This article brings you relevant knowledge about mysql, which mainly introduces the relevant content about the architectural principles. The MySQL Server architecture can be roughly divided into the network connection layer and the service layer from top to bottom. , storage engine layer and system file layer, let’s take a look at them together, I hope it will be helpful to everyone.

Recommended learning: mysql video tutorial
Mysql architecture principles
1. Mysql system architecture
MySQL Server architecture can be roughly divided into network connection layer, service layer, storage engine layer and system file layer from top to bottom.
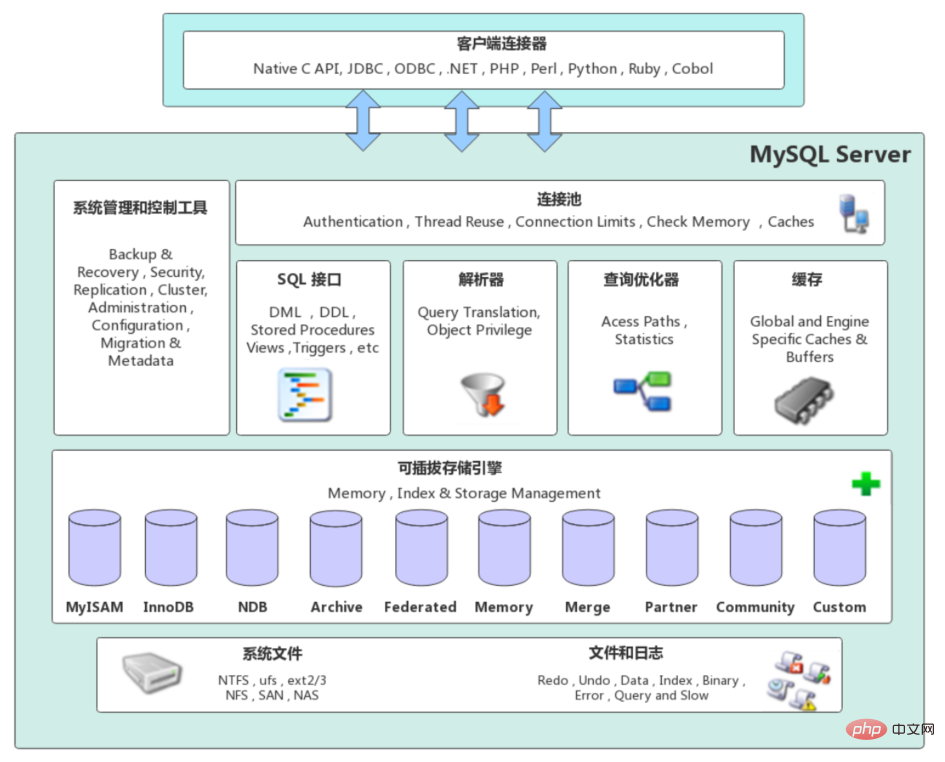
Network connection layer
- Client Connectors: Provides support for establishing with the MySQL server. Currently, it supports almost all mainstream server-side programming technologies, such as common Java, C, Python, .NET, etc. They establish connections with MySQL through their respective API technologies.
Service layer (MySQL Server)
The service layer is the core of MySQL Server and mainly includes system management and control tools, connection pools, SQL interfaces, parsers, query optimizers and Cache six parts.
Connection Pool: Responsible for storing and managing the connection between the client and the database. One thread is responsible for managing one connection.
System management and control tools (Management Services & Utilities): such as backup and recovery, security management, cluster management, etc.
SQL interface (SQL Interface): used to accept various SQL commands sent by the client and return the results that the user needs to query. Such as DML, DDL, stored procedures, views, triggers, etc.
Parser (Parser): Responsible for parsing the requested SQL to generate a "parse tree". Then further check whether the parse tree is legal according to some MySQL rules.
-
Query optimizer (Optimizer): When the "parse tree" passes the parser grammar check, it will be handed over to the optimizer to convert it into an execution plan, and then interact with the storage engine.
select uid, name from user where gender = 1;
Select--》Projection--》Join strategy
- select first based on where statement Selecting does not mean querying all the data and then filtering;
- select query performs attribute projection based on uid and name, but does not remove all fields;
- Connect the previous selection and projection to finally generate a query Result;
Cache (Cache&Buffer): The caching mechanism is composed of a series of small caches. For example, table cache, record cache, permission cache, engine cache, etc. If the query cache has a hit query result, the query statement can directly fetch data from the query cache.
Storage Engine Layer (Pluggable Storage Engines)
- The storage engine is responsible for the storage and retrieval of data in MySQL and interacts with the underlying system files. The MySQL storage engine is plug-in. The query execution engine in the server communicates with the storage engine through an interface. The interface shields the differences between different storage engines. There are many storage engines now, each with its own characteristics. The most common ones are MyISAM and InnoDB.
System File Layer (File System)
This layer is responsible for storing database data and logs on the file system and completing the interaction with the storage engine. It is the physical layer of the file. storage layer. Mainly includes log files, data files, configuration files, pid files, socket files, etc.
- Log file
- Error log (Error log)
- Enabled by default, show variables like '%log_error%';
## General query logRecord general query statements, show variables like '%general%';-
Records the change operations performed on the MySQL database, and records the occurrence time and execution time of the statement; however, it does not record select, show, etc. SQL that does not modify the database. Mainly used for database recovery and master-slave replication. - show variables like '%log_bin%'; //Whether to enable it
- show variables like '%binlog%'; //Parameter view
- show binary logs;// View the log file
-
Records all query SQL whose execution time times out. The default is 10 seconds. - show variables like '%slow_query%'; //Whether it is enabled
- show variables like '%long_query_time%'; //Duration
-
Configuration file is used to store all MySQL configuration information files, such as my.cnf, my.ini, etc. -
db.opt file: records the default character set and verification rules used by this library. - frm file: stores metadata (meta) information related to the table, including definition information of the table structure, etc. Each table will have a frm file.
- MYD file: It is dedicated to the MyISAM storage engine and stores the data of the MyISAM table. Each table will have a .MYD file.
- MYI file: It is dedicated to the MyISAM storage engine and stores index-related information of the MyISAM table. Each MyISAM table corresponds to a .MYI file.
- ibd file and IBDATA file: store InnoDB data files (including indexes). The InnoDB storage engine has two table space modes: exclusive table space and shared table space. Exclusive table spaces use .ibd files to store data, and each InnoDB table corresponds to one .ibd file. Shared table spaces use .ibdata files, and all tables use one (or multiple, self-configured) .ibdata files.
- ibdata1 file: system table space data file, which stores table metadata, Undo logs, etc.
- ib_logfile0, ib_logfile1 files: Redo log log files.
