


Author: Luo Ying, Xu Jun, Xie Rui, etc.
CLUE(Chinese Language Understanding Evaluation)[1]is the authoritative evaluation list of Chinese language understanding. It includes many semantic analysis and semantic understanding subtasks such as text classification, inter-sentence relationships, and reading comprehension. It has had a great impact on both academia and industry.

Figure 1 FewCLUE list (as of 2022-04-18)
FewCLUE[2,3]is a sublist in CLUE specifically used for Chinese small sample learning evaluation. It aims to combine the universal and powerful generalization capabilities of pre-trained language models to explore the best small sample learning model and its application in Chinese. practice on. Some of FewCLUE's data sets only have more than a hundred labeled samples, which can measure the generalization performance of the model under very few labeled samples. After its release, it attracted the attention of NetEase, WeChat AI, Alibaba, IDEA Research Institute, and Inspur Artificial Intelligence Research. The institute and many other enterprises and research institutes participated. Not long ago, the small sample learning model FSL of the Semantic Understanding Team of the NLP Center of the Meituan Platform Search and NLP Department won first place on the FewCLUE list with its superior performance, reaching SOTA level.
Although the large-scale pre-training model has achieved very good results in various major tasks, it still requires a lot of labeled data for specific tasks. . Meituan's various businesses have a wealth of NLP scenarios, which often require high manual labeling costs. In the early stages of business development or when new business needs need to be launched quickly, there will often be insufficient labeled samples. Use the depth of traditional Pretrain (Pre-training) Fine-Tune (Fine-tuning) Learning and training methods often fail to meet ideal index requirements, so it becomes very necessary to study the problem of model training in small sample scenarios.
This article proposes a set of joint training solutions for large models and small samples, FSL, which combines model optimization strategies such as model structure optimization, large-scale pre-training, sample enhancement, ensemble learning, and self-training. , and finally achieved excellent results on the FewCLUE list under the authoritative evaluation benchmark of Chinese language understanding, and its performance exceeded human levels on some tasks, while on some tasks (such as CLUEWSC) there are still certain Room for improvement.
After the release of FewCLUE, NetEase Fuxi used the self-developed EET model[4], and enhanced the semantic understanding of the model through secondary training, and then added templates for Multi-task learning; IDEA Research Institute’s Erlangshen model[5]uses more advanced pre-training technology to train large models based on the BERT model, and uses Masked with dynamic Mask strategy in the process of downstream task fine-tuning. Language Model (MLM) as an auxiliary task. These methods all use Prompt Learning as the basic task structure. Compared with these self-developed large models, our method mainly adds model optimization strategies such as sample enhancement, ensemble learning, and self-learning based on the Prompt Learning framework, which greatly improves Improve the task performance and robustness of the model. At the same time, this method can be applied to various pre-training models, making it more flexible and convenient.
The overall model structure of FSL is shown in Figure 2 below. The FewCLUE dataset provides 160 labeled data and nearly 20,000 unlabeled data for each task. In this FewCLUE practice, we first constructed multi-template Prompt Learning in the Fine-Tune stage, and used enhancement strategies such as adversarial training, contrastive learning, and Mixup for labeled data. Since these data enhancement strategies use different enhancement principles, it can be considered that the differences between these models are relatively significant and will have better results after integrated learning. Therefore, after using the data enhancement strategy for training, we have multiple weakly supervised models, and use these weakly supervised models to predict on unlabeled data to obtain the pseudo-label distribution of unlabeled data. After that, we integrate multiple pseudo-label distributions of unlabeled data predicted by different data augmentation models to obtain a total pseudo-label distribution of unlabeled data, then reconstruct the multi-template Prompt Learning and use the data again Enhance the strategy and choose the optimal strategy. Currently, our experiment only carries out one iteration, and we can also try multiple iterations. However, as the number of iterations increases, the improvement will no longer be obvious.

Figure 2 FSL model framework
The pre-training language model is trained on a huge unlabeled corpus. For example, RoBERTa[6]is trained on more than 160GB of text, including encyclopedias, news articles, literary works, and web content. The representations learned by these models achieve excellent performance on tasks involving datasets of various sizes from multiple sources.
