


arXiv paper "Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline", June 2022, Shanghai AI Laboratory and Shanghai Jiao Tong University.

Current end-to-end autonomous driving methods either run controllers based on planned trajectories or directly perform control predictions, which spans two research areas. In view of the potential mutual benefits between the two, this article actively explores the combination of the two, called TCP (Trajectory-guided Control Prediction). Specifically, the ensemble method has two branches, respectively for trajectory planning and direct control. The trajectory branch predicts future trajectories, while the control branch involves a new multi-step prediction scheme reasoning about the relationship between current actions and future states. The two branches are connected so that the control branch receives corresponding guidance from the trajectory branch at each time step. The outputs of the two branches are then fused to achieve complementary advantages.
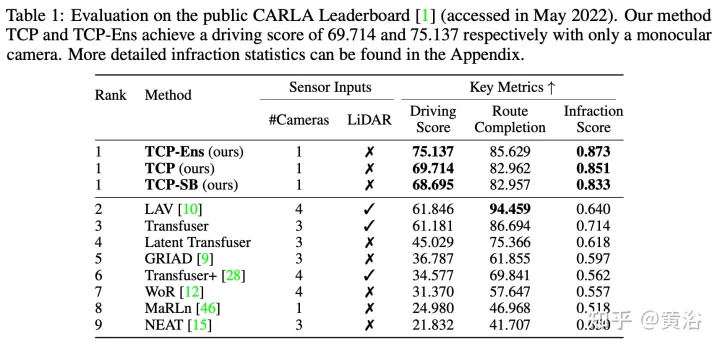
Evaluation using the Carla simulator in a closed-loop urban driving environment with challenging scenarios. Even with monocular camera input, this method ranks first in the official CARLA rankings. Source code and data will be open source: https://github.com/OpenPerceptionX/TCP
Choose Roach (“End-to-end urban driving by imitating a reinforcement learning coach“. ICCV, 2021) as an expert. Roach is a simple model trained by RL with privileged information including roads, lanes, routes, vehicles, pedestrians, traffic lights and stations, all rendered as 2D BEV images. Compared with hand-crafted experts, such learning-based experts can convey more information besides direct supervision signals. Specifically, there is a feature loss, which forces the latent features before the final output head of the student model to be similar to those of the experts. A value loss is also added as an auxiliary task for the student model to predict expected returns.
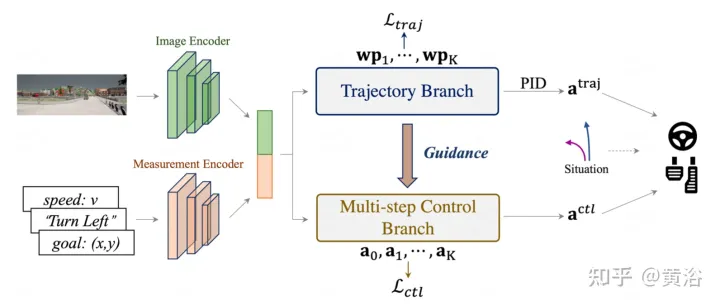
As shown in the figure, the entire architecture consists of an input encoding stage and two subsequent branches: the input image i is passed through a CNN-based image encoder, such as ResNet, to generate a feature map F. At the same time, the navigation information g is concatenated with the current speed v to form the measurement input m, and then the MLP-based measurement encoder takes m as its input and outputs the measurement feature jm. The encoding features are then shared by both branches for subsequent trajectory and control predictions. Specifically, Control Branch is a new multi-step prediction design with guidance from Trajectory Branch. Finally, a scenario-based fusion scheme is adopted to combine the best of both output paradigms.
As shown in the figure, TCP seeks the help of the trajectory planning branch by learning the attention map to extract important information from the encoded feature map. The interaction between the two branches (trajectory and control) enhances the consistency of these two closely related output paradigms and further elaborates the spirit of multi-task learning (MTL). Specifically, the image encoder F is utilized to extract the 2D feature map at time step t, and the corresponding hidden states from the control branch and the trajectory branch are used to calculate the attention map.
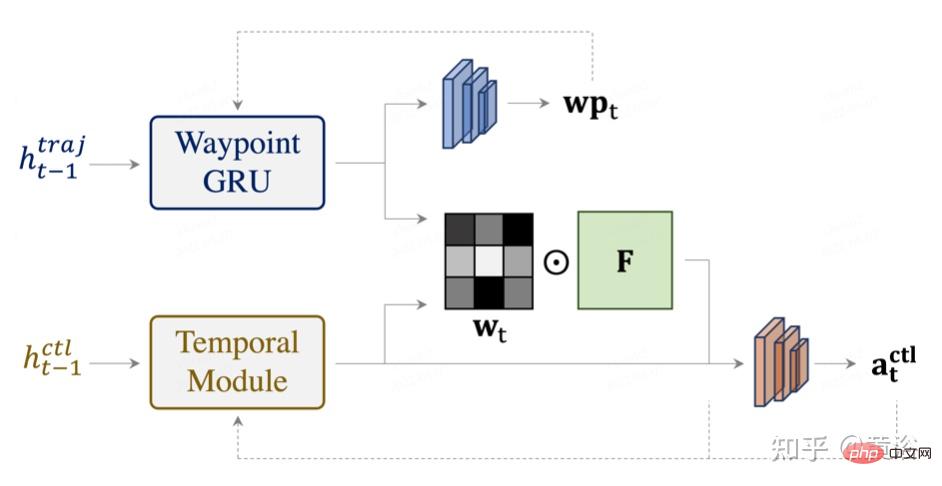
# Information representation features are input into the strategy header, which is shared among all time t steps to predict the corresponding control actions. Note that for the initial step, only measured features are used to calculate the initial attention map, and the attention image features are combined with the measured features to form an initial feature vector. To ensure that the features indeed describe the state of that step and contain important information for controlling predictions, a feature loss is added at each step so that the initial feature vectors are also close to the expert's features.
The TCP framework has two forms of output representation: planning trajectory and predictive control. For further combination, a scenario-based fusion strategy is designed, as shown in the pseudocode of Algorithm 1.

Specifically, α is represented as a combined weight, with a value between 0 and 0.5. According to the prior belief, in some cases one representation is more suitable. By averaging the weight α, the trajectory and control The predicted results are combined, and the more suitable one occupies more weight (1 − α). Note that the combination weight α does not need to be constant or symmetric, which means that it can be set to different values in different situations, or for specific control signals. In the experiments, scenes were selected based on whether the self-vehicle turned, meaning that if it turned, the scene was control-specific, otherwise it was trajectory-specific.
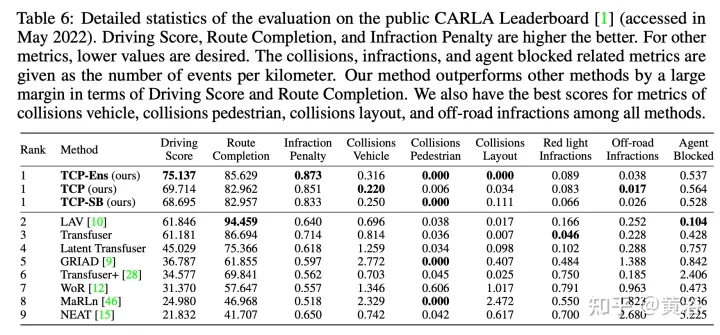
The experimental results are as follows:
The above is the detailed content of Control prediction for trajectory guidance in end-to-end autonomous driving: a simple and powerful baseline method TCP. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



