This article brings you relevant knowledge about java, which mainly sorts out issues related to JVM garbage collectors, including Serial and Serial Old collectors, ParNew collectors, Parallel and Parallel Old recycler and other contents, let’s take a look at it, I hope it will be helpful to everyone.

## Recommended learning: "
java video tutorial"
Concurrency and parallelism
Parallel ): Parallel describes the relationship between multiple garbage collector threads, indicating that multiple such threads are working together at the same time. Usually, by default, the user thread is in a waiting state at this time. - Concurrency (Concurrent): Concurrency describes the relationship between the garbage collector thread and the user thread, indicating that both the garbage collector thread and the user thread are running at the same time. Since the user thread is not frozen, the program can still respond to service requests, but because the garbage collector thread occupies a part of the system resources, the application's processing throughput will be affected to a certain extent at this time.
-
Classification of garbage collectors
1. According to the number of threads According to the number of threads (used for garbage collection), it can be divided into
Serial Garbage Collector and Parallel Garbage Collector.
Serial garbage collector: Only one CPU is allowed to perform garbage collection operations at the same time. At this time, the working thread is suspended until the garbage collection work is completed. - Parallel garbage collector: Multiple CPUs can be used to perform garbage collection simultaneously.
-
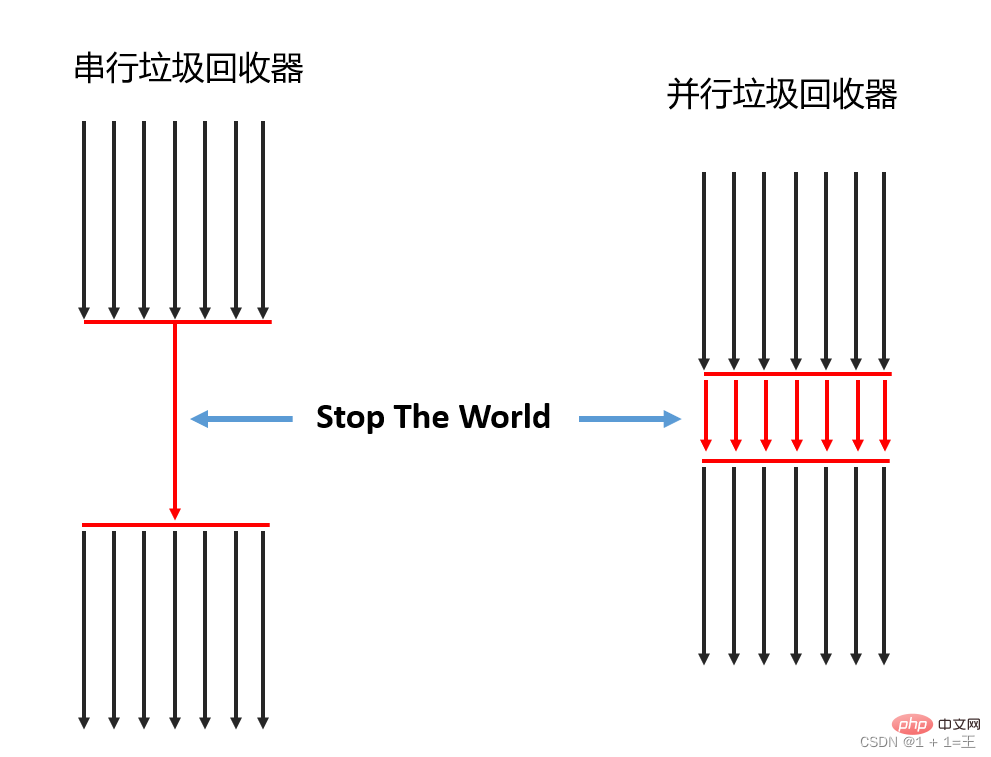
2. According to the working mode According to the working mode, it can be divided into
concurrent garbage collectorandexclusive garbage collection Device.
Concurrent garbage collector: Only one CPU is allowed to perform garbage collection operations at the same time. At this time, the working thread is suspended until the garbage collection work is completed. - Exclusive garbage collector: multiple CPUs can be used to perform garbage collection simultaneously.