-
The pid file is a process file of the mysqld application in the Unix/Linux environment. Like many other Unix/Linux server programs, it stores with its own process id. -
The socket file is also only available in the Unix/Linux environment. Users do not need to connect through the TCP/IP network in the Unix/Linux environment. Instead, use Unix Socket directly to connect to MySQL. -
2. MySQL operating mechanism
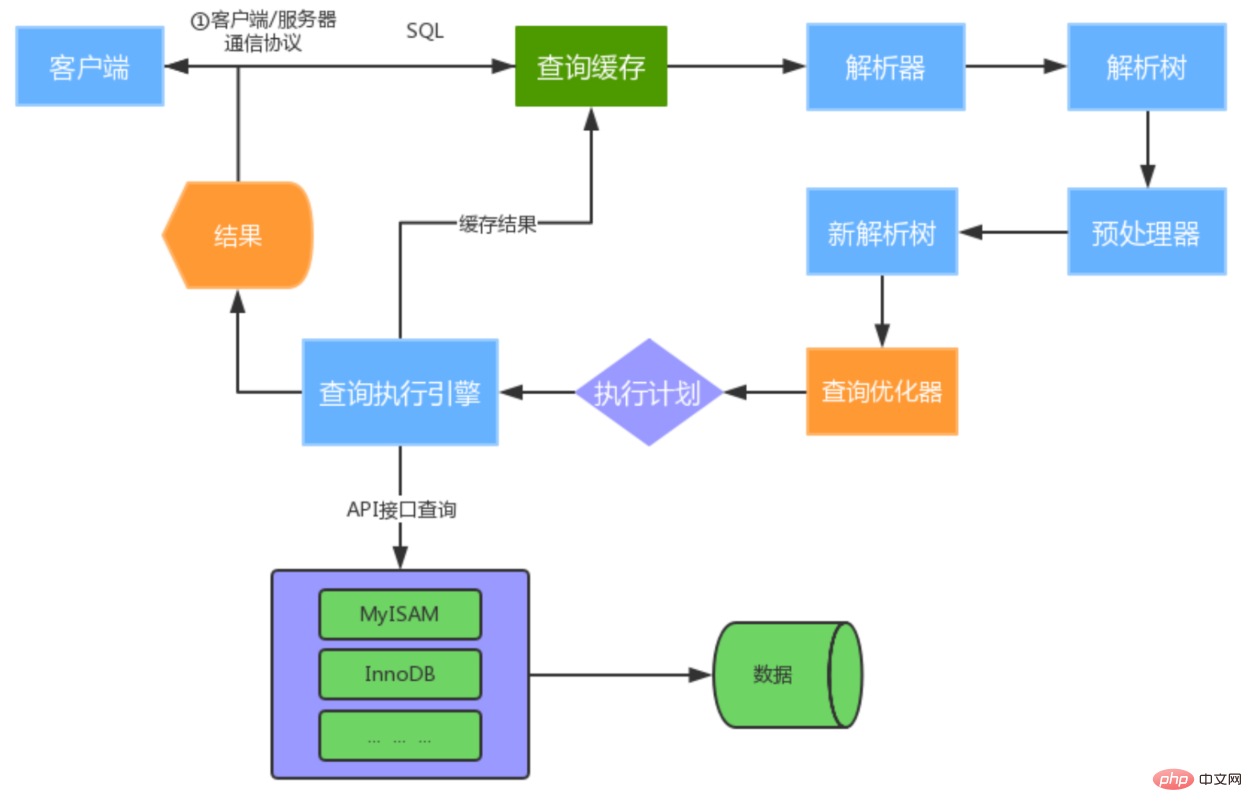
- Establish a connection (Connectors&Connection Pool) and establish a connection with MySQL through the client/server communication protocol. The communication method between MySQL client and server is "half-duplex". For each MySQL connection, there is a thread status at all times to identify what the connection is doing.
- Communication mechanism:
- Full duplex: can send and receive data at the same time, such as making phone calls.
- Half-duplex: refers to a certain moment, either sending data or receiving data, not at the same time. For example, early walkie-talkies
- simplex: can only send data or can only receive data. For example, one-way street;
- Thread status: show processlist; //View the thread information that the user is running. The root user can view all threads, and other users can only view their own;
- id: thread ID, you can use kill xx;
- user: the user who started this thread
- Host: the IP and port number of the client that sent the request
- db : In which library the current command is executed
- Command: The operation command being executed by this thread
- Create DB: The library operation is being created
- Drop DB: The library operation is being deleted
- Execute: Executing a PreparedStatement
- Close Stmt: Closing a PreparedStatement
- Query: Executing a statement
- Sleep: Waiting for the client to send a statement
- Quit: Exiting
- Shutdown: Shutting down the server
- Time: Indicates the time the thread is in the current state, the unit is seconds
- State: Thread status
- Updating: Searching for matching records and making modifications
- Sleeping: Waiting for the client to send a new request
- Starting: Request processing is being performed
- Checking table: Checking the data table
- Closing table: Refreshing the data in the table to the disk
- Locked: The record is locked by other queries
- Sending Data: Processing the Select query and sending the results to the client at the same time
- Info: Generally records the statements executed by the thread, and displays the first 100 characters by default. If you want to see the complete process list, use show full processlist;
- Query cache (Cache&Buffer), which is a place where MySQL can optimize queries. If the query cache is turned on and If the exact same SQL statement is queried during the query caching process, the query results will be returned directly to the client; if the query cache is not turned on or the exact same SQL statement is not queried, the parser will perform syntactic and semantic analysis and generate " Parse tree".
- Cache the results of the Select query and the SQL statement;
- When executing the Select query, first query the cache to determine whether there is an available record set and whether the requirements are exactly the same (including parameter values), so that Will match cached data hits;
- Even if the query cache is turned on, the following SQL cannot be cached:
- The query statement uses SQL_NO_CACHE
- The query result is greater than the query_cache_limit setting
- There are some uncertain parameters in the query, such as now()
- show variables like '%query_cache%'; //Check whether the query cache is enabled, space size, restrictions, etc.
- show status like 'Qcache%'; //View more detailed cache parameters, available cache space, cache blocks, cache size, etc.
- The parser (Parser) will client The SQL sent by the client performs syntax analysis and generates a "parse tree". The preprocessor further checks whether the "parse tree" is legal based on some MySQL rules. For example, it will check whether the data table and data column exist, and also parse names and aliases to see if they are ambiguous, and finally generate a new "parse tree" .
- The query optimizer (Optimizer) generates the optimal execution plan based on the "parse tree". MySQL uses many optimization strategies to generate optimal execution plans, which can be divided into two categories: static optimization (compile-time optimization) and dynamic optimization (run-time optimization).
- Equivalent transformation strategy
- 5=5 and a>5 is changed to a > 5
- a 5 and a =5
- Based on joint index, adjust condition position, etc.
