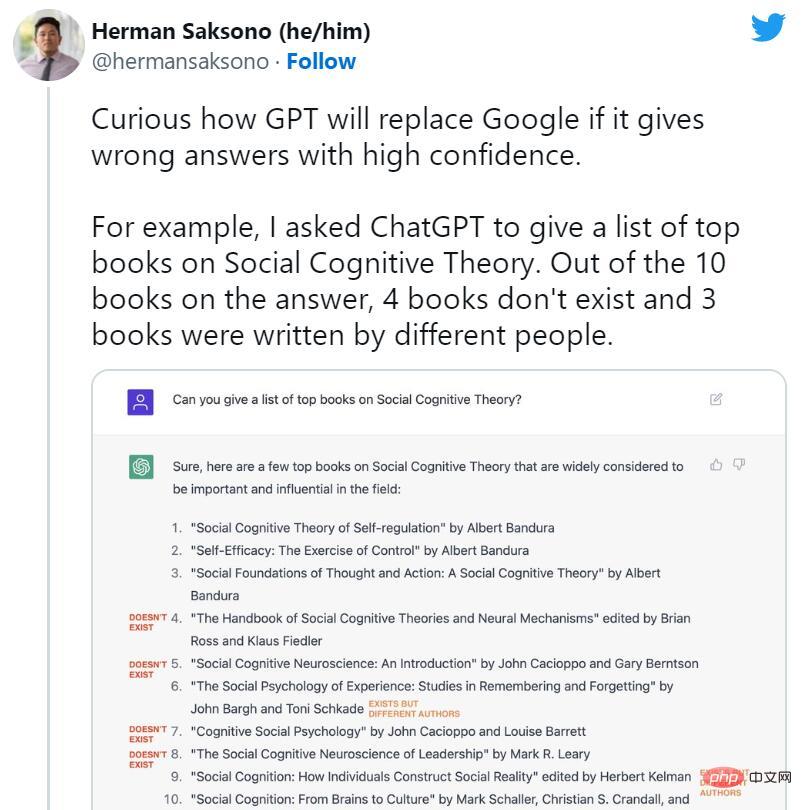
However, despite ChatGPT’s propensity for casual fibs, its suppression of fiction is exactly why we’re talking about it today. Some experts point out that ChatGPT is technically an improvement over the regular GPT-3 (its predecessor model) in that it can refuse to answer some questions or let you know when its answers may be inaccurate.
Riley Goodside, an expert in large-scale language models and prompt engineer at Scale AI, said, “A major factor in ChatGPT’s success is that it successfully suppresses fiction and makes many common problems unobtrusive. Compared to its predecessors, ChatGPT is significantly less prone to making things up."
If used as a brainstorming tool, ChatGPT's logical leaps and make-believe could lead to creative breakthroughs. But when used as a factual reference, ChatGPT can do real harm, and OpenAI knows this.
Shortly after the model was released, OpenAI CEO Sam Altman tweeted, "ChatGPT is very limited in functionality, but good enough in some ways to create a great misleading Impression. It would be a mistake to rely on it for anything important now. This is a preview of progress; we still have a lot of work to do in terms of robustness and authenticity."
In a later tweet In the article, he also wrote, "It does know a lot, but the danger is that it is blindly confident and wrong for a large part of the time."
What is going on?
In order to understand how GPT models like ChatGPT or Bing Chat are "fictionalized", we must know how the GPT model works. While OpenAI has yet to release technical details for ChatGPT, Bing Chat or even GPT-4, we do expect to see research papers introducing GPT-3 (their predecessor) in 2020.
Researchers build (train) large language models such as GPT-3 and GPT-4 by using a process called "unsupervised learning," which means that the data they use to train the model is not specially annotated or mark. In this process, the model is fed a large amount of text (millions of books, websites, articles, poems, manuscripts, and other sources) and repeatedly tries to predict the next word in each sequence of words. If the model's prediction is close to the actual next word, the neural network updates its parameters to reinforce the pattern that led to that prediction.
Conversely, if the prediction is incorrect, the model adjusts parameters to improve performance and tries again. This process of trial and error, although a technique called backpropagation, allows the model to learn from its mistakes and gradually improve its predictions during training.
Therefore, GPT learns the statistical association between words and related concepts in the data set. Some, like OpenAI chief scientist Ilya Sutskever, believe that the GPT model goes further than this and builds an internal model of reality so that they can more accurately predict the next best token, but this idea is controversial of. The exact details of how the GPT model proposes the next token in its neural network remain uncertain.