-
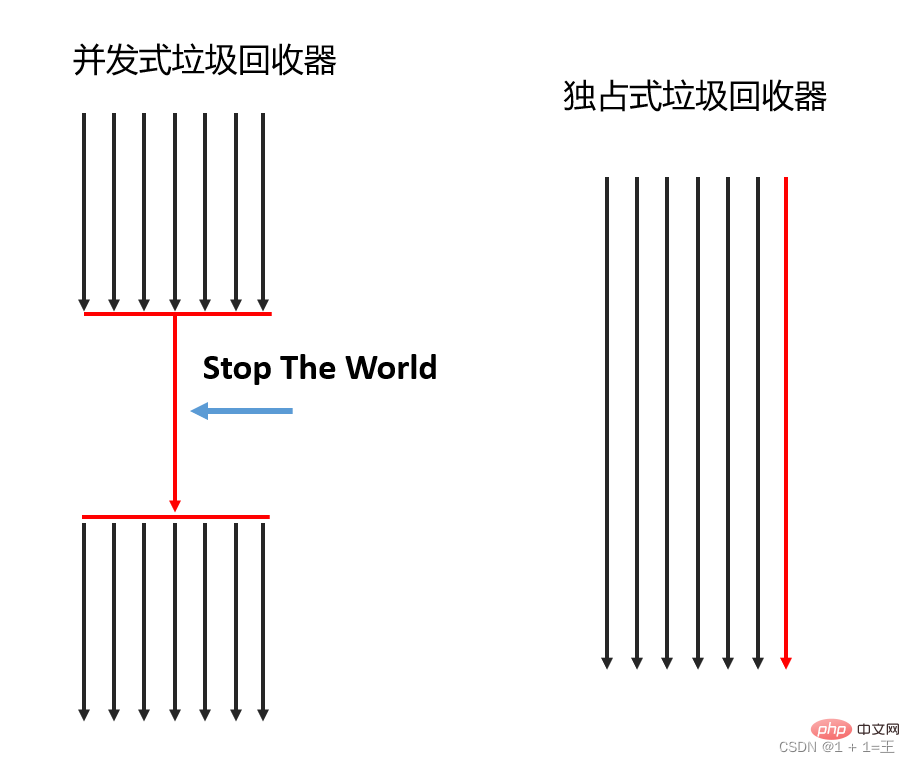
3. According to the fragmentation processing method According to the working mode, it can be divided into
compressing garbage collector and Non-compacting garbage collector.
The compressing garbage collector will compress and organize the surviving objects after the recycling is completed to eliminate the fragments after recycling.
7 classic garbage collectors
Serial collector: - serial、serial old
Parallel Recycler: - ParNew, Parallel scavenge, Parallel old
Concurrent recycler: - CMS, G1
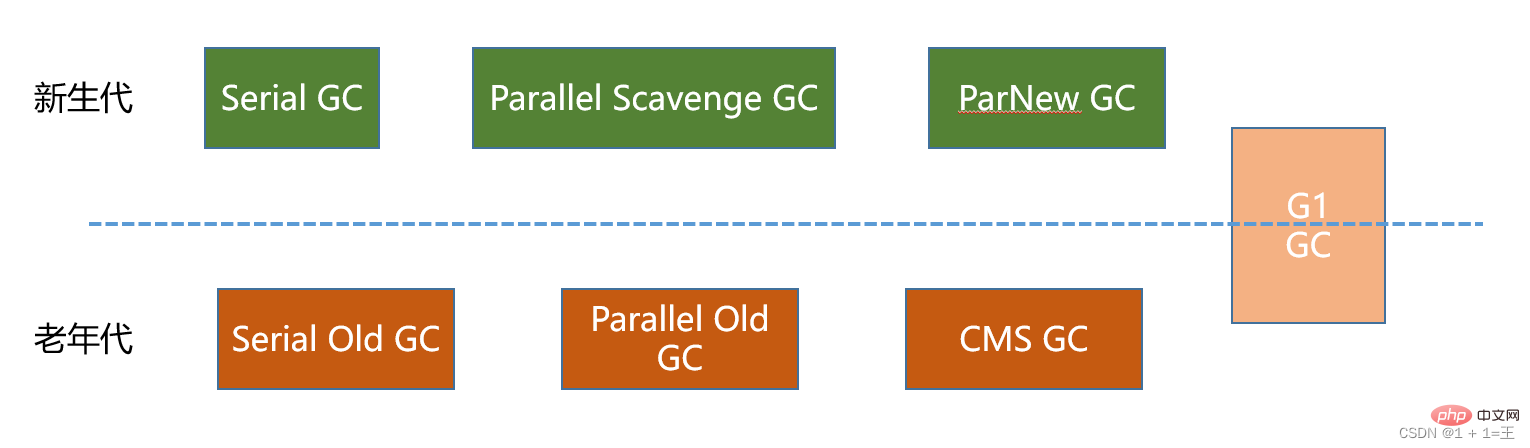
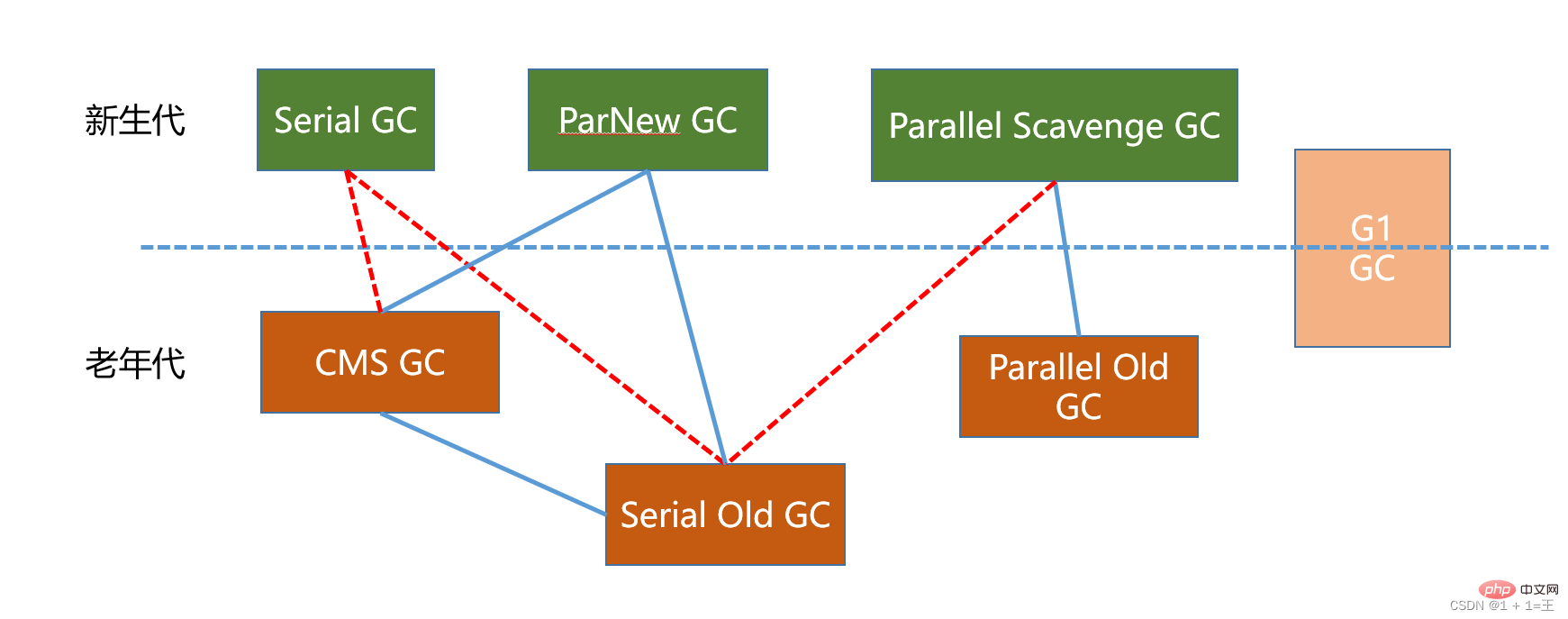
New generation collector: serial, ParNew, Parallel scavenge;- Old generation collector: Serial old, Parallel old、CMS;
- Entire heap collector: G1;
-