- Optimize count, min, max and other functions
- InnoDB engine min function only needs to find the index The leftmost
- InnoDB engine max function only needs to find the rightmost index
- MyISAM engine count(*), no calculation is required, and it returns directly
- in advance Terminate query
- Use limit query to obtain the data required by limit without continuing to traverse the subsequent data
- Optimization of in
- MySQL for in The query will be sorted first, and then the binary method will be used to find the data. For example, where id in (2,1,3) becomes in (1,2,3);
- The query execution engine is responsible for executing SQL statements. This The query execution engine will obtain the query results and return them to the client based on the storage engine type of the table in the SQL statement and the interaction between the corresponding API interface and the underlying storage engine cache or physical file. If the query cache is enabled, the SQL statement and results will be completely saved in the query cache (Cache&Buffffer). If the same SQL statement is executed in the future, the results will be returned directly.
- If the query cache is enabled, cache the query results first.
- If there are too many results returned, use incremental mode to return.
- When starting execution, you must first make a judgment. Do you have permission to execute queries on this table T? If not, an error of no permission will be returned. (If the query cache is hit, permission verification will be done when the query cache returns the results. The query will also be called before the optimizer. precheck to verify permissions).
- If you have permission, open the table and continue execution. When a table is opened, the executor will use the interface provided by the engine based on the table's engine definition. The execution process of the executor is as follows:
- select * from test where age > 10;
- Call the InnoDB engine interface to get the first row of this table and determine whether the age value is 10. If not, skip it. If yes, store this row in the result set;
- Call the engine interface to get the "next row" and repeat the same judgment logic until the last row of the table is fetched.
- The executor returns a record set consisting of all rows that meet the conditions during the above traversal process to the client as a result set.
3. Mysql storage engine
The storage engine is located at the third layer in the MySQL architecture and is responsible for MySQL The storage and retrieval of data in is a subsystem that deals with files. It is a file access mechanism customized based on the file access layer abstract interface provided by MySQL. This mechanism is called a storage engine.
Use the show engines command to view the engine information supported by the current database. 
The MyISAM storage engine was used by default before version 5.5, and the InnoDB storage engine was used starting from 5.5.
- InnoDB: supports transactions, has commit, rollback and crash recovery capabilities, transaction security;
- MyISAM: does not support transactions and foreign keys, fast access speed;
- Memory : Use memory to create a table, the access speed is very fast, because the data is in memory, and the Hash index is used by default, but once it is closed, the data will be lost;
- Archive: Archive type engine, only supports insert and select statements ;
- Csv: Use CSV files for data storage. Due to file limitations, all columns must be forced to specify not null. In addition, the CSV engine does not support indexes and partitions, so it is suitable for intermediate tables for data exchange;
- BlackHole: Black hole, you can only go in but not out, it disappears when you enter, and all inserted data will not be saved;
- Federated: You can access tables in the remote MySQL database. A local table does not save data and accesses the contents of a remote table.
- MRG_MyISAM: A combination of a group of MyISAM tables. These MyISAM tables must have the same structure. The Merge table itself has no data. The Merge operation can operate on a group of MyISAM tables;
InnoDB Compare with MyISAM
- Transactions and foreign keys
- InnoDB supports transactions and foreign keys, has security and integrity, and is suitable for a large number of insert or update operations
- MyISAM does not Supporting transactions and foreign keys, it provides high-speed storage and retrieval, suitable for a large number of select query operations
- Lock mechanism
- InnoDB supports row-level locks and locks specified records. Locking is implemented based on index.
- MyISAM supports table-level locking, locking the entire table.
- Index structure
- InnoDB uses a clustered index (clustered index). The index and records are stored together, caching both the index and the records.
- MyISAM uses non-clustered index (non-clustered index), and the index and record are separated.
- Concurrency processing capability
- MyISAM uses table locks, which will lead to a low concurrency rate of write operations, no blocking between reads, and blocking of reads and writes.
- InnoDB read and write blocking can be related to the isolation level, and multi-version concurrency control (MVCC) can be used to support high concurrency
- Storage files
- InnoDB The table corresponds to two files, a .frm table structure file and an .ibd data file. InnoDB tables support a maximum of 64TB;
- The MyISAM table corresponds to three files, a .frm table structure file, a MYD table data file, and a .MYI index file. Starting from
MySQL5.0, the default limit is 256TB.
- Applicable scenarios
- MyISAM
- No transaction support required (not supported)
- Concurrency is relatively low (locking mechanism problem)
- Data modification is relatively small, mainly reading
- Data consistency requirements are not high
- InnoDB
- Requires transaction support (Has good transaction characteristics)
- Row-level locking has good adaptability to high concurrency
- Scenarios with more frequent data updates
- High data consistency requirements
- Hardware devices have large memory, and InnoDB’s better caching capabilities can be used to improve memory utilization and reduce disk IO
- Summary
- How to choose between the two engines?
- Are transactions required? Yes, is there concurrent modification in InnoDB
- ? Yes, does InnoDB
- pursue fast query and few data modifications? Yes, MyISAM
- In most cases, it is recommended to use InnoDB
InnoDB storage structure
Starting from MySQL version 5.5, InnoDB is used as the engine by default. It is good at processing transactions and has automatic crash recovery features. The following is the official InnoDB engine architecture diagram, which is mainly divided into two parts: memory structure and disk structure.
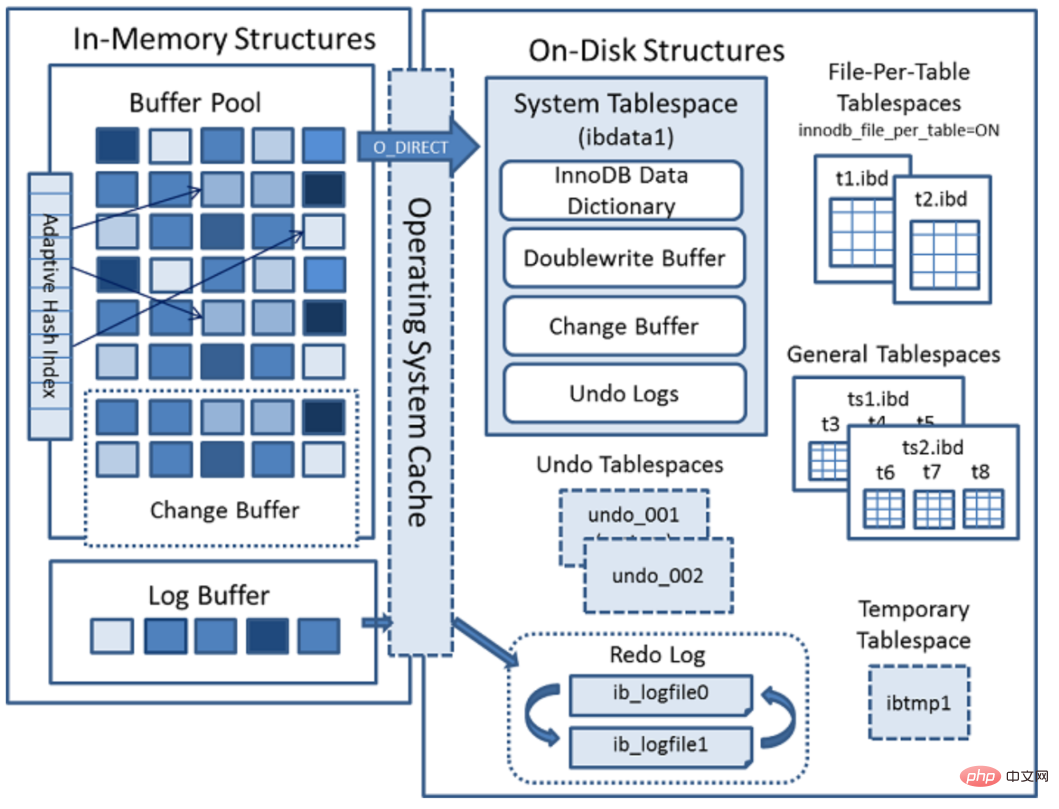
InnoDB memory structure
The memory structure mainly includes four major components: Buffer Pool, Change Buffer, Adaptive Hash Index and Log Buffer.
