


This article brings you relevant knowledge aboutmysql, which mainly introduces issues related to keywords, including three normal forms, character sets, custom quantities, views, and partitions Let’s take a look at the table and so on. I hope it will be helpful to everyone.

Recommended learning:mysql video tutorial
The character set specifies the storage format of characters in the database, such as How much space, which characters are supported, etc. Different character sets have different encoding rules. In some cases, there are even proofreading rules. The proofreading rules refer to the sorting of a character set. In the operation and maintenance and use of MySQL database, it is very important to select the appropriate character set. If the selection is inappropriate, the database performance may be affected at least, and the data storage may be garbled in serious cases.
There are four main common MySQl character sets:
| Character set | Length | Description |
|---|---|---|
| GBK | 2 | Supports Chinese, but not an international character set |
| UTF-8 | 3 | supports mixed Chinese and English scenarios and is an international character set |
| latin1 | 1 | MySQL default character set |
| utf8mb4 | 4 | Fully compatible with UTF-8, using four bytes to store more characters |
In the development and operation of MySQL database, the character set selection rules are as follows:
A custom variable is a temporary container used to store content and exists throughout the entire process of connecting to MySQL. It can be defined using set.
SET @last_week := CURRENT_DATE-INTERVAL 1 WEEK;SELECT id,name from user where create_time > @last_week;
Notes on using custom variables:
Query using custom variables cannot use caching;
Custom variables cannot be used where constants or identifiers are used, such as table names, column names, and limit clauses;
The life cycle of custom variables is valid within a connection and cannot Use them for communication between connections;
Avoid repeatedly querying the data that has just been updated
What should you do if you want to obtain the information about the row while updating the row? How to avoid repeated queries?
This is generally done:
update user set update_time = now() where id = 1;select update_time from user where id = 1;
Using custom variables can optimize it:
update user set update_time = now() where id = 1 and @now := now();select @now;
It seems that there are still two queries, but the second query does not need to access any data table, so it will be much faster.
MySQL supports many data types, and choosing the correct data type is crucial to obtaining high performance.
In general, you should try to use smaller data types. Smaller data types are usually faster because they occupy less space. The disk, memory and CPU cache require shorter CPU cycles for processing.
Simple data types usually require fewer CPU cycles, and shaping is cheaper than string types because of the character set and calibration Validation rules make character comparisons more complex than integer comparisons.
Many tables contain columns that can be NULL, even if the application does not need to save NULL, because NULL is Default properties for columns, usually it is best to specify columns as NOT NULL.
If the query contains columns that can be NULL, it is more difficult for MySQL to optimize because NULL columns make indexes, index statistics, and value comparisons more complex. NULL-capable columns use more storage space and require special handling in MySQL. When NULL-capable columns are indexed, each index record requires an extra byte, which may even result in a fixed size in MyISAM. The index becomes a variable-size index.
A view (view) is a virtual table. It is a logical table and does not contain data itself. Saved in the data dictionary as a select statement. For complex queries on multiple tables, using views can simplify the queries. When the view uses a temporary table, the where condition cannot be used, and the index cannot be used.
Single table view is generally used for query and modification, which will change the data of the basic table. Multi-table view is generally used for query, and will not change the data of the basic table.
The purpose of using views is to ensure data security and improve query efficiency.
Users who use views do not need to care about the structure, association conditions and filtering conditions of the subsequent corresponding tables. To the user, it is already a result set of filtered compound conditions.
Users using views can only access the result sets they are allowed to query. The permission management of the table cannot be limited to a certain row or column, but it can be simply done through the view. accomplish.
Once the structure of the view is determined, the impact of changes in the table structure on users can be shielded. Adding columns to the source table has no impact on the view; changing column names in the source table can be done by modifying the view. Solved without causing any impact on visitors.
Sometimes the best way to improve performance is to save derived redundant data in the same table. Sometimes you also need to create a completely independent summary table or cache table.