The FSL model uses the RoBERTa-large model as the basic model, and adopts Domain-Adaptive Pretraining (DAPT)[7]## that incorporates domain knowledge. #Pre-training method and Task-Adaptive Pretraining that incorporates task knowledge (TAPT)[7]. DAPT aims to add a large amount of unlabeled text in the field to continue training the language model based on the pre-trained model, and then fine-tune it on the data set of the specified task.
Continuing pre-training on the target text domain can improve the performance of the language model, especially on downstream tasks related to the target text domain. Moreover, the higher the correlation between the pre-training text and the task domain, the greater the improvement. In this practice, we finally used RoBERTa Large, which was pre-trained on 100G CLUE Vocab[8]that contains corpus from various fields such as entertainment programs, sports, health, international affairs, movies, celebrities, etc. Model. TAPT refers to adding a small amount of unlabeled corpus that is directly related to the task on the basis of the pre-trained model for pre-training. For the TAPT task, the pre-training data we chose to use is the unlabeled data provided by the FewCLUE list for each task.
In addition, in the practice of inter-sentence relationship tasks, such as the Chinese natural language inference task OCNLI and the Chinese dialogue short text matching task BUSTM, we use other inter-sentence relationships For tasks such as the Chinese natural language inference data set CMNLI and the Chinese short text similarity data set LCQMC, the model parameters pre-trained on the Chinese short text similarity data set LCQMC are used as initial parameters. Compared with directly using the original model to complete the task, it can also improve the effect to a certain extent.
2.2 Model structureFewCLUE contains a variety of task forms, and we have selected an appropriate model structure for each task. The category words of text classification tasks and machine reading comprehension (MRC)tasks themselves carry information, so they are more suitable to be modeled in the form of Masked Language Model (MLM); and the inter-sentence relationship The task of judging the relevance of two sentences is more similar to the Next Sentence Prediction(NSP)[9]task form. Therefore, we choose the PET[10]model for the classification task and reading comprehension task, and the EFL[11]model for the inter-sentence relationship task. The EFL method can construct negative samples through global sampling. , learn a more robust classifier.
2.2.1 Prompt LearningThe main goal of Prompt Learning is to minimize the gap between the pre-training target and the downstream fine-tuning target. Usually existing pre-training tasks include MLM loss functions, but downstream tasks do not use MLM, but introduce new classifiers, causing inconsistencies between pre-training tasks and downstream tasks. Prompt Learning does not introduce additional classifiers or other parameters, but transforms the task into an MLM form by splicing templates (Template, which means splicing language fragments for input data) and tag word mapping (Verbalizer , that is, finding the corresponding word in the vocabulary for each label, thereby setting the prediction target) for the MLM task, so that the model can be used in downstream tasks with a small number of samples.
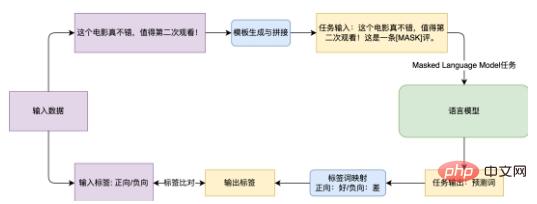
Figure 3 Flow chart of the Prompt Learning method to complete the sentiment analysis task
Take the e-commerce evaluation sentiment analysis task EPRSTMT shown in Figure 3 as an example. Given the text "This movie is really good and worth watching a second time!", the traditional text classification is to connect the classifier to the Embedding in the CLS part and map it to the 0-1 classification (0: negative, 1: Forward). This method requires training a new classifier in small sample scenarios, and it is difficult to achieve good results. The method based on Prompt Learning is to create a template "This is a [MASK] comment." and then splice the template with the original text. During training, the language model predicts the word at the [MASK] position, and then maps it to the corresponding category. Up (Good: Positive, Bad: Negative).
Determining the best performing templates and tag word mappings is sometimes difficult due to a lack of sufficient data. Therefore, the design of multi-template and multi-label word mapping can also be adopted. By designing multiple templates, the final result adopts the integration of the results of multiple templates, or designing a one-to-many tag word mapping so that one tag corresponds to multiple words. Similar to the above example, the following template combination can be designed (left: multiple templates for the same sentence, right: multiple tag mapping).