- Buffer Pool: Buffer pool, referred to as BP. BP is based on Page, with a default size of 16K. The bottom layer of BP uses a linked list data structure to manage Pages. When InnoDB accesses table records and indexes, they will be cached in the Page page. Later use can reduce disk IO operations and improve efficiency.
- Page management mechanism
- Page can be divided into three types according to status:
- free page: idle page, not used
- clean page: used Using page, the data has not been modified
- dirty page: Dirty page, using page, the data has been modified, the data in the page and the data on the disk are inconsistent
- For the above three page types, InnoDB maintains and manages it through three linked list structures:
- free list: represents the free buffer and manages free pages
- flush list: represents the need to be flushed to disk The buffer manages dirty pages, and the internal pages are sorted by modification time. Dirty pages exist in both the flush linked list and the LRU linked list, but they do not affect each other. The LRU linked list is responsible for managing the availability and storage of pages, while the flush linked list is responsible for managing the flushing operation of dirty pages.
- lru list: Indicates the buffer in use, manages clean page and dirty page, the buffer is based on midpoint, the front linked list is called the new list area, which stores frequently accessed data, accounting for 63%; the latter The linked list is called the old list area, which stores less used data, accounting for 37%.
-
Improved LRU algorithm maintenance
- Ordinary LRU: end elimination method, new data is added from the head of the linked list, and is eliminated from the end when space is released
- Modified LRU: the linked list is divided into two parts, new and old, when adding elements It is not inserted from the head of the table, but from the middle midpoint position. If the data is accessed soon, the page will move to the head of the new list. If the data has not been accessed, it will gradually move to the end of the old list, waiting for elimination.
- Whenever new page data is read into the buffer pool, the InnoDb engine will determine whether there are free pages and whether they are enough. If there are free pages, the free page will be deleted from the free list and placed in the LRU list. . If there are no free pages, the default page of the LRU linked list will be eliminated according to the LRU algorithm, and the memory space will be released and allocated to new pages.
- Buffer Pool configuration parameters
- show variables like '%innodb_page_size%'; //View page size
- show variables like '%innodb_old% '; //View the old list parameters in the lru list
- show variables like '%innodb_buffer%'; //View the buffer pool parameters
- Recommendation: Set innodb_buffer_pool_size to 60% of the total memory size -80%, innodb_buffer_pool_instances can be set to multiple to avoid cache contention.
- Change Buffer: Write buffer, referred to as CB. When performing a DML operation, if BP does not have its corresponding Page data, the disk page will not be loaded into the buffer pool immediately. Instead, the buffer changes will be recorded in CB, and when the future data is read, the data will be merged and restored to BP. middle.
- ChangeBuffer occupies the BufferPool space. The default is 25% and the maximum allowed is 50%. It can be adjusted according to the read and write business volume. Parameter innodb_change_buffer_max_size;
- When a record is updated, the record exists in the BufferPool and is modified directly in the BufferPool, a memory operation. If the record does not exist in the BufferPool (no hit), a memory operation will be performed directly in the ChangeBuffer without having to query the disk for data and avoid a disk IO. When the record is queried next time, it will be read from the disk first, then the information will be read from the ChangeBuffer and merged, and finally loaded into the BufferPool.
- Write buffer, only applicable to non-unique ordinary index pages
- If uniqueness is set in the index, InnoDB must perform uniqueness verification when making modifications, so the disk must be queried. Perform an IO operation. The record will be directly queried into the BufferPool and then modified in the buffer pool. It will not be operated in ChangeBuffer.
- Adaptive Hash Index: Adaptive Hash Index, used to optimize queries for BP data. The InnoDB storage engine will monitor the search for table indexes. If it is observed that building a hash index can improve the speed, it will build a hash index, so it is called adaptive. The InnoDB storage engine automatically creates hash indexes for certain pages based on the frequency and pattern of access.
- Log Buffer: The log buffer is used to save the data to be written to the log file (Redo/Undo) on the disk. The contents of the log buffer are regularly refreshed to the disk log file. When the log buffer is full, it will be automatically flushed to disk. When encountering large transaction operations such as BLOB or multi-row updates, increasing the log buffer can save disk I/O.
- LogBuffer is mainly used to record InnoDB engine logs. Redo and Undo logs will be generated during DML operations;
- When the LogBuffer space is full, it will be automatically written to the disk.You can reduce the disk IO frequency by increasing the innodb_log_buffer_size parameter; the
- innodb_flush_log_at_trx_commit parameter controls the log refresh behavior. The default is 1
- 0: write log files and flush disk operations every 1 second (write Log file LogBuffer --> OS cache, flush OScache --> disk file), data will be lost for up to 1 second
- 1: Transaction commit, write log file and flush disk immediately, data will not be lost, but There will be frequent IO operations
- 2: The transaction is submitted, the log file is written immediately, and the disk flush operation is performed every 1 second
InnoDB disk structure
InnoDB disk mainly includes Tablespaces, InnoDB Data Dictionary, Doublewrite Buffer, Redo Log and Undo Logs.
-
Tablespaces: used to store table structures and data. Table spaces are divided into system table spaces, independent table spaces, general table spaces, temporary table spaces, Undo table spaces and other types;
- ##Data Dictionary (InnoDB Data Dictionary)
InnoDB Data Dictionary consists of internal system tables Composed of tables that contain metadata for objects such as lookup tables, indexes, and table fields. Metadata is physically located in the InnoDB system tablespace. For historical reasons, data dictionary metadata overlaps to a certain extent with the information stored in InnoDB table metadata files (.frm files). -
- Doublewrite Buffer (Doublewrite Buffer)
is located in the system table space and is a storage area. Before the BufferPage page is refreshed to the real location on the disk, the data will be stored in the Doublewrite buffer. If the operating system, storage subsystem, or mysqld process crashes while the page is being written, InnoDB can find a good backup of the page from the Doublewrite buffer during crash recovery. In most cases, the doublewrite buffer is enabled by default. To disable the Doublewrite buffer, you can set innodb_doublewrite to 0. It is recommended to set innodb_flush_method to O_DIRECT when using Doublewrite buffer. MySQL's innodb_flush_method parameter controls the opening and flushing modes of innodb data files and redo logs. There are three values: fdatasync (default), O_DSYNC, O_DIRECT. Setting O_DIRECT means that the data file writing operation will notify the operating system not to cache the data, do not use pre-reading, and write directly from InnodbBuffer to the disk file. - The default fdatasync means to write to the operating system cache first, and then call the fsync() function to asynchronously flush the cache information of the data file and redo log.
