


For many tasks in autonomous driving, it is easier to complete from a top-down, map or bird's eye view (BEV) perspective. Since many autonomous driving topics are restricted to the ground plane, a top view is a more practical low-dimensional representation and is ideal for navigation, capturing relevant obstacles and hazards. For scenarios like autonomous driving, semantically segmented BEV maps must be generated as instantaneous estimates to handle freely moving objects and scenes that are visited only once.
To infer BEV maps from images, one needs to determine the correspondence between image elements and their positions in the environment. Some previous research used dense depth maps and image segmentation maps to guide this conversion process, and other research extended the method of implicitly parsing depth and semantics. Some studies exploit camera geometric priors but do not explicitly learn the interaction between image elements and BEV planes.
In a recent paper, researchers from the University of Surrey introduced an attention mechanism to convert 2D images of autonomous driving into a bird's-eye view, improving the model's recognition accuracy. 15%. This research won the Outstanding Paper Award at the ICRA 2022 conference that concluded not long ago.

##Paper link: https://arxiv.org/pdf/2110.00966.pdf

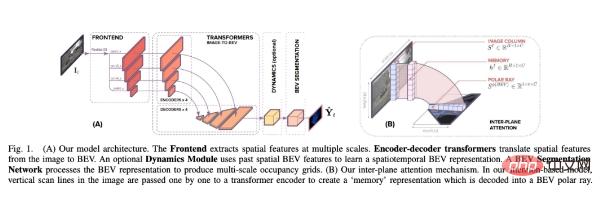
Different from previous methods, this study treats BEV conversion as an "Image-to-World" conversion problem, whose goal is to learn the alignment between vertical scan lines in the image and polar rays in the BEV. Therefore, this projective geometry is implicit to the network.
In the alignment model, the researchers adopted Transformer, an attention-based sequence prediction structure. Leveraging their attention mechanism, we explicitly model the pairwise interaction between vertical scan lines in an image and their polar BEV projections. Transformers are well suited for image-to-BEV translation problems because they can reason about the interdependencies between objects, depth, and scene lighting to achieve globally consistent representations.
The researchers embed the Transformer-based alignment model into an end-to-end learning formula that takes the monocular image and its intrinsic matrix as input, and then Predict semantic BEV mapping of static and dynamic classes.
This paper builds an architecture that helps predict semantic BEV mapping from monocular images around an alignment model. As shown in Figure 1 below, it contains three main components: a standard CNN backbone to extract spatial features on the image plane; an encoder-decoder Transformer to convert the features on the image plane into BEV; and finally a segmentation network Decode BEV features into semantic maps.

Specifically, the main contributions of this study are:
In the experiment, the researchers made several evaluations: Image to BEV conversion was evaluated as a conversion problem on the nuScenes dataset Its utility; ablating backtracking directions in monotonic attention, assessing the utility of long sequence horizontal context and the impact of polar positional information. Finally, the method is compared with SOTA methods on nuScenes, Argoverse, and Lyft datasets.
Ablation experiment
As shown in the first part of Table 2 below, the researchers compared soft attention (looking both ways), monotonic attention looking back at the bottom of the image (looking down), monotonic attention looking back at the top of the image (looking up). The results show that looking down from a point in the image is better than looking up.
Along local texture clues - This is consistent with the way humans try to determine the distance of objects in urban environments, we will use the object and the ground plane intersection location. The results also show that observation in both directions further improves accuracy, making deep inference more discriminative.

The utility of long sequence horizontal context. The image-to-BEV conversion here is done as a set of 1D sequence-to-sequence conversions, so one question is what happens when the entire image is converted to BEV. Considering the secondary computation time and memory required to generate attention maps, this approach is prohibitively expensive. However, the contextual benefits of using the entire image can be approximated by applying horizontal axial attention on image plane features. With axial attention through the image lines, pixels in vertical scan lines now have long-range horizontal context, and then long-range vertical context is provided by transitioning between 1D sequences as before.
As shown in the middle part of Table 2, merging long sequence horizontal context does not benefit the model, and even has a slight adverse effect. This illustrates two points: first, each transformed ray does not require information about the entire width of the input image, or rather, the long sequence context does not provide any additional information compared to the context already aggregated by the front-end convolution. benefit. This shows that using the entire image to perform the transformation will not improve the model accuracy beyond the baseline constraint formula; in addition, the performance degradation caused by the introduction of horizontal axial attention means the difficulty of using attention to train sequences of image width, as can be seen, It will be more difficult to train using the entire image as the input sequence.
Polar-agnostic vs polar-adaptive Transformers: The last part of Table 2 compares Po-Ag vs. Po -Variations of Ad. A Po-Ag model has no polarization position information, the Po-Ad of the image plane includes polar encodings added to the Transformer encoder, and for the BEV plane, this information is added to the decoder. Adding polar encodings to either plane is more beneficial than adding it to the agnostic model, with the dynamic class adding the most. Adding it to both planes further enforces this, but has the greatest impact on static classes.
Comparison with SOTA methods
The researcher compared the method in this article with some SOTA methods. As shown in Table 1 below, the performance of the spatial model is better than the current compressed SOTA method STA-S, with an average relative improvement of 15%. On the smaller dynamic classes, the improvement is even more significant, with bus, truck, trailer, and obstacle detection accuracy all increasing by a relative 35-45%.

The qualitative results obtained in Figure 2 below also support this conclusion. The model in this article shows greater structural similarity and better shape sense. This difference can be partly attributed to the fully connected layers (FCL) used for compression: when detecting small and distant objects, much of the image is redundant context.

#In addition, pedestrians and other objects are often partially blocked by vehicles. In this case, the fully connected layer will tend to ignore pedestrians and instead maintain the semantics of vehicles. Here, the attention method shows its advantage because each radial depth can be independently noticed in the image - so that deeper depths can make the bodies of pedestrians visible, while previous depths can only notice vehicles.
The results on the Argoverse dataset in Table 3 below show a similar pattern, in which our method improves by 30% compared to PON [8].

As shown in Table 4 below, the performance of this method on nuScenes and Lyft is better than LSS [9] and FIERY [20]. A true comparison is impossible on Lyft because it doesn't have a canonical train/val split, and there's no way to get the split used by LSS.

For more research details, please refer to the original paper.
The above is the detailed content of ICRA 2022 Outstanding Paper: Converting 2D images of autonomous driving into a bird's-eye view, the model recognition accuracy increases by 15%. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