Figure 4 PET multi-template and multi-label mapping
Task sample

Table 1 PET template construction in FewCLUE dataset
The EFL model splices two sentences together and uses Embedding at the [CLS] position of the output layer followed by a classifier to complete the prediction. During the training process of EFL, in addition to the samples in the training set, negative samples are also constructed. During the training process, sentences in other data are randomly selected as negative samples in each batch, and data enhancement is performed by constructing negative samples. Although the EFL model needs to train a new classifier, there are currently many public text implication/inter-sentence relationship data sets, such as CMNLI, LCQMC, etc., which can be continuously learned on these samples (continue-train), then migrate the learned parameters to the small sample scenario, and use the task data set of FewCLUE for further fine-tuning.
Task examples

 Table 2 FewCLUE dataset EFL template construction
Table 2 FewCLUE dataset EFL template construction
Data enhancement methods mainly include sample enhancement and Embedding enhancement. In the field of NLP, the purpose of data augmentation is to expand text data without changing the semantics. The main methods include simple text replacement, using language models to generate similar sentences, etc. We have tried EDA and other methods to expand text data, but a change in a word may cause the meaning of the entire sentence to flip, and the replaced text carries a lot of noise. So it is difficult to generate enough augmented data with simple rule sample changes. Embedding enhancement, however, no longer operates on the input, but operates on the Embedding level. The robustness of the model can be improved by adding perturbation or interpolation to the Embedding.
Therefore, in this practice we mainly carry out Embedding enhancement. The data enhancement strategies we use include Mixup[12], Manifold-Mixup[13], and adversarial training (Adversarial training, AT)[ 14]and contrastive learning R-drop[15].
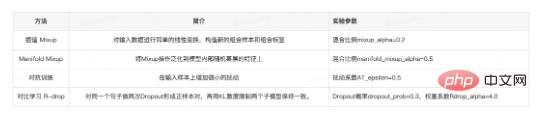
 Table 3 Brief description of data enhancement strategy
Table 3 Brief description of data enhancement strategy
Mixup constructs new combined samples and combined labels by performing simple linear transformation on the input data, which can enhance The generalization ability of the model. On various supervised or semi-supervised tasks, using Mixup can greatly improve the generalization ability of the model. The Mixup method can be regarded as a regularization operation, which requires that the combined features generated by the model at the feature level satisfy linear constraints, and uses this constraint to regularize the model. Intuitively, when the input of the model is a linear combination of the other two inputs, its output is also a linear combination of the output obtained after the two data are input into the model separately. In fact, the model is required to be approximately a linear system.
Manifold Mixup generalizes the above Mixup operation to features. Because features have higher-order semantic information, interpolation across their dimensions may produce more meaningful samples. In models similar to BERT[9]and RoBERTa[6], the number of layers k is randomly selected and Mixup interpolation is performed on the feature representation of this layer. The interpolation of ordinary Mixup occurs in the Embedding part of the output layer, and Manifold Mixup is equivalent to adding this series of interpolation operations to a random layer of the Transformers structure inside the language model.
Adversarial training significantly improves model loss by adding small perturbations to input samples. Adversarial training is to train a model that can effectively identify original samples and adversarial samples. The basic principle is to construct some adversarial samples by adding perturbations and give them to the model for training, thereby improving the robustness of the model when encountering adversarial samples, and at the same time improving the performance and generalization capabilities of the model. Adversarial examples need to have two characteristics, namely:
#R-Drop does Dropout twice for the same sentence, and forces the output probabilities of different sub-models generated by Dropout to remain consistent. Although the introduction of Dropout works well, it can lead to inconsistency problems in the training and inference processes. In order to alleviate the inconsistency of this training inference process, R-Drop regularizes Dropout, adds restrictions on the output data distribution in the output generated by the two sub-models, and introduces the KL divergence loss of the data distribution measure, so that within the batch The two data distributions generated by the same sample should be as close as possible and have distribution consistency. Specifically, for each training sample, R-Drop minimizes the KL divergence between the output probabilities of sub-models generated by different Dropouts. As a training idea, R-Drop can be used in most supervised or semi-supervised training and is highly versatile.