For cache tables, if the main table uses InnoDB, using MyISAM as the engine for the cache table will result in a smaller index footprint and full-text retrieval.
When using cache tables and summary tables, you must decide whether to maintain the data in real time or rebuild it periodically. Which one is better depends on the application, but regular rebuilding doesn't just save resources, it also keeps the table from being fragmented and having fully sequentially organized indexes.
When rebuilding summary tables and cache tables, it is usually necessary to ensure that the data is still available during operations. This needs to be achieved by using a shadow table. The shadow table refers to a table created behind the real table. After the table creation operation is completed, the shadow table and the original table can be switched through an atomic rename operation.
In order to improve the reading speed, we often build some additional indexes, add redundant columns, and even create cache tables and summary tables. These methods will increase the writing burden and require additional maintenance tasks, but when designing a high-performance database These are common techniques, and although the write operation is slower, the read performance is significantly improved.
Normally, the data of the same table are stored together at the physical level. As business grows, when the amount of data in the same table becomes too large, it will cause management inconvenience. The partition feature can physically divide a table into multiple partitions based on certain rules. Multiple partitions can be managed separately or even stored on different disks/file systems to improve efficiency.
Data can be stored across disks, suitable for storing large amounts of data;
Data management is very convenient, operating data in partitions does not affect the normal operation of other partitions;
When querying, you can narrow the scope of the query and improve the query by locking the characteristics of the partition. Performance;
Foreign keys usually require an additional operation in another table every time the data is modified. For query operations, although InnoDB forces foreign keys to use indexes, it still cannot eliminate the overhead of this constraint check. If the selectivity of the foreign key is very low, this will result in a very selective index.
However, in some scenarios, foreign keys will improve some performance. For example, if you want to ensure that two related tables always have consistent data, then using foreign keys will have higher performance than checking consistency in the application. Much more, besides. Foreign keys are also more efficient in deleting and updating related data than maintaining them in the application. However, foreign key maintenance operations are performed row by row, and such updates will be slower than batch deletions and updates.
Foreign key constraints require additional access to some other tables during querying, which requires additional locks. If a record is written to the child table, the foreign key constraint will cause InnoDB to check the corresponding record of the parent table, which means that the corresponding record of the parent table needs to be locked to ensure that this record will not be lost after the transaction is completed. was deleted. This can lead to additional lock waits and even some deadlocks. Because there is no direct access to these tables, this type of deadlock is difficult to troubleshoot.
So, in many current projects, foreign keys are no longer used for performance reasons.
MySQL query cache saves the complete results returned by the query. When the query hits the cache, MySQL will return the results immediately, skipping parsing, optimization and Implementation process.

The query cache system will track each table involved in the query. If these tables change, all cached data related to this table will be invalid. This The efficiency of the mechanism seems relatively low, because the query results may not be affected when the data table changes, but the cost of this simple implementation is very small, and this is very important for a very busy system.
When there is some uncertain data in the query statement, it will not be cached, such as the function now(). In fact, if the cache contains any user-defined functions, stored functions, user variables, temporary tables, MySQL system tables, or any tables that contain column-level permissions, they will not be cached.
For InnoDB users, some characteristics of transactions will limit the use of query cache. When a statement modifies a table in a transaction, MySQL will invalidate the query cache setting corresponding to the table before the transaction is submitted. Therefore, long-running transactions will greatly reduce the hit rate of the query cache.
The stored procedures are a set of procedures designed to complete specific functions. A collection of SQL statements is compiled and saved in the database. By specifying the name of the stored procedure and giving the values of the parameters, results can also be returned.
Reduce network traffic
Improve execution speed
Reduce the number of database connections
High security
High reusability
Poor portability
The statements within the transaction are either all executed or none. Transactions have ACID characteristics, which represent atomicity, consistency, isolation, and durability.
A transaction must be regarded as an indivisible minimum unit of work. All operations in the entire transaction must be fully executed and committed. Success, or rollback on failure.