Garbage collector
Serial and Serial Old collector
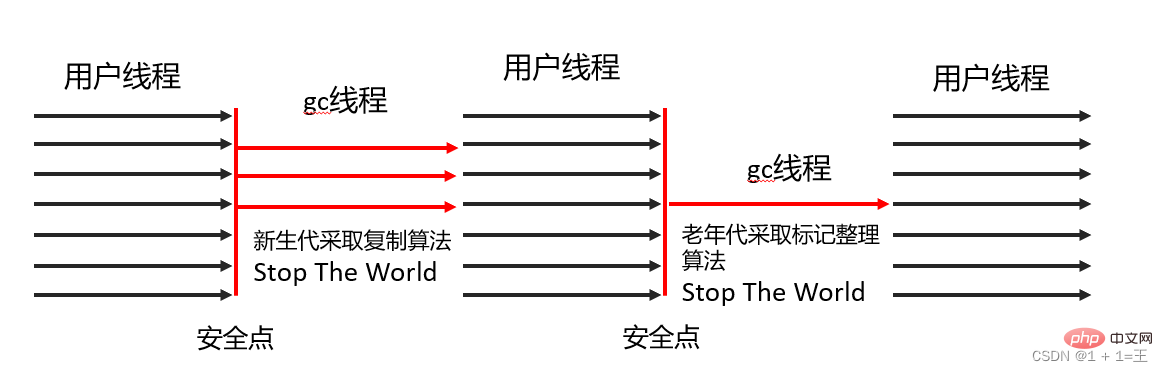
Serial collection The collector is the most basic and oldest collector. It was once (before JDK 1.3.1) the only choice for the new generation collector of the HotSpot virtual machine. The Serial collector is a
single-threaded working collector. When it performs garbage collection, all other working threads must be suspended until it completes the collection. Serial Old is the old generation version of the Serial collector.
The Serial collector uses - copy algorithm, serial recycling and "Stop The World" mechanism to perform garbage collection.
Serial Old Collector- Flags—Compression algorithm, serial collection, and "Stop The World" mechanismPerform garbage collection.