Among the three data enhancement strategies we use, Mixup is a linear change of two samples in the output layer Embedding of the language model and the output layer of a random layer of Transformers inside the language model. , Adversarial training is to add small perturbations to the samples, while contrastive learning is to do Dropout twice on the same sentence to form a positive sample pair, and then use KL divergence to limit the two sub-models to be consistent. All three strategies enhance the generalization of the model by completing some operations in Embedding. The models obtained through different strategies have different preferences, which provides conditions for the next step of ensemble learning.
Ensemble learning can combine multiple weakly supervised models in order to obtain a better and more comprehensive strongly supervised model. The underlying idea of ensemble learning is that even if a weak classifier makes a wrong prediction, other weak classifiers can correct the error. If the differences between the models to be combined are significant, then ensemble learning will usually produce a better result.
Self-training uses a small amount of labeled data and a large amount of unlabeled data to jointly train the model, first using the trained classifier to predict the label of all unlabeled data, and then selecting the confidence Labels with higher degrees are used as pseudo-label data, and the pseudo-labeled data is combined with manually labeled training data to retrain the classifier.
Ensemble learning Self-training is a solution that can utilize multiple models and unlabeled data. Among them, the general steps of ensemble learning are: train multiple different weakly supervised models, use each model to predict the label probability distribution of unlabeled data, calculate the weighted sum of the label probability distribution, and obtain the pseudo label probability distribution of unlabeled data. . Self-training refers to training a model to combine other models. The general steps are: train multiple Teacher models, the Student model learns the Soft Prediction of high-confidence samples in the pseudo-label probability distribution, and the Student model serves as the final strong learner.
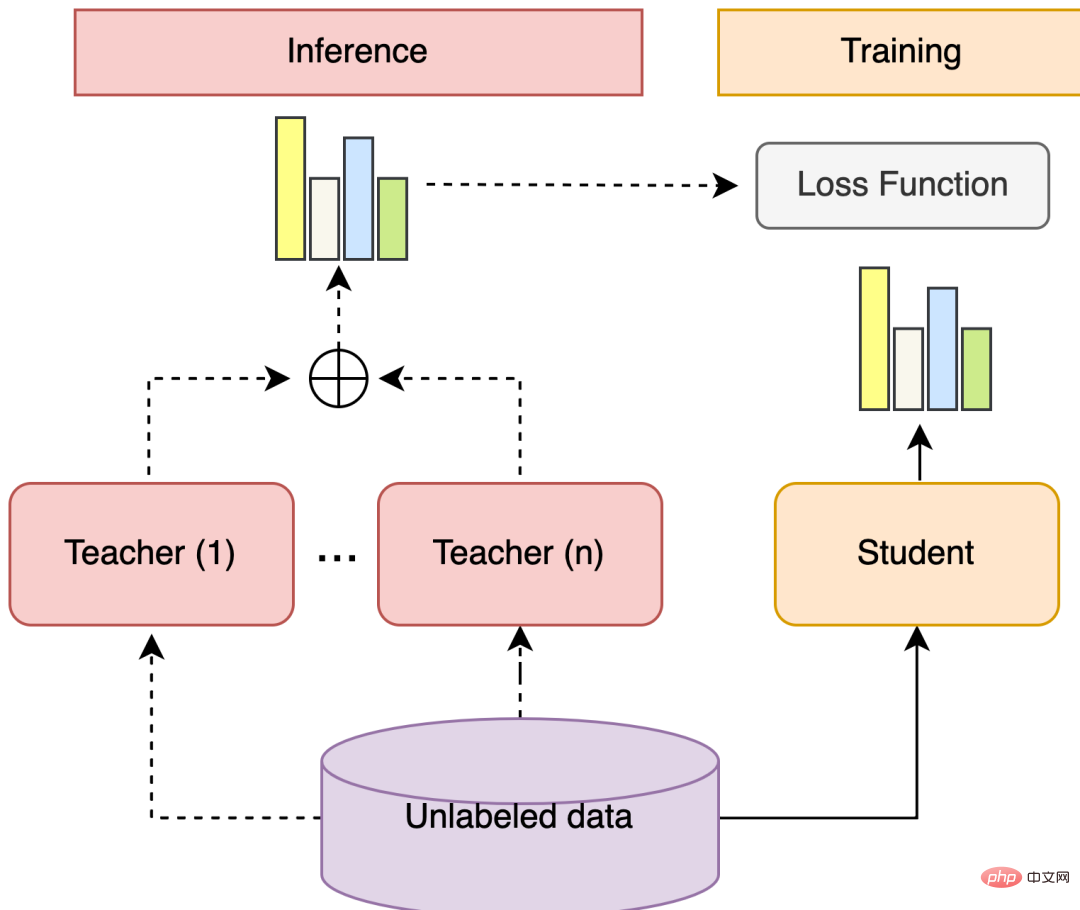
 Figure 5 Integrated learning self-training structure
Figure 5 Integrated learning self-training structure
In this FewCLUE practice, We first construct multi-template Prompt Learning in the Fine-Tune stage, and use enhancement strategies such as adversarial training, contrastive learning, and Mixup on labeled data. Since these data enhancement strategies use different enhancement principles, it can be considered that the differences between these models are relatively significant and will have better results after integrated learning.
After using the data enhancement strategy for training, we have multiple weakly supervised models, and use these weakly supervised models to predict on unlabeled data to obtain pseudo-unlabeled data. Label distribution. After that, we integrate multiple pseudo-label distributions of unlabeled data predicted by different data augmentation models to obtain a total pseudo-label distribution of unlabeled data. In the process of screening pseudo-label data, we will not necessarily select the sample with the highest confidence, because if the confidence given by each data augmentation model is very high, it means that this sample may be an easy-to-learn sample and does not necessarily have a large value.
