


The new generation HCC high-performance computing cluster uses the latest generation of Xinghai self-developed servers and is equipped with NVIDIA H800 Tensor Core GPU.
Tencent officials said that the cluster is based on self-developed network and storage architecture, bringing 3.2T ultra-high interconnect bandwidth, TB-level throughput capacity and tens of millions of IOPS. Actual measurement results show that the computing power performance of the new generation cluster is improved by 3 times compared with the previous generation.
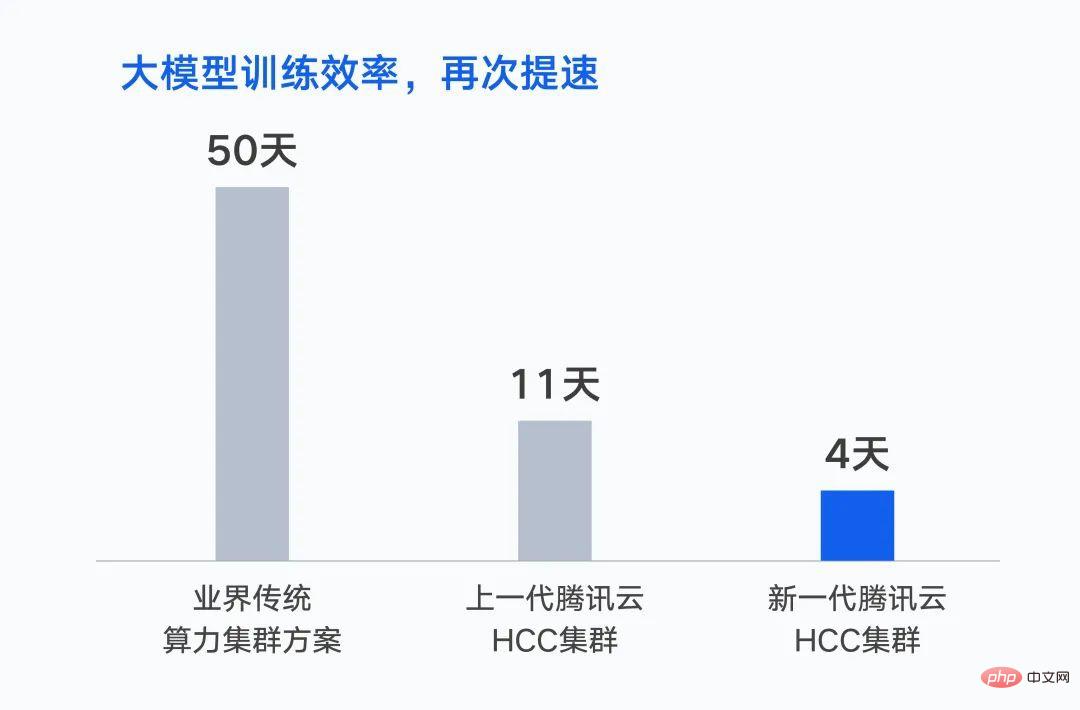
In October last year, Tencent completed the training of the first large-scale AI model with one trillion parameters - the Hunyuan NLP large model. With the same data set, the training time is shortened from 50 days to 11 days. If based on a new generation cluster, the training time will be further reduced to 4 days.