-
- Redo Log
- The redo log is a disk-based data structure used to correct data written by incomplete transactions during crash recovery. MySQL writes redo log files in a circular manner and records all modifications to the Buffer Pool in InnoDB. When an instance failure occurs (such as a power outage) and the data fails to be updated to the data file, the database must be redoed when the database is restarted to update the data to the data file again. During the execution of read and write transactions, redo logs will continue to be generated. By default, the redo log is physically represented on disk by two files named ib_logfile0 and ib_logfile1.
-
Undo Logs
- The undo log is a backup of the modified data saved before the transaction starts, used for exceptions Roll back the transaction. The undo log is a logical log and is recorded on a per-line basis. Undo logs exist in system tablespaces, undo tablespaces, and temporary tablespaces.
New version structure evolution
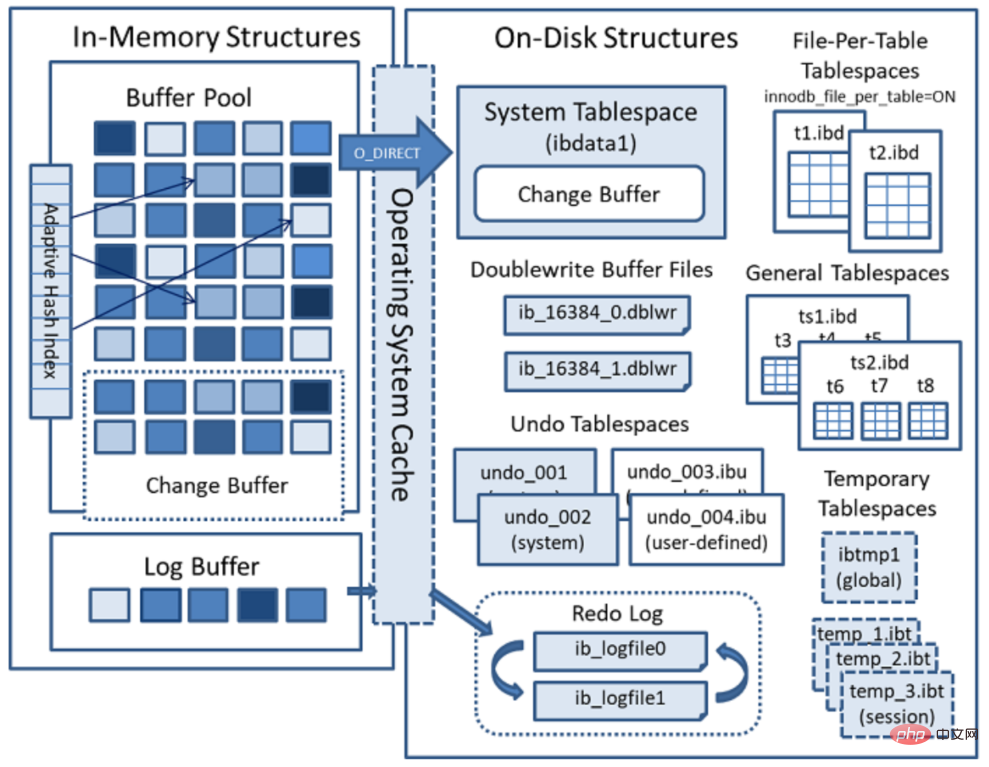
- MySQL 5.7 version
- Undo log table The space is separated from the shared table space ibdata file, and the file size and quantity can be specified by the user when installing MySQL.
- Added temporary temporary table space, which stores data of temporary tables or temporary query result sets.
- The Buffer Pool size can be modified dynamically without restarting the database instance.
- MySQL 8.0 version
- The data dictionary and Undo of the InnoDB table are completely separated from the shared table space ibdata. In the past, the data dictionary and independent table in ibdata were needed. The data dictionary in the space ibd file must be consistent, which is not required in version 8.0.
- temporary Temporary table space can also be configured with multiple physical files, and they are all InnoDB storage engines and can create indexes, which speeds up the processing.
- Users can set up some table spaces like Oracle database. Each table space corresponds to multiple physical files. Each table space can be used by multiple tables, but a table can only be stored in one table space.
- The Doublewrite Buffer is also separated from the shared table space ibdata.
InnoDB thread model
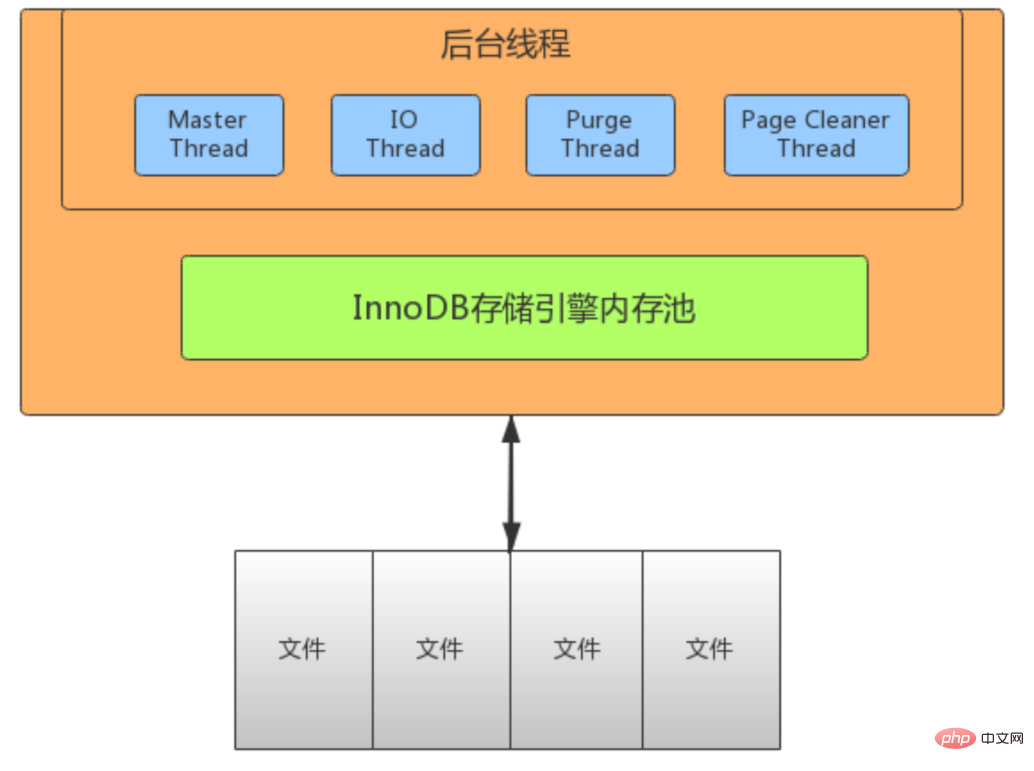
- IO Thread
- is used extensively in InnoDB AIO (Async IO) is used for reading and writing, which can greatly improve the performance of the database. There are 10 IO Threads in
InnoDB, namely 4 writes, 4 reads, 1 insert buffer and 1 log thread.