We combine the confidence given by multiple data enhancement models and try to select samples with higher confidence but not easy to learn (For example, multiple models do not predict all Consistent). Then the multi-template Prompt Learning is reconstructed using the set of labeled data and pseudo-labeled data, the data augmentation strategy is used again, and the best strategy is selected. Currently, our experiment only carries out one iteration, and we can also try multiple iterations. However, as the number of iterations increases, the improvement will decrease and will no longer be significant.
FewCLUE list provides 9 tasks, including 4 text classification tasks and 2 1 inter-sentence relationship task and 3 reading comprehension tasks. Text classification tasks include e-commerce evaluation sentiment analysis, scientific document classification, news classification and App application description topic classification tasks. It is mainly classified into two classifications of short text, multi-classification of short text and multi-classification of long text. Some of the tasks have many categories, more than 100 categories, and there is a category imbalance problem. Inter-sentence relationship tasks include natural language reasoning and short text matching tasks. The reading comprehension tasks include idiom reading comprehension, selective fill-in-the-blank, summary judgment, keyword identification and pronoun disambiguation tasks. Each task provides roughly 160 pieces of labeled data and about 20,000 pieces of unlabeled data. Because the long text classification task has many categories and is too difficult, it also provides more labeled data. The detailed task data is shown in Table 4:

Table 4 FewCLUE data set task introduction
Table 5 shows the comparison of experimental results of different models and parameter amounts. In the RoBERTa Base experiment, using the PET/EFL model will exceed the traditional direct Fine-Tune model result by 2-28PP. Based on the PET/EFL model, in order to explore the effect of large models in small sample scenarios, we conducted experiments on RoBERTa Large. Compared with RoBERTa Base, large models can improve the model by 0.5-13PP; in order to better utilize domain knowledge , we further conducted experiments on the RoBERTa Large Clue model that was pre-trained on the CLUE data set, and the large model that incorporated domain knowledge further improved the results by 0.1-9pp. Based on this, in subsequent experiments, we will conduct experiments on RoBERTa Large Clue.

Table 5 Comparison of experimental results of different models and parameter amounts (bold red font indicates the best result)
Table 6 shows the experimental results of data enhancement and integrated learning on the PET/EFL model. It can be found that even if the data enhancement strategy is used on a large model, the model can bring an improvement of 0.8-9PP, and further integrated learning & self-training In the future, model performance will continue to improve by 0.4-4PP.

