


arXiv paper "VectorFlow: Combining Images and Vectors for Traffic Occupancy and Flow Prediction", August 9, 2022, working at Tsinghua University.

# Predicting the future behavior of road agents is a key task in autonomous driving. Although existing models have achieved great success in predicting the future behavior of agents, effectively predicting the coordinated behavior of multiple agents remains a challenge. Recently, someone proposed occupancy flow fields (OFF) representation, which represents the joint future state of road agents through a combination of occupancy grids and flows, supporting jointly consistent predictions.
This work proposes a new occupancy flow fields predictor, an image encoder that learns features from rasterized traffic images, and a vector encoder that captures continuous agent trajectory and map state information, both Combined to generate accurate occupancy and flow predictions. The two encoding features are fused by multiple attention modules before generating the final prediction. The model ranked third in the Waymo Open Dataset Occupancy and Flow Prediction Challenge and achieved the best performance in the occluded occupancy and flow prediction task.
OFF representation ("Occupancy Flow Fields for Motion Forecasting in Autonomous Driving", arXiv 2203.03875, 3, 2022) is a space-time grid in which each grid cell includes i) The probability that any agent occupies a unit and ii) represents the flow of movement of the agent occupying that unit. It provides better efficiency and scalability because the computational complexity of predicting occupancy flow fields is independent of the number of road agents in the scene.
The picture shows the OFF frame diagram. The encoder structure is as follows. The first stage receives all three types of input points and processes them with PointPillars-inspired encoders. Traffic lights and road points are placed directly on the grid. The state encoding of the agent at each input time step t is to uniformly sample a fixed-size point grid from each agent BEV box, and combine these points with the relevant agent state attributes (including the one-hot encoding of time t ) placed on the grid. Each pillar outputs an embedding for all points it contains. The decoder structure is as follows. The second level receives each pillar embedding as input and generates per grid cell occupancy and flow predictions. The decoder network is based on EfficientNet, using EfficientNet as the backbone to process each pillar embedding to obtain feature maps (P2,...P7), where Pi is downsampled 2^i from the input. The BiFPN network is then used to fuse these multi-scale features in a bidirectional manner. Then, the highest resolution feature map P2 is used to regress the occupancy and flow predictions for all agent classes K at all time steps. Specifically, the decoder outputs a vector for each grid cell while predicting occupancy and flow.
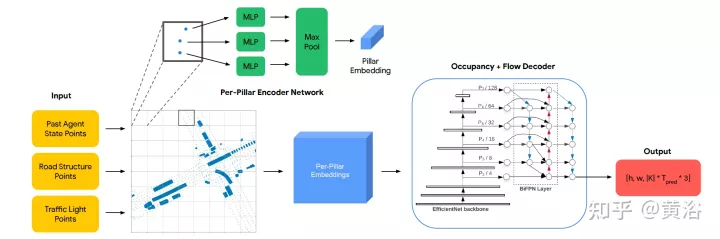
For this article, the following problem setting is made: given the 1-second history of the traffic agent in the scene and the scene context, such as map coordinates, the goal is to predict i) future observations occupancy, ii) occupancy of future occlusions, and iii) future flows of all vehicles at 8 future waypoints in a scene, where each waypoint covers an interval of 1 second.
Process the input into a rasterized image and a set of vectors. To obtain the image, a rasterized grid is created at each time step in the past relative to the local coordinates of the self-driving car (SDC), given the observation agent trajectory and map data. To obtain a vectorized input consistent with the rasterized image, the same transformations are followed, rotating and moving the input agent and map coordinates relative to the SDC's local view.
The encoder consists of two parts: the VGG-16 model that encodes rasterized representation, and the VectorNe model that encodes vectorized representation. The vectorized features are fused with the features of the last two steps of VGG-16 through the cross attention module. Through the FPN-style network, the fused features are upsampled to the original resolution and used as input rasterized features.