- read thread: Responsible for reading operations and loading data from disk to cache page. 4
- write threads: responsible for write operations and flushing cached dirty pages to disk. 4
- log threads: Responsible for flushing the log buffer contents to disk. 1
- insert buffer thread: Responsible for flushing the write buffer content to disk. After a
- Purge Thread
- transaction is committed, the undo log used by it will no longer be needed, so Purge Thread needs to recycle the allocated undo page.
- show variables like '%innodb_purge_threads%';
- Page Cleaner Thread
- The function is to flush dirty data to the disk. After the dirty data is flushed The corresponding redo log can also be overwritten, which can synchronize data and
achieve the purpose of redo log recycling. The write thread thread processing will be called.
- show variables like '%innodb_page_cleaners%';
- Master Thread
- Master thread is the main thread of InnoDB, responsible for scheduling other threads, priority The highest level. Its function is to asynchronously refresh the data in the buffer pool to the disk to ensure data consistency. Including: dirty page refresh (page cleaner thread), undo page recycling (purge thread), redo log refresh (log thread), merged write buffer, etc. There are two main processes inside, one every 1 second and one every 10 seconds.
- Operations every 1 second:
- Refresh the log buffer and flush to the disk
- Merge the write buffer data and decide whether to operate based on the IO read and write pressure
- Refresh dirty page data to disk, and operate only when the dirty page ratio reaches 75% (innodb_max_dirty_pages_pct,