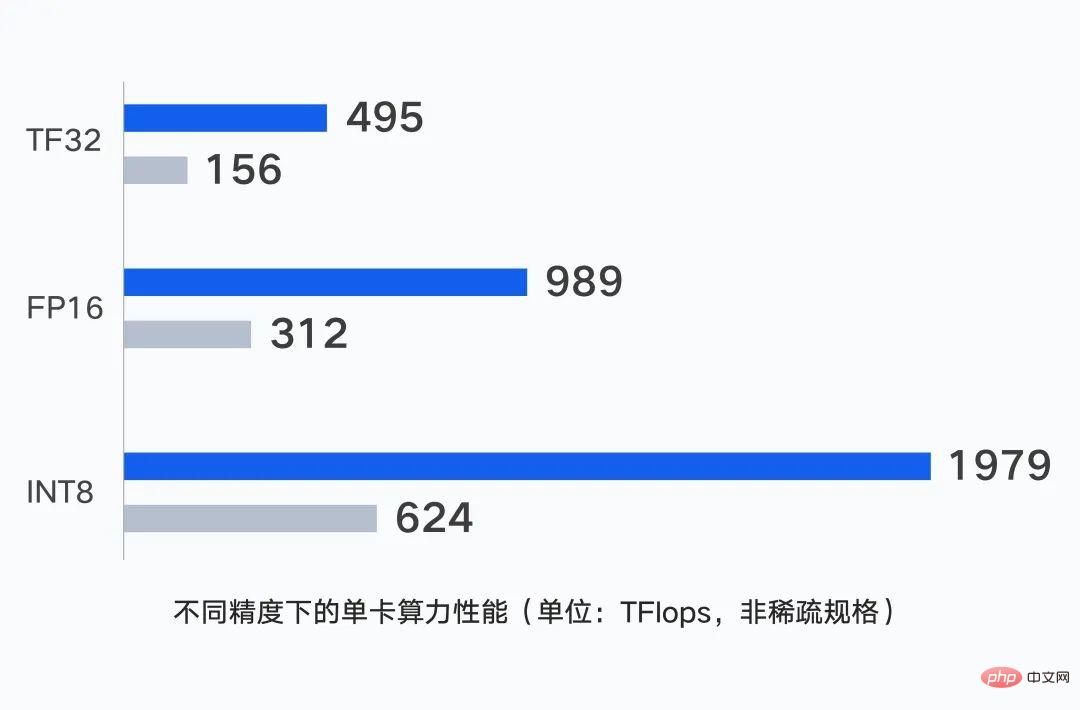
At the computing level, server stand-alone performance is the basis of cluster computing power. The single GPU card of Tencent Cloud's new generation cluster supports output of up to 1979 TFlops of computing power under different precisions.
For large model scenarios, Xingxinghai’s self-developed server adopts a 6U ultra-high-density design, which is 30% higher than the industry’s supported shelf density; using the parallel computing concept, through the integrated design of CPU and GPU nodes, Improve single-point computing power performance to a higher level.
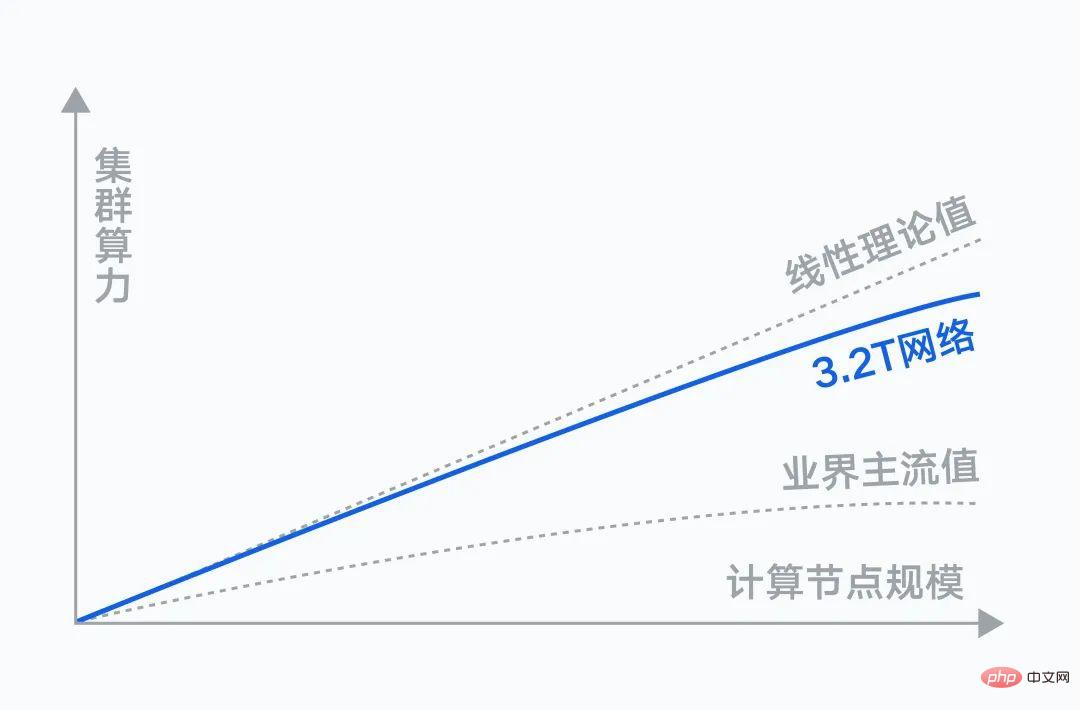
#At the network level, there are massive data interaction requirements between computing nodes. As the cluster scale expands, communication performance will directly affect training efficiency, requiring maximum collaboration between the network and computing nodes.