The decoder is a single 2D convolutional layer that maps the encoder output to the occupancy flow fields prediction, which consists of a series of 8 grid maps representing each time in the next 8 seconds Step occupancy and flow prediction.
as the picture shows:
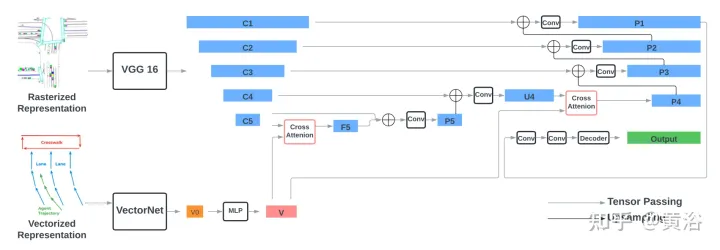
Use torchvision’s standard VGG-16 model as the rasterization encoder and follow VectorNet (code https://github.com/Tsinghua -MARS-Lab/DenseTNT) implementation. The input to VectorNet consists of i) a set of road element vectors of shape B×Nr×9, where B is the batch size, Nr=10000 is the maximum number of road element vectors, and the last dimension 9 represents each vector and the vector ID The position (x, y) and direction (cosθ, sinθ) of the two endpoints; ii) a set of agent vectors with a shape of B×1280×9, including vectors of up to 128 agents in the scene, where each agent With 10 vectors from the observation position.
Follow VectorNet, first run the local map according to the ID of each traffic element, and then run the global map on all local features to obtain vectorized features of shape B×128×N, where N is the traffic element’s Total, including path elements and intelligence. The size of the feature is further increased four times through the MLP layer to obtain the final vectorized feature V, whose shape is B × 512 × N, and its feature size is consistent with the channel size of the image feature.
The output features of each level of VGG are represented as {C1, C2, C3, C4, C5}, relative to the input image and 512 hidden dimensions, the strides are {1, 2, 4, 8, 16} pixels. The vectorized feature V is fused with the rasterized image feature C5 of shape B×512×16×16 through the cross attention module to obtain F5 of the same shape. The query item of the cross attention is the image feature C5, which is flattened into a B×512×256 shape with 256 tokens, and the Key and Value items are the vectorized feature V with N tokens.
Then connect F5 and C5 on the channel dimension, and pass through two 3×3 convolutional layers to obtain P5 with a shape of B×512×16×16. P5 is upsampled through the FPN-style 2×2 upsampling module and connected to C4 (B×512×32x32) to generate U4 with the same shape as C4. Another round of fusion is then performed between V and U4, following the same procedure, including cross-attention, to obtain P4 (B × 512 × 32 × 32). Finally, P4 is gradually upsampled by the FPN style network and connected with {C3, C2, C1} to generate EP1 with a shape of B×512×256×256. Pass P1 through two 3×3 convolutional layers to obtain the final output feature with a shape of B×128×256.
The decoder is a single 2D convolutional layer with an input channel size of 128 and an output channel size of 32 (8 waypoints × 4 output dimensions).
The results are as follows:
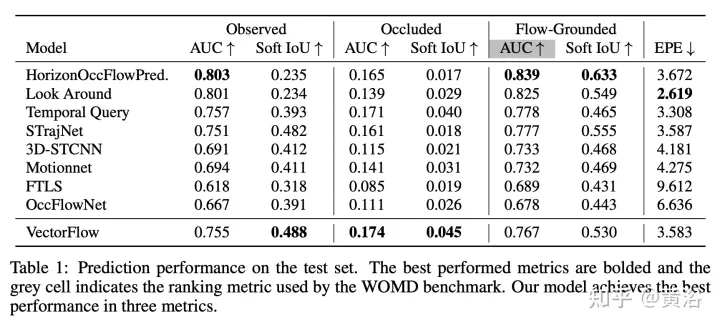
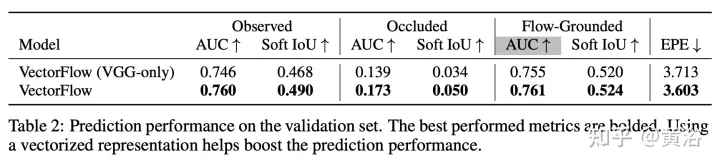
The above is the detailed content of VectorFlow: Combining images and vectors for traffic occupancy and flow prediction. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