Table 6 Experimental results of basic model data-enhanced ensemble learning (bold red font indicates the best result)
In the integrated learning self-training step, we tried several screening strategies:
In various businesses of Meituan, there are rich NLP scenarios, and some tasks can be classified The categories are text classification tasks and inter-sentence relationship tasks. The small sample learning strategy mentioned above has been applied to various scenarios of Meituan Dianping. It is expected to train better models when data resources are scarce. In addition, the small sample learning strategy has been widely used in various NLP algorithm capabilities of Meituan’s internal natural language processing (NLP) platform. It has been implemented in many business scenarios and achieved significant benefits. Meituan’s internal engineers can Use this platform to experience the capabilities related to the NLP center.
Text classification task
Classification of medical beauty themes: For Meituan and Dianping The content of the notes is divided into 8 categories according to the subject matter: curiosity hunting, store exploration, evaluation, real-life cases, treatment process, pitfall avoidance, effect comparison, and popular science. When the user clicks on a certain topic, the corresponding note content is returned, and the experience sharing is shared on the encyclopedia page and plan page of the medical beauty channel of Meituan and Dianping App. The accuracy of small sample learning using 2,989 training data increased by 1.8PP, reaching 89.24 %.
Strategy identification: Mining travel strategies from UGC and notes, providing content supply of travel strategies, applied to the strategy module under the scenic spot search, the recall content is For notes describing travel strategies, small sample learning uses 384 pieces of training data to increase the accuracy by 2PP, reaching 87%.
Xuecheng Text Classification: Xuecheng (Meituan Internal Knowledge Base) has a large number of user texts. After induction, the texts are divided into For 17 categories, the existing model was trained on 700 pieces of data. Through small sample learning, the model accuracy was improved by 2.5PP on the existing model, reaching 84%.
Project screening: The current evaluation list page of LE Life Services/Beauty and other businesses mixes the evaluations in a way that is inconvenient for users to quickly find decision-making information, so more structured classification tags are needed. To meet the needs of users, small sample learning achieved an accuracy of 95% using 300-500 pieces of data in these two businesses (multiple data sets increased by 1.5-4PPrespectively).
Inter-sentence relationship task
Medical beauty efficacy marking: For Meituan and Dianping's note content is recalled according to efficacy. The types of efficacy include: hydration, whitening, face slimming, wrinkle removal, etc. It is online on the medical beauty channel page. There are 110 efficacy types that need to be marked. Only 2909 training data are used for small sample learning. The accuracy rate reached 91.88% (increased by 2.8PP).
Medical Beauty Brand Marking: Brand upstream companies have demands for brand promotion and marketing of their products, and content marketing is the current mainstream and effective marketing method. one. Brand marking is to recall the notes detailing the brand for each brand such as "European" and "Shuweike". There are 103 brands in total, which have been online in the Medical Beauty Brand Hall. Only 1,676 training items are needed for small sample learning. The data accuracy rate reached 88.59% (increased by 2.9PP).
In this list submission, we built a semantic understanding model based on RoBERTa and enhanced prediction Training, PET/EFL model, data augmentation and ensemble learning & self-training to improve model performance. This model can complete text classification, inter-sentence relationship reasoning tasks and several reading comprehension tasks.
By participating in this evaluation task, we have a deeper understanding of the algorithms and research in the field of natural language understanding in small sample scenarios, and also have a better understanding of the Chinese language implementation capabilities of cutting-edge algorithms. A thorough test was conducted to lay the foundation for further algorithm research and algorithm implementation. In addition, the task scenarios in this data set are very similar to the business scenarios of Meituan Search and NLP Department. Many strategies of this model are also directly applied in actual business and directly empower the business.
Luo Ying, Xu Jun, Xie Rui, and Wu Wei are all from Meituan Search and NLP Department/NLP Center.
The above is the detailed content of Meituan ranks first in the small sample learning list FewCLUE! Prompt Learning+self-training practice. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