Tencent’s self-developed Xingmai high-performance computing network claims to have the industry’s highest 3.2T RDMA communication bandwidth. Actual measurement results show that equipped with the same number of GPUs, the 3.2T Xingmai network has a 20% increase in the overall computing power of the cluster compared to the 1.6T network.
At the same time, Tencent’s self-developed high-performance collective communication library TCCL is integrated into custom-designed solutions. Compared with the industry's open source collective communication library, it optimizes 40% load performance for large model training and eliminates training interruption problems caused by multiple network reasons.
At the storage level, during large model training, a large number of computing nodes will read a batch of data sets at the same time. It is necessary to shorten the data loading time as much as possible to avoid waiting for computing nodes.
Tencent Cloud’s self-developed storage architecture has terabyte-level throughput capabilities and tens of millions of IOPS, supporting storage needs in different scenarios. COS GooseFS object storage solution and CFS Turbo high-performance file storage solution fully meet the high performance, large throughput and massive storage requirements in large model scenarios.

In addition, the new generation cluster integrates Tencent Cloud’s self-developed TACO training acceleration engine, which performs a large number of system-level optimizations on network protocols, communication strategies, AI frameworks, and model compilation. Significantly save training tuning and computing power costs.
AngelPTM, the training framework behind Tencent’s Hunyuan large model, has also provided services through Tencent Cloud TACO to help enterprises accelerate the implementation of large models.
Through the large model capabilities and toolbox of Tencent Cloud TI platform, enterprises can conduct fine-tuned training based on industrial scenario data, improve production efficiency, and quickly create and deploy AI applications.
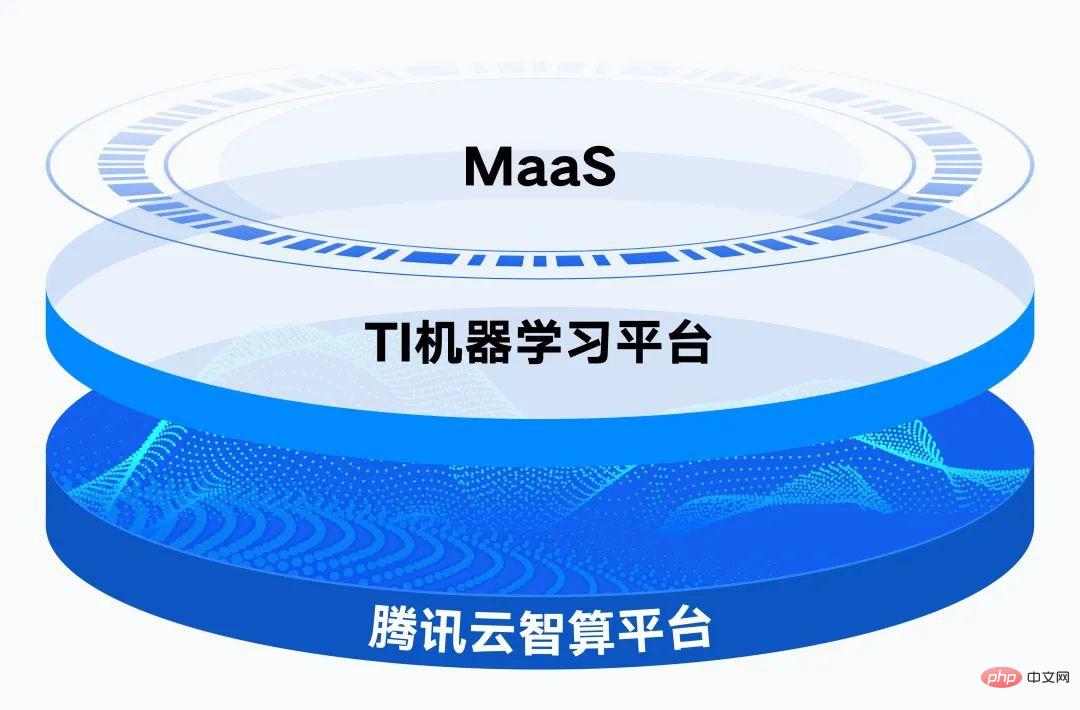
Relying on the distributed cloud-native governance capabilities, Tencent Cloud Intelligent Computing Platform provides 16 EFLOPS of floating-point computing power.
The above is the detailed content of Tencent releases a new generation of super computing cluster: for large model training, performance increased by 3 times. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