In the current wave of GPT models, this core training (now often called "pre-training") only happens once. After this, one can use the trained neural network in "inference mode", which allows the user to feed input into the trained network and get the results. During inference, the input sequence to the GPT model is always provided by a human, which is called a "prompt". The prompt determines the output of the model, and changing the prompt even slightly can drastically change the results produced by the model.
For example, if you prompt GPT-3 "Mary had a...", it will usually complete the sentence with "little lamb". This is because there are probably tens of thousands of examples of "Mary had a little lamb" in GPT-3's training data set, making it a reasonable output. But if you add more context to the prompt, such as "In the hospital, Mary had a", the results will change and return something like "baby" or "series of tests" word.
This is what’s interesting about ChatGPT, because it’s set up as a conversation with an agent, not just a direct text generation job. In the case of ChatGPT, the input prompt is the entire conversation you have with ChatGPT, starting with your first question or statement, including any specific instructions provided to ChatGPT before the simulated conversation begins. During this process, ChatGPT maintains a short-term memory (called a "context window") about it and everything you've written, and while it's "talking" to you, it's trying to complete the text generation task of the conversation.
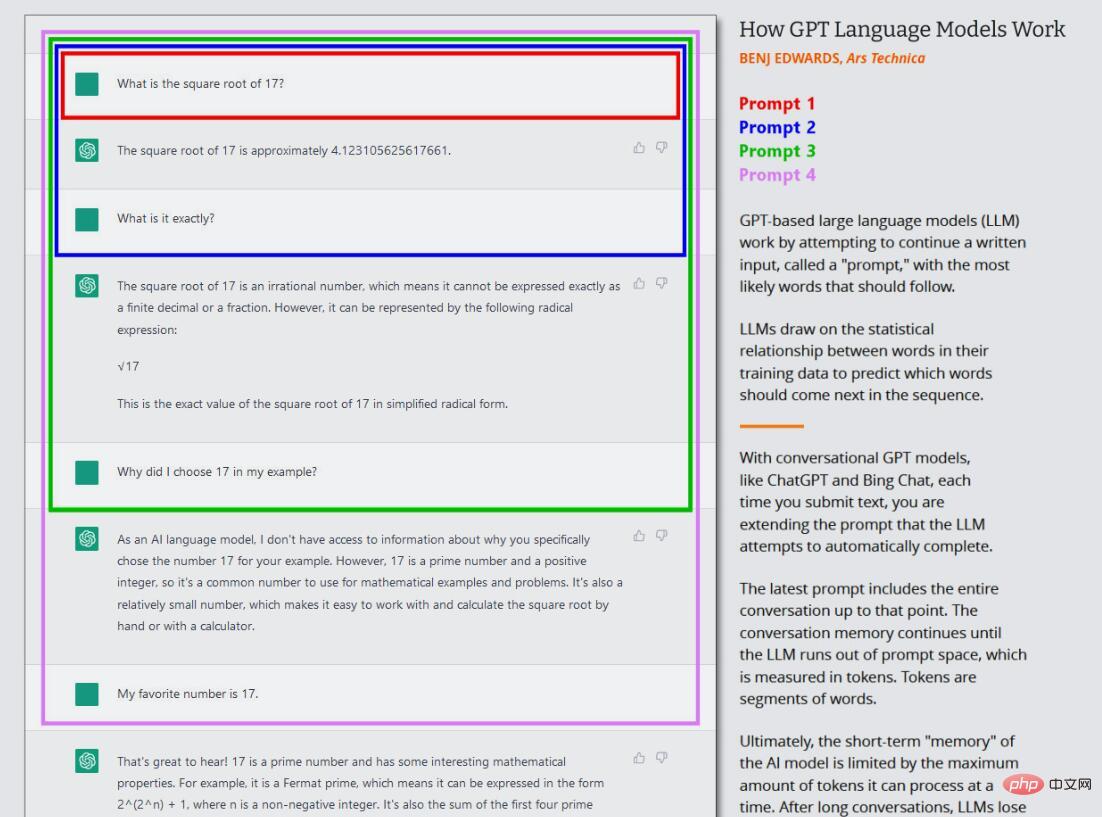
Additionally, ChatGPT is different from ordinary GPT-3 in that it is also trained on conversational text written by humans. OpenAI writes on its initial ChatGPT launch page, “We trained an initial model using supervised fine-tuning: human AI trainers provide conversations in which they act as both parties – the user and the AI. Assistant. We provide trainers with model writing suggestions to help them compose their own responses."
ChatGPT is also updated using a technique called Reinforcement Learning with Human Feedback (RLHF) Big Tweak, a technique in which human raters rank ChatGPT responses based on preference and then feed this information back into the model. Through RLHF, OpenAI is able to instill in the model the goal of “avoiding answering questions that cannot be answered accurately.” This allows ChatGPT to produce consistent responses with less fiction than the base model. But inaccurate information can still slip through.