innodb_io_capacity)
- Operation every 10 seconds:
- Refresh dirty page data to disk
- Merge write buffer data
- Refresh log buffer
- Delete useless undo pages
InnoDB data file
InnoDB file storage structure
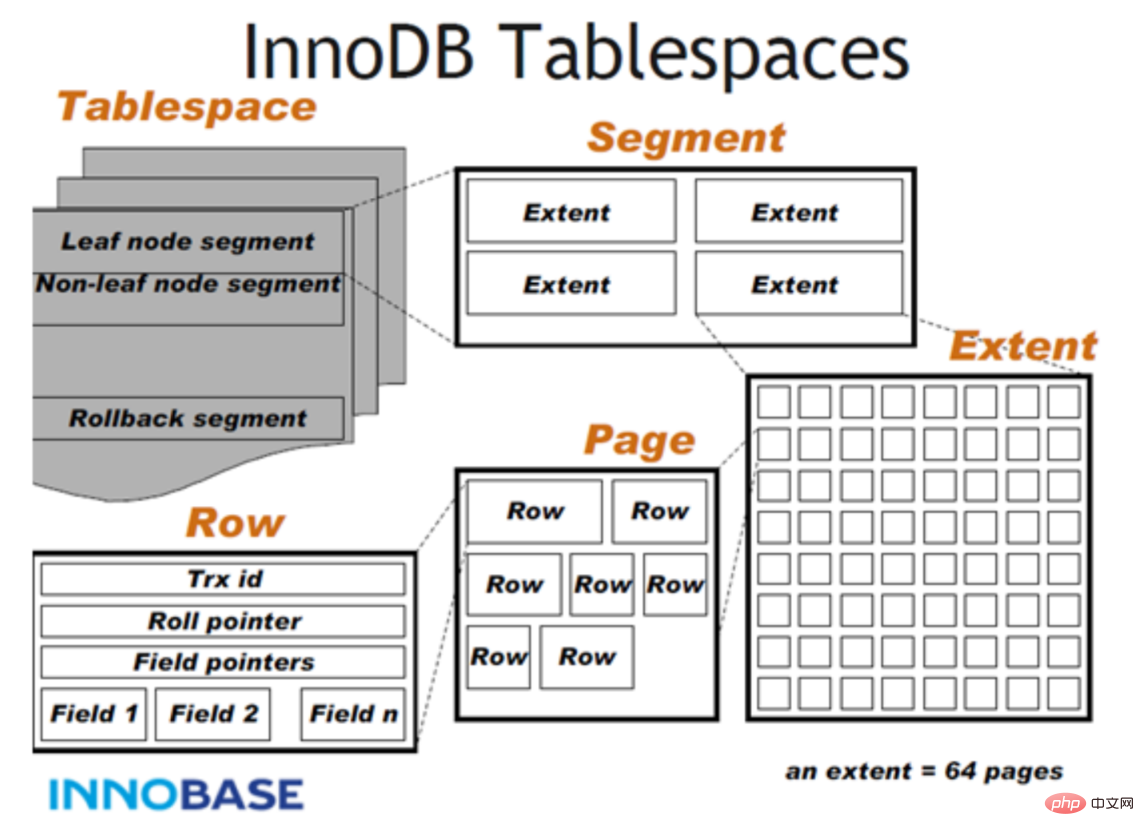
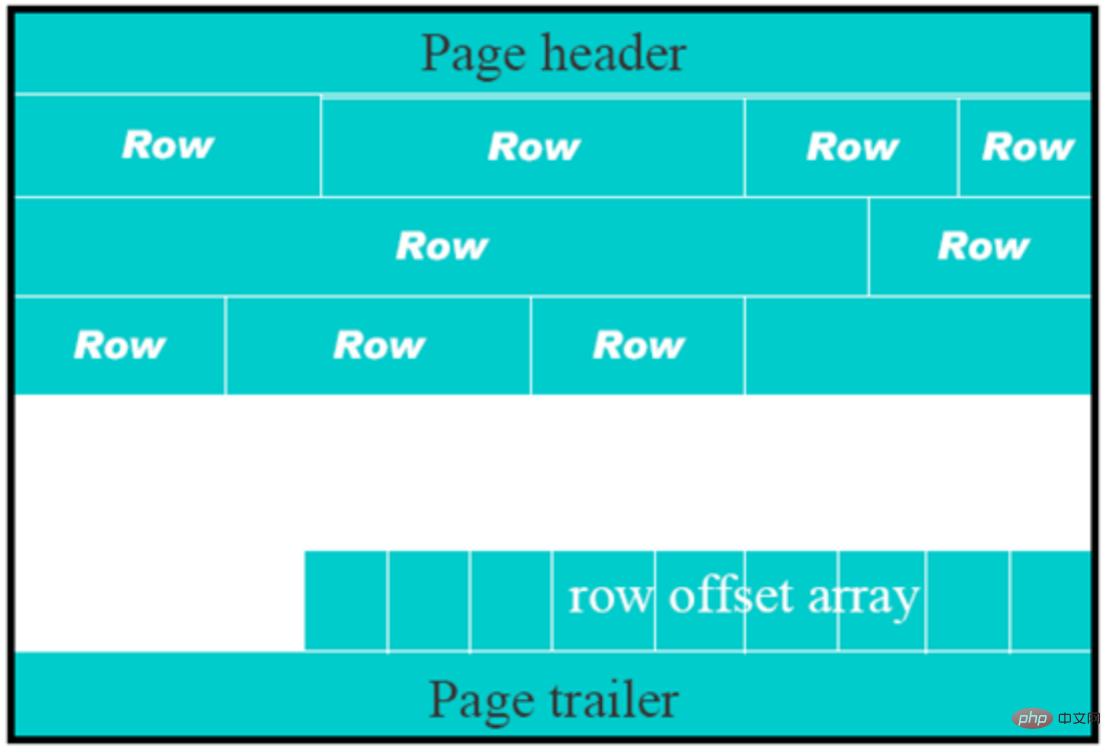
-
InnoDB文件存储格式
-
File文件格式(File-Format)
- 在早期的InnoDB版本中,文件格式只有一种,随着InnoDB引擎的发展,出现了新文件格式,用于支持新的功能。目前InnoDB只支持两种文件格式:Antelope 和 Barracuda。
- Antelope: 先前未命名的,最原始的InnoDB文件格式,它支持两种行格式:COMPACT和REDUNDANT,MySQL 5.6及其以前版本默认格式为Antelope。
- Barracuda: 新的文件格式。它支持InnoDB的所有行格式,包括新的行格式:COMPRESSED和 DYNAMIC。
- 通过innodb_file_format 配置参数可以设置InnoDB文件格式,之前默认值为Antelope,5.7版本开始改为Barracuda。
Row行格式(Row_format)
-
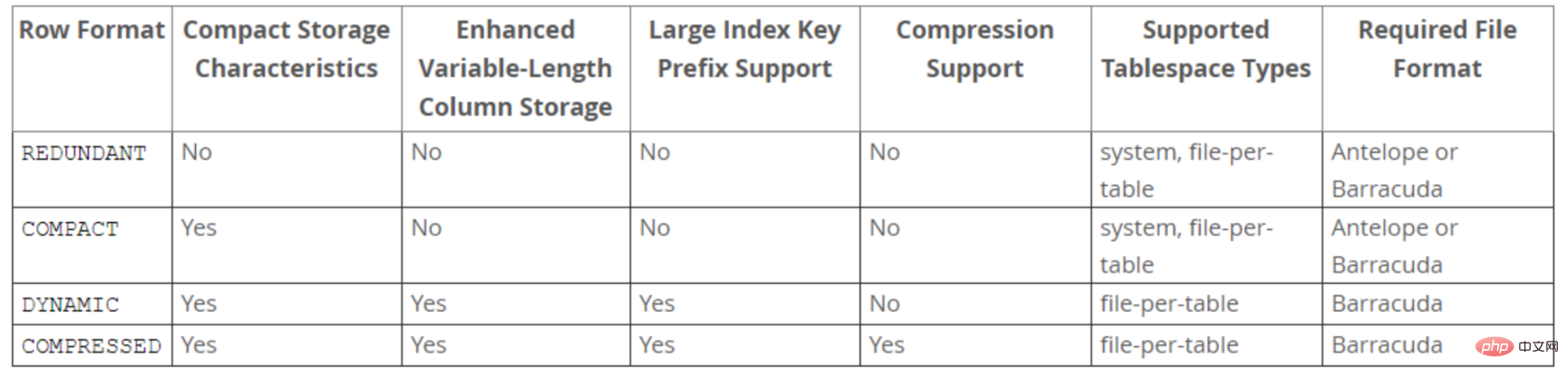
表的行格式决定了它的行是如何物理存储的,这反过来又会影响查询和DML操作的性能。如果在单个page页中容纳更多行,查询和索引查找可以更快地工作,缓冲池中所需的内存更少,写入更新时所需的I/O更少。
InnoDB存储引擎支持四种行格式:REDUNDANT、COMPACT、DYNAMIC和COMPRESSED。
DYNAMIC和COMPRESSED新格式引入的功能有:数据压缩、增强型长列数据的页外存储和大索引前缀。
每个表的数据分成若干页来存储,每个页中采用B树结构存储;
-
如果某些字段信息过长,无法存储在B树节点中,这时候会被单独分配空间,此时被称为溢出页,该字段被称为页外列。
- REDUNDANT 行格式
- 使用REDUNDANT行格式,表会将变长列值的前768字节存储在B树节点的索引记录中,其余
的存储在溢出页上。对于大于等于786字节的固定长度字段InnoDB会转换为变长字段,以便
能够在页外存储。
- COMPACT 行格式
- 与REDUNDANT行格式相比,COMPACT行格式减少了约20%的行存储空间,但代价是增加了
某些操作的CPU使用量。如果系统负载是受缓存命中率和磁盘速度限制,那么COMPACT格式
可能更快。如果系统负载受到CPU速度的限制,那么COMPACT格式可能会慢一些。
- DYNAMIC 行格式
- 使用DYNAMIC行格式,InnoDB会将表中长可变长度的列值完全存储在页外,而索引记录只包含指向溢出页的20字节指针。大于或等于768字节的固定长度字段编码为可变长度字段。DYNAMIC行格式支持大索引前缀,最多可以为3072字节,可通过innodb_large_prefix参数控制。
- COMPRESSED 行格式
- COMPRESSED行格式提供与DYNAMIC行格式相同的存储特性和功能,但增加了对表和索引
数据压缩的支持。
-