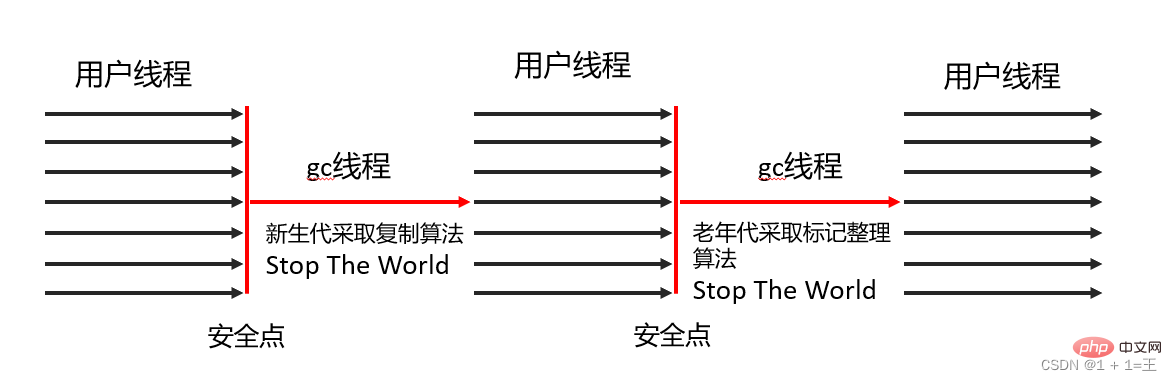
ParNew collector
The ParNew collector is essentially a multi-threaded parallel version of the Serial collector, except that it uses multiple threads for garbage at the same time. In addition to collection, the rest of the behavior, including all control parameters available to the Serial collector, collection algorithms, Stop The World, object allocation rules, recycling strategies, etc., are completely consistent with the Serial collector.
Parallel and Parallel Old collector
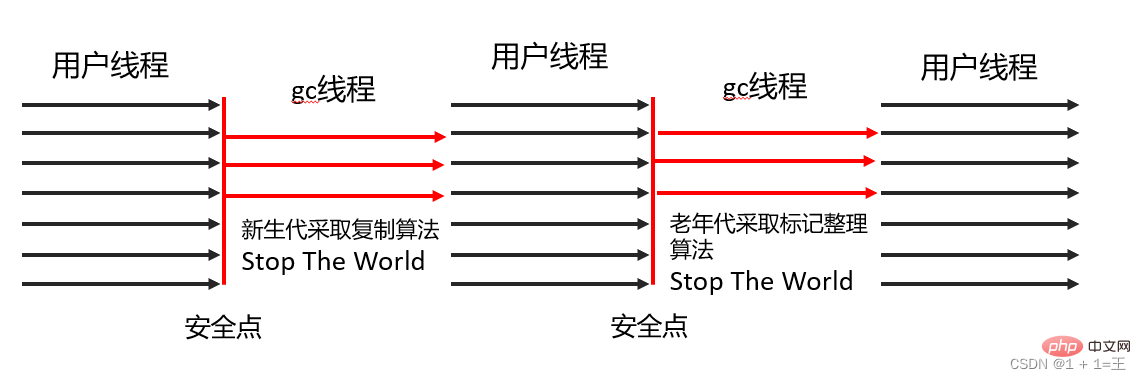
The Parallel Scavenge collector is also a new generation collector. It is also a collector based on the mark-copy algorithm. Multi-threaded collector capable of parallel collection.
Unlike the ParNew collector, the goal of the Parallel scavenge collector is to achieve a controllable
throughput. It is also called a throughput-first garbage collector.
Throughput: The ratio of the time the processor spends running user code to the total processor time consumed.
High throughput can make the most efficient use of processor resources and complete the program's computing tasks as quickly as possible. It is mainly suitable for analysis tasks that operate in the background and do not require too much interaction.
Parallel Old is the old generation version of the Parallel Scavenge collector, supports multi-threaded concurrent collection, and is implemented based on the mark-collation algorithm.
CMS collector
CMS (Concurrent Mark Sweep) collector is a collector that aims to obtain the shortest recycling pause time.