Essentially, there is nothing in the original data set of the GPT model to distinguish fact from fiction.
The behavior of LLMs remains an active area of research. Even the researchers who created these GPT models are still discovering surprising properties of the technology that no one predicted when they were first developed. GPT's ability to do many of the interesting things we see now, such as language translation, programming and playing chess, once surprised researchers.
So when we ask why ChatGPT produces artifacts, it's hard to find a precise technical answer. Because neural network weights have a "black box" element, it is difficult (or even impossible) to predict their accurate output when given a complex prompt. Nonetheless, we do know some basic reasons why fiction occurs.
Ключом к пониманию вымышленных возможностей ChatGPT является понимание его роли как машины прогнозирования. Когда ChatGPT составляется, он ищет информацию или анализ, которых нет в наборе данных, и заполняет пробелы правдоподобно звучащими словами. ChatGPT особенно хорош в придумывании из-за огромного объема данных, которые ему приходится обрабатывать, и его способности так хорошо собирать контекст слова, что помогает ему легко размещать сообщения об ошибках в окружающем тексте.
Разработчик программного обеспечения Саймон Уиллисон сказал: «Я думаю, что лучший способ думать о художественной литературе — это думать о природе больших языковых моделей: единственное, что они умеют делать, — это выбирать следующую лучшую вещь на основе обучающий набор, основанный на статистической вероятности слов.»
В статье 2021 года три исследователя из Оксфордского университета и OpenAI определили два основных типа лжи, которую могут создавать LLM, такие как ChatGPT. Первый исходит из неточного исходного материала в наборе обучающих данных, например, из-за распространенных заблуждений (например, «поедание индейки вызывает сонливость»). Второй возникает в результате умозаключений о конкретных ситуациях, которых нет в наборе обучающих данных; он подпадает под упомянутый ранее ярлык «галлюцинации».
Дает ли модель GPT неожиданные предположения, зависит от того, что исследователи ИИ называют атрибутом «температуры», который часто называют настройкой «творчества». Если креативность установлена на высоком уровне, модель будет делать неверные предположения; если она установлена на низком уровне, она будет детерминированно выдавать данные на основе своего набора данных.
Недавно сотрудник Microsoft Михаил Парахин зашел в Twitter, чтобы рассказать о склонности Bing Chat к галлюцинациям и о том, что вызывает галлюцинации. Он написал: «Это то, что я пытался объяснить раньше: иллюзия = творчество. Он пытается создать продолжение строки с наибольшей вероятностью, используя все данные, которые он обрабатывает. Обычно это правильно. Иногда люди никогда не делали такого продолжения».
Парахин добавил, что именно эти сумасшедшие творческие скачки делают LLM интересным. Вы можете подавить галлюцинации, но вам это покажется очень скучным. Потому что он всегда отвечает «Не знаю» или возвращает только то, что есть в результатах поиска (что тоже иногда неверно). Чего сейчас не хватает, так это тона: в таких ситуациях он не должен выглядеть таким уверенным. "
Когда дело доходит до тонкой настройки языковой модели, такой как ChatGPT, баланс между креативностью и точностью является непростой задачей. С одной стороны, способность находить творческие ответы делает ChatGPT мощным инструментом для генерации новых идей. или устранение писательского тупика. Это также делает модель более человечной. С другой стороны, точность исходного материала имеет решающее значение, когда речь идет о получении достоверной информации и избегании вымысла. Для разработки языковой модели необходимо найти правильный баланс между двумя баланс информации, но полученная нейронная сеть составляет лишь часть размера. В широко читаемой статье в New Yorker автор Тед Чан назвал ее «размытым сетевым JPEG». Это означает, что большая часть фактических данных обучения потеряна, но GPT-3 компенсирует это, изучая отношения между понятиями, которые он позже может использовать для переформулирования новых структур этих фактов. Точно так же, как человек с дефектной памятью действует на основе догадок, он иногда ошибается. Конечно, если он не знает ответа, он дает лучшее предположение.
Мы не можем забывать о роли подсказок в художественной литературе. В некотором смысле ChatGPT является зеркалом: что вы ему даете, он дает вам. Если если вы кормите его ложью, он будет склонен соглашаться с вами и «думать» в этом направлении. Вот почему он не реагирует при смене темы или встрече с нежелательным ответом. Важно начать все сначала с новой подсказки. ChatGPT является вероятностным, что означает, что он частично случайен по своей природе. То, что он выводит, может меняться между сеансами, даже с одним и тем же приглашением.