The database always transitions from one consistency state to another consistency state.
The modifications made by one transaction are not visible to other transactions before they are finally committed.
Once the transaction is submitted, the modifications made will be permanently saved in the database.
The index is a data structure used by the storage engine to quickly find records. I think the most important knowledge point in the database is the index.
Storage engines use B-Tree indexes in different ways, and their performance is also different, each with its own advantages and disadvantages. For example, MyISAM uses prefix compression technology to make the index smaller, but InnoDB stores it in the original data format. MyISAM indexes refer to indexed rows by the physical location of the data, while InnoDB refers to indexed rows by their primary key.
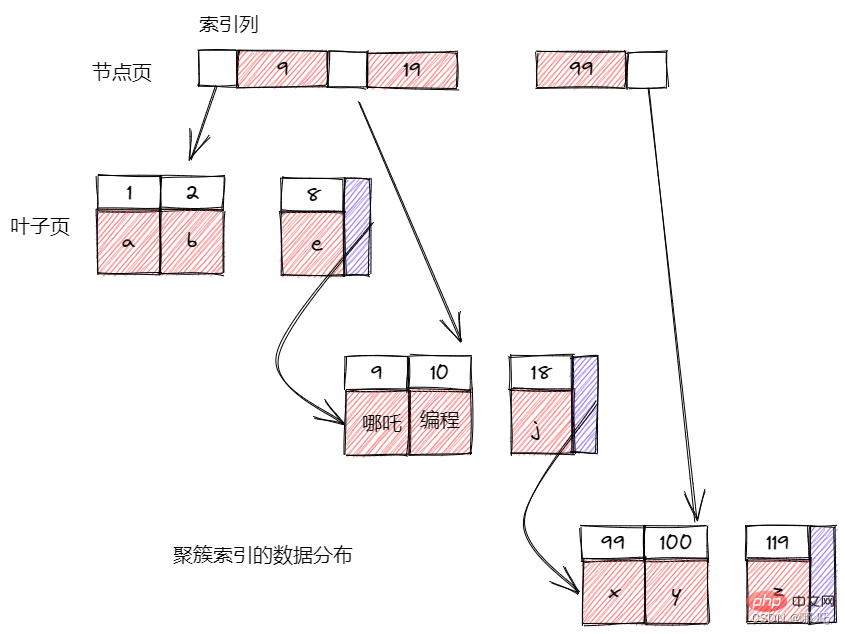
#B-Tree usually means that all values are stored in order, and each leaf page is the same distance from the root.
B-Tree index can speed up access to data, because the storage engine no longer needs to perform a full table scan to obtain the required data, but instead searches from the root node of the index. The slots of the root node store pointers to child nodes, and the storage engine searches downwards based on these pointers. By comparing the value of the node page with the value you are looking for, you can find appropriate pointers into the lower child nodes. These pointers actually define the upper and lower bounds of the values in the child node page. Eventually the storage engine either finds the corresponding value or the record does not exist.
Leaf nodes are special, their pointers point to the indexed data, not other node pages. B-Tree organizes and stores index columns sequentially, so it is very suitable for searching range data. B-Tree is suitable for full key value, key value range or key prefix search.
Because the nodes in the index tree are ordered, in addition to looking up by value, the index can also be used for order by operations in queries. Generally speaking, if a B-Tree can find a value in a certain way, it can also be used for sorting in this way.
The purpose of full-text index is to perform query filtering through keyword matching, based on similarity query, rather than precise query.
Full-text index uses word segmentation technology to analyze the frequency and importance of certain keywords in the text, and intelligently filters out the results we want according to a certain algorithm.
Full-text index is generally used to query certain keywords in strings, such as char, varchar, and text. It also supports natural language full-text index and Boolean full-text index.
Recommended learning:mysql video tutorial
The above is the detailed content of 13 keywords you must know to learn MySQL (summary sharing). For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