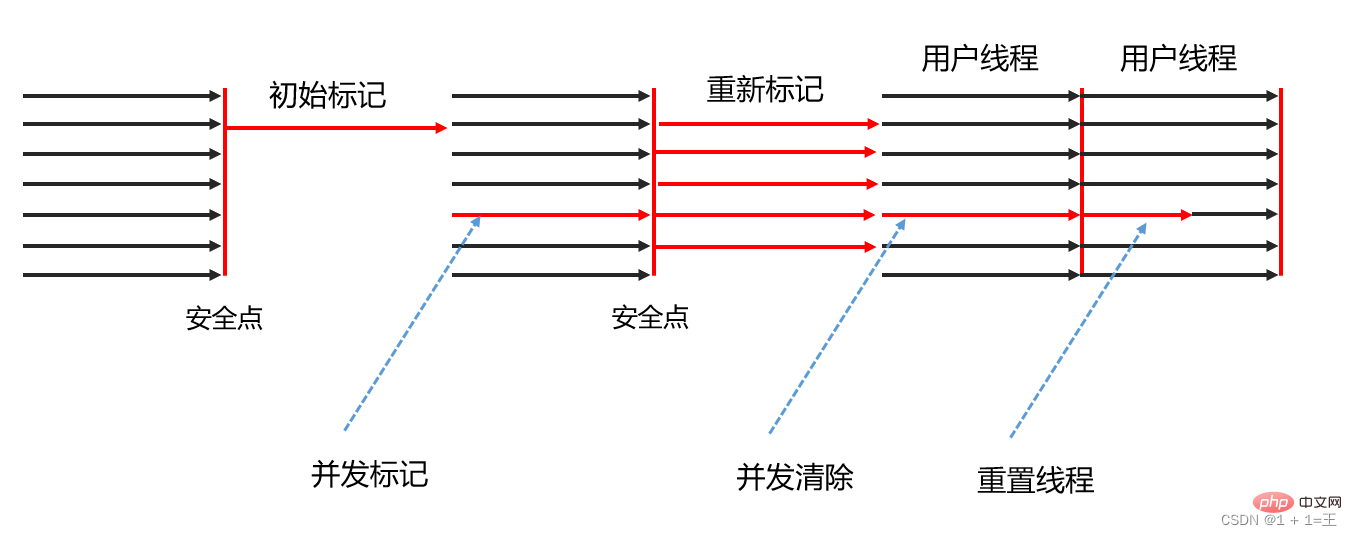
CMS collector is implemented based on the mark-clearance algorithm. Its operation can be divided into four steps, including:
- Initial mark
The initial mark only marks the objects that GC Roots can directly associate with, which is very fast;
- Concurrent Marking
The concurrent marking phase is the process of traversing the entire object graph starting from the objects directly associated with GC Roots. This The process takes a long time but does not require pausing the user thread, and can run concurrently with the garbage collection thread;
- Remarking
The remarking phase is to correct the problem caused by the user program continuing to operate during the concurrent marking period. Mark records for the part of the object that has changed. The pause time in this phase is usually slightly longer than the initial marking phase, but it is also much shorter than the concurrent marking phase;
- Concurrent clearing
Cleanup and delete The dead objects judged in the marking phase do not need to be moved, so this phase can also be concurrent with the user thread.
The CMS collector cannot process "Floating Garbage", and may fail with "Con-current Mode Failure" and cause another complete "Stop The World" Full GC generation.
During the concurrent marking and concurrent cleaning phases of CMS, the user thread is still running. Naturally, new garbage objects will continue to be generated while the program is running, but this part of the garbage objects will appear after the marking process is completed. , CMS cannot handle them in the current collection, and has to wait for the next garbage collection to clean them up. This part of the garbage is called "floating garbage".
It is also because the user thread needs to continue running during the garbage collection phase, so enough memory space needs to be reserved for the user thread to use, so the CMS collector cannot wait until the old generation is almost ready like other collectors. When the collection is completely filled, some space must be reserved for program operation during concurrent collection.
CMS is a collector implemented based on the "mark-and-clear" algorithm, which means that a large number of space fragments will be generated at the end of the collection. When there are too many space fragments, it will cause great trouble in the allocation of large objects.
Why not use mark-compression algorithm to avoid fragmentation?
Because when concurrent clearing is used, mark-compression is used to organize the memory, and the memory used by the original user thread cannot be used. To ensure that the user thread continues to execute, the premise is that the resources it runs on are not affected. Flag-compression is more suitable for "Stop The World" scenarios.
G1 (Garbage First) collector
Garbage First pioneered the design idea of the collector for local collection and the memory layout form based on Region. It is a collector mainly for the server side. The applied garbage collector is mainly aimed at machines equipped with multi-core CPUs and large-capacity memory. It can meet the GC pause time with a very high probability and also has high throughput performance characteristics.
For all other collectors before the G1 collector, the target range of garbage collection was either the entire new generation, the entire old generation, or the entire Java heap. G1 can form a collection set for any part of the heap memory for recycling. The measurement criterion is no longer which generation it belongs to, but which piece of memory stores the largest amount of garbage and has the greatest recycling benefits.
Characteristics of G1 collector
1. Parallelism and concurrency
- Parallelism: During G1 recycling, there can be multiple GCs The threads work at the same time, and the user thread Stops The World at this time.
- Concurrency: G1 has the ability to execute alternately with the application, and part of the work can be executed at the same time as the application. Therefore, generally speaking, the application will not be completely blocked during the entire recycling phase.
2. Generational collection
- G1 is still designed according to the generational collection theory, but its heap memory layout is very obviously different from other collectors: G1 no longer adheres to a fixed size and a fixed number of generational area divisions, but It divides the continuous Java heap into multiple independent regions (Regions) of equal size. Each Region can play the role of Eden space, Survivor space, or old generation space in the new generation as needed. The collector can use different strategies to process Regions that play different roles, so that good collection effects can be achieved whether they are newly created objects or old objects that have survived for a period of time and have survived multiple collections.
- There is also a special type of Humongousregion in Region, which is specially used to store large objects. G1 believes that as long as the size of an object exceeds half of the capacity of a Region, it can be determined as a large object.