Все это приводит к одному выводу, с которым согласен OpenAI: ChatGPT, как сейчас разработан, не является надежным источником фактической информации, и ему нельзя доверять.Исследователь и главный специалист по этике компании Hugging Face, занимающейся искусственным интеллектом, доктор Маргарет Митчелл считает: «ChatGPT может быть очень полезен для определенных вещей, таких как уменьшение писательского тупика или придумывание креативные идеи. Он не был создан для истины и поэтому не может быть истиной. Это так просто. "
Можно ли исправить ложь?
Так как же OpenAI планирует сделать ChatGPT более точным? За последние несколько лет мы связывались с OpenAI несколько раз в течение месяца об этой проблеме, но не получил ответа. Но мы можем найти подсказки в документах, опубликованных OpenAI, и новостных сообщениях о попытках компании заставить ChatGPT согласовываться с сотрудниками-людьми.
Как упоминалось ранее, одна из причин успеха ChatGPT заключается в его обширном обучении с использованием RLHF. OpenAI объясняет: «Чтобы сделать наши модели более безопасными, полезными и последовательными, мы используем существующую технологию под названием «Обучение с подкреплением с обратной связью с человеком» (RLHF). Согласно советам, отправленным клиентами в API, наш тегировщик обеспечивает демонстрацию желаемое поведение модели и сортирует несколько выходных данных модели. Затем мы используем эти данные для точной настройки GPT-3".
Сутскевер из OpenAI считает, что с помощью RLHF дополнительное обучение может помочь справиться с галлюцинациями. «Я очень надеюсь, что простое улучшение этого последующего RLHF научит его не галлюцинировать», — сказал Суцкевер Forbes в начале этого месяца. продолжил: «Сегодня мы нанимаем людей, чтобы они научили наши нейронные сети реагировать, научили чат-инструмент реагировать. Вы просто взаимодействуете с ним, и он учится на ваших реакциях. О, это не то, чего вы хотите. . Вы недовольны результатом. Поэтому результат не очень хороший, и в следующий раз следует сделать что-то другое. Я думаю, что это большое изменение, и этот метод сможет полностью решить проблему галлюцинаций."
Другие не согласны. Ян ЛеКун, главный ученый по искусственному интеллекту в Meta, считает, что нынешний LLM, использующий архитектуру GPT, не может решить проблему галлюцинаций. Но есть новый метод, который может повысить точность LLM при нынешней архитектуре. Он объясняет: "Одним из наиболее активно исследуемых подходов к добавлению реализма в LLM является расширение поиска - предоставление моделям внешних документов в качестве источников и вспомогательного контекста. С помощью этого метода исследователи надеются научить модель использовать внешние документы, такие как поисковые системы Google. , как и исследователи-люди, ссылайтесь в ответах на надежные источники и меньше полагайтесь на ненадежные фактические знания, полученные в ходе обучения модели».
 Bing Chat и Google Bard уже поддерживают веб-поиск. Имея это в виду, вскоре появится версия с поддержкой браузера. ChatGPT также будет реализован. Кроме того, плагин ChatGPT предназначен для дополнения данных обучения GPT-4 путем получения информации из внешних источников, таких как Интернет и специальные базы данных. Это улучшение аналогично тому, как люди с энциклопедией будут описывать факты более точно, чем люди без энциклопедии.
Bing Chat и Google Bard уже поддерживают веб-поиск. Имея это в виду, вскоре появится версия с поддержкой браузера. ChatGPT также будет реализован. Кроме того, плагин ChatGPT предназначен для дополнения данных обучения GPT-4 путем получения информации из внешних источников, таких как Интернет и специальные базы данных. Это улучшение аналогично тому, как люди с энциклопедией будут описывать факты более точно, чем люди без энциклопедии.
The above is the detailed content of Why ChatGPT and Bing Chat are so good at spinning stories. For more information, please follow other related articles on the PHP Chinese website!
 ChatGPT registration
ChatGPT registration
 Domestic free ChatGPT encyclopedia
Domestic free ChatGPT encyclopedia
 How to install chatgpt on mobile phone
How to install chatgpt on mobile phone
 Can chatgpt be used in China?
Can chatgpt be used in China?
 Introduction to commonly used top-level domain names
Introduction to commonly used top-level domain names
 What is the encoding used inside a computer to process data and instructions?
What is the encoding used inside a computer to process data and instructions?
 busyboxv1.30.1 cannot boot
busyboxv1.30.1 cannot boot
 How to solve the 0x0000006b blue screen
How to solve the 0x0000006b blue screen








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