3. Spatial integration
- G1 uses region as the basic unit when recycling memory, and uses a copy algorithm between regions, but overall it can Think of it as a mark-compression algorithm.
4. Predictable pause time model
- #The G1 collector can establish a predictable pause time model, which treats the Region as a single The smallest unit of recycling, that is, the memory space collected each time is an integral multiple of the Region size, so that full-region garbage collection in the entire Java heap can be avoided in a planned manner.
- The G1 collector tracks the "value" of the garbage accumulation in each Region. The value is the amount of space obtained by recycling and the experience value of the time required for recycling, and then maintains it in the background A priority list, each time based on the collection pause time allowed by the user setting, the Regions with the greatest recovery value will be processed first.
- This method of using Region to divide memory space and prioritized region recycling ensures that the G1 collector obtains the highest possible collection efficiency within a limited time.
- The pause prediction model is implemented based on the theoretical basis of attenuation mean. During the garbage collection process, the G1 collector will record the recycling time of each Region, the number of dirty cards in each Region's memory set, etc. The cost of each measurable step is analyzed and statistical information such as average value, standard deviation, and confidence level are obtained. Then use this information to predict which Regions will make up the recycling collection if recycling starts now so that the highest revenue can be obtained without exceeding the expected pause time.
How to solve the cross-Region reference objects that exist in Region?
Use memory sets to avoid scanning the entire heap as GC Roots. Each Region maintains its own memory set. These memory sets record the pointers pointed to by other Regions and mark where these pointers are. Within the scope of the card page. The memory set of G1 is essentially a hash table in terms of storage structure. Key is the starting address of other Regions, Value is a set, and the elements stored in it are the index numbers of the card table.
The operation process of G1 collector
-
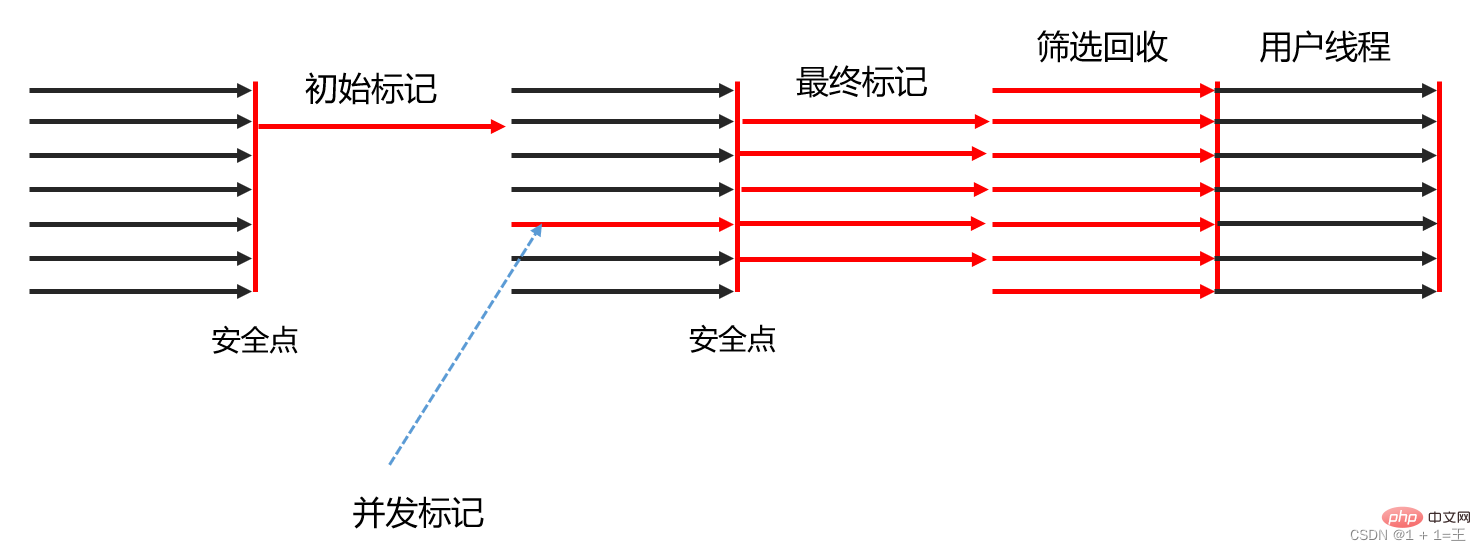
Initial Marking (Initial Marking): Just mark the objects that GC Roots can directly associate with, and modify TAMS The value of the pointer allows the next phase of user threads to correctly allocate new objects in the available Region when they run concurrently. This stage requires pausing the thread, but it takes a very short time, and it is completed synchronously during Minor GC, so the G1 collector actually does not have additional pauses at this stage.
-
Concurrent Marking (Concurrent Marking): Starting from the GC Root, perform reachability analysis on the objects in the heap, recursively scan the object graph in the entire heap, and find out the objects to be recycled. The stage takes a long time, but can be executed concurrently with the user program. After the object graph scan is completed, the objects recorded by SATB that have reference changes during concurrency must be reprocessed.
-
Final Marking (Final Marking): Make another short pause on the user thread to process the last few SATB records left after the concurrent phase.
-
Filtering and Recycling (Live Data Counting and Evacuation): Responsible for updating Region statistics, sorting the recycling value and cost of each Region, and formulating recycling based on the pause time expected by the user. According to the plan, you can freely select any number of Regions to form a recycling collection, then copy the surviving objects of the region decided to be recycled to the empty Region, and then clean up all the space of the entire old Region. The operation here involves the movement of living objects, which must suspend the user thread and be completed by multiple collector threads in parallel.
Comparison of 7 classic garbage collectors
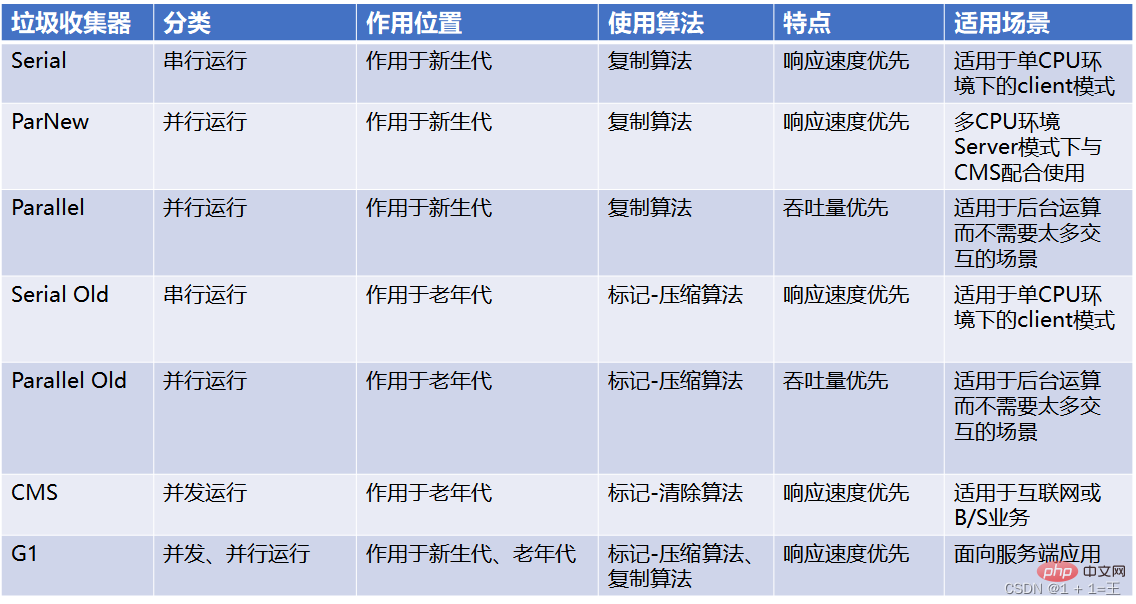
Garbage collector combinations
Low latency garbage collector
Shenandoah collector
Shenandoah also uses a Region-based heap memory layout. It also has a Humongous Region for storing large objects, and the default recycling strategy is the same. It is the Region with the greatest recycling value first... But in terms of managing heap memory, it has at least three obvious differences from G1.
- The recycling phase of G1 can be parallelized by multiple threads, but it cannot be concurrent with user threads. Shenandoah supports concurrent sorting algorithms.
- By default, generational collection is not used. In other words, there will be no special new generation Region or old generation Region. Generational collection is not implemented. This does not mean that generational collection has no value to Shenandoah. This is more. Due to cost-effectiveness trade-offs, it is placed at a lower priority based on workload considerations.
- Shenandoah abandoned the memory set that consumed a lot of memory and computing resources to maintain in G1, and instead used a global data structure called "connection matrix" to record cross-Region reference relationships, reducing the processing time of cross-generation pointers. Time-consuming memory set maintenance consumption also reduces the probability of pseudo-sharing problems. The connection matrix can be simply understood as a two-dimensional table. If there is an object in Region N pointing to Region M, a mark will be placed in the N rows and M columns of the table. During recycling, this table can be used to determine which regions have cross-connections. citation.
The working process of the Shenandoah collector can be roughly divided into the following nine stages:
-
Initial marking: Like G1, first mark with GC For objects directly related to Roots, this stage is still "Stop The World", but the pause time has nothing to do with the heap size, only the number of GC Roots.
-
Concurrent Marking: Like G1, traverse the object graph and mark all reachable objects. This stage is concurrent with the user thread. The length of time depends on the number of surviving objects in the heap. Number and structural complexity of the object graph.
-
Final mark: Same as G1, process the remaining SATB scans, and count the Regions with the highest recycling value at this stage, and form these Regions into a set of recycling collections. There will also be a short pause during the final marking phase.
-
Concurrent Cleanup: This stage is used to clean up regions where not even a single surviving object has been found in the entire region.
-
Concurrent Recycling: At this stage, Shenandoah will copy the surviving objects in the collection to other unused Regions. How long the concurrent collection phase runs depends on the size of the collection.
-
Initial reference update: After the concurrent recycling phase ends when copying objects, all references to old objects in the heap need to be corrected to the new addresses after copying. This operation is called reference update. The initialization phase of reference update does not actually do any specific processing. This phase is only established to establish a thread rendezvous point to ensure that all collector threads in the concurrent recycling phase have completed the object moving tasks assigned to them. The initial reference update time is very short, resulting in a very brief pause.
-
Concurrent reference update: The reference update operation actually begins. This stage is concurrent with the user thread. The length of time depends on the number of references involved in the memory. Concurrent reference update is different from concurrent marking. It no longer needs to search along the object graph. It only needs to linearly search for the reference type in the order of the memory physical address and change the old value to the new value.
-
Final reference update: After solving the reference update in the heap, the references existing in GC Roots must also be corrected. This stage is the last pause of Shenandoah, and the pause time is only related to the number of GC Roots.
-
Concurrency Cleanup: After concurrent recycling and reference updating, all Regions in the entire recycling set have no surviving objects. These Regions have become Immediate Garbage Regions. Finally, call Concurrency again. The cleanup process reclaims the memory space of these Regions for future allocation of new objects.
ZGC Collector
The goals of ZGC and Shenandoah are highly similar. They both hope to achieve any heap memory size without affecting throughput as much as possible. The pause time of garbage collection can be limited to a low latency of less than ten milliseconds.
The ZGC collector is based on Region memory layout, (temporarily) without generation, and uses technologies such as read barriers, dyed pointers, and memory multiple mapping to achieve concurrent marking - A garbage collector based on the sorting algorithm with low latency as its primary goal.
ZGC also uses a Region-based heap memory layout, but unlike them, ZGC's Region is dynamic - dynamically created and destroyed, as well as dynamic region capacity size.
The operation process of ZGC can be divided into four stages:
-
Concurrent Marking(: Like G1 and Shenandoah, concurrent marking is the stage of traversing the object graph for reachability analysis. It also goes through the initial marking and final marking similar to G1 and Shenandoah. Short pauses for marking (although they are not called these in ZGC), and what these pause phases do is similar on the target. Unlike G1 and Shenandoah, ZGC's marking is on the pointer rather than the object. Performed on the above, the marking phase will update the Marked 0 and Marked 1 flags in the dyeing pointer.
-
Concurrent preparation reallocation: This stage requires statistics based on specific query conditions. Which Regions should be cleaned up during the collection process, and these Regions should be organized into reallocation sets.
-
Concurrent reallocation: Reallocation is the core stage in the ZGC execution process. This process should focus on reallocation. The surviving objects are copied to the new Region, and a forwarding table is maintained for each Region in the reallocation set to record the steering relationship from the old object to the new object.
-
Concurrent remapping: What remapping does is to correct all references in the entire heap pointing to old objects in the reallocation set. ZGC cleverly merges the work to be done in the concurrent remapping phase into the concurrent marking phase in the next garbage collection cycle. Anyway, they need to traverse all objects, so merging saves the cost of traversing the object graph. Once all pointers are corrected, the original forwarding table that records the relationship between old and new objects can be released.
Choose the right garbage collector
Consider the following three questions:
What is the main focus of the application?
- If it is data analysis, For scientific computing tasks, the goal is to calculate the results as quickly as possible, so throughput is the main focus;
- If it is an SLA application, the pause time directly affects the quality of service, and in severe cases, it may even cause transaction timeout, such delay That is the main focus;
- And if it is a client application or an embedded application, the memory footprint of garbage collection cannot be ignored.
What is the infrastructure for running the application?
- Hardware specifications, the system architecture involved is x86-32/64, SPARC or ARM/Aarch64;
- The number of processors and the size of allocated memory;
- Whether the selected operating system is Linux, Solaris or Windows, etc.
What is the publisher using JDK? What is the version number?
Is it ZingJDK/Zulu, OracleJDK, Open-JDK, OpenJ9, or a release from another company? Which version of the "Java Virtual Machine Specification" does this JDK correspond to?
How to choose a garbage collector
- Prioritize adjusting the size of the heap to allow the JVM to adapt.
- If the memory is less than 100M, use the serial collector
- If it is a single-core, stand-alone program, and there is no pause time requirement, the serial collector
- If it is multiple CPU, high throughput is required, pause time is allowed to exceed 1 second, choose parallelism or JVM to choose by yourself
- If it is multiple CPUs, low pause time is pursued, and fast response is required (for example, the delay cannot exceed 1 second for Internet applications), Using concurrent collector
Recommended learning: "java video tutorial"
The above is the detailed content of A detailed introduction to the Java virtual machine: JVM garbage collector. For more information, please follow other related articles on the PHP Chinese website!




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