在创建表和索引时,文件格式都被用于每个InnoDB表数据文件(其名称与*.ibd匹配)。修改文件格式的方法是重新创建表及其索引,最简单方法是对要修改的每个表使用以下命令:
ALTER TABLE 表名 ROW_FORMAT=格式类型;
Copy after login
Undo Log
Undo Log介绍
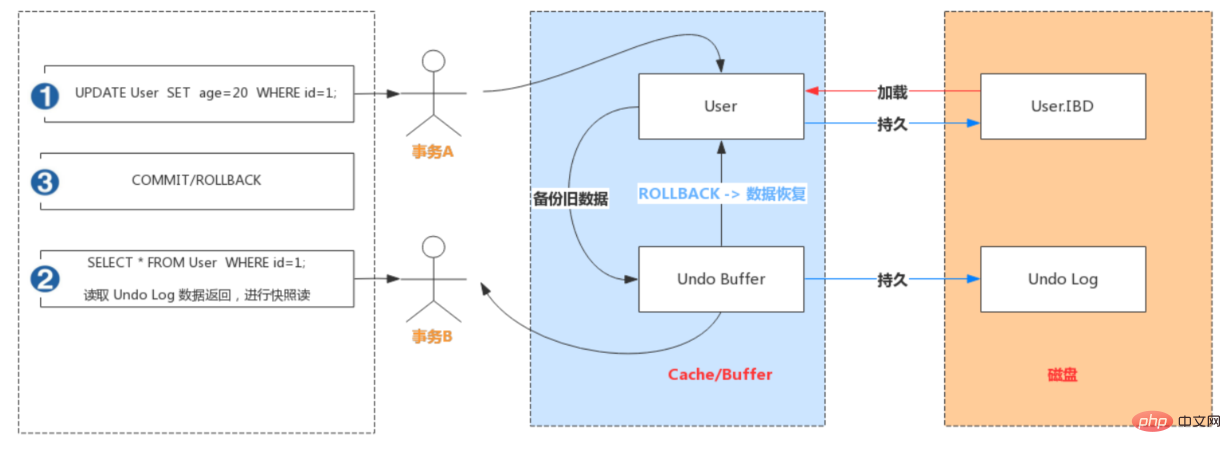
Undo:意为撤销或取消,以撤销操作为目的,返回指定某个状态的操作。
Undo Log:数据库事务开始之前,会将要修改的记录存放到 Undo 日志里,当事务回滚时或者数据库崩溃时,可以利用 Undo 日志,撤销未提交事务对数据库产生的影响。
Undo Log产生和销毁:Undo Log在事务开始前产生;事务在提交时,并不会立刻删除undo log,innodb会将该事务对应的undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理。Undo Log属于逻辑日志,记录一个变化过程。例如执行一个delete,undolog会记录一个insert;执行一个update,undolog会记录一个相反的update。
Undo Log存储:undo log采用段的方式管理和记录。在innodb数据文件中包含一种rollback segment回滚段,内部包含1024个undo log segment。可以通过下面一组参数来控制Undo log存储。
#相关参数命令
show variables like '%innodb_undo%';
Copy after login
Undo Log作用
- 实现事务的原子性
- Undo Log 是为了实现事务的原子性而出现的产物。事务处理过程中,如果出现了错误或者用户执行了 ROLLBACK 语句,MySQL 可以利用 Undo Log 中的备份将数据恢复到事务开始之前的状态。
-
实现多版本并发控制(MVCC)
Redo Log 日志
-
Redo Log 介绍
- Redo:顾名思义就是重做。以恢复操作为目的,在数据库发生意外时重现操作。
- Redo Log:指事务中修改的任何数据,将最新的数据备份存储的位置(Redo Log),被称为重做日志。
- Redo Log 的生成和释放:随着事务操作的执行,就会生成Redo Log,在事务提交时会将产生Redo Log写入Log Buffer,并不是随着事务的提交就立刻写入磁盘文件。等事务操作的脏页写入到磁盘之后,Redo Log 的使命也就完成了,Redo Log占用的空间就可以重用(被覆盖写入)。
Redo Log工作原理
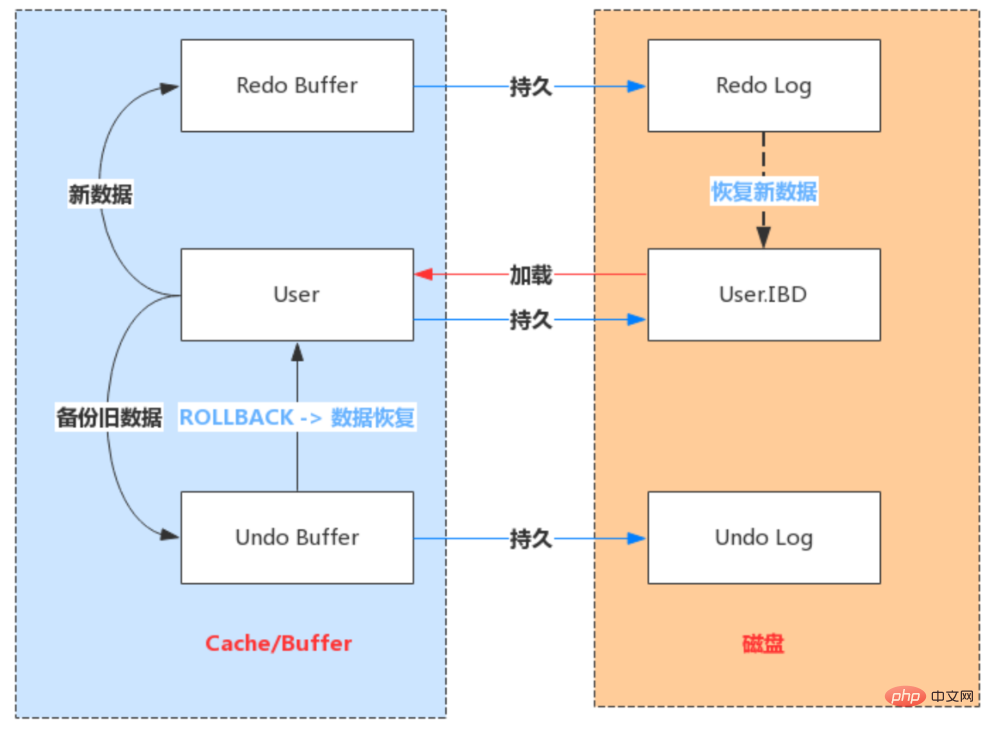
- Redo Log 是为了实现事务的持久性而出现的产物。防止在发生故障的时间点,尚有脏页未写入表
的 IBD 文件中,在重启 MySQL 服务的时候,根据 Redo Log 进行重做,从而达到事务的未入磁盘
数据进行持久化这一特性。
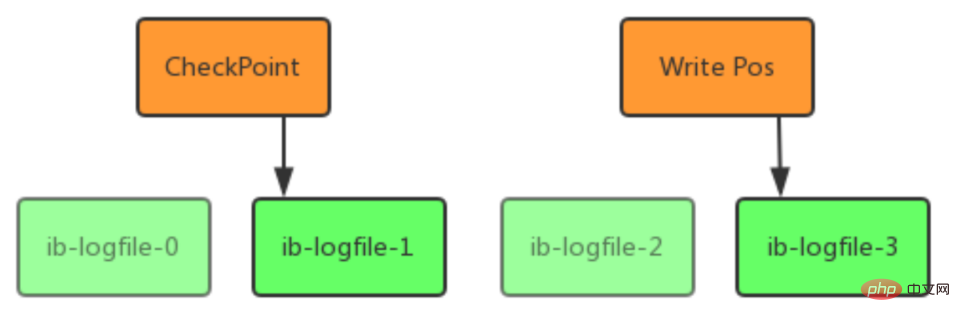
- write pos 是当前记录的位置,一边写一边后移,写到最后一个文件末尾后就回到 0 号文件开头;
- checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件;
- write pos 和 checkpoint 之间还空着的部分,可以用来记录新的操作。如果 write pos 追上checkpoint,表示写满,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint推进一下。
-
Redo Log相关配置参数
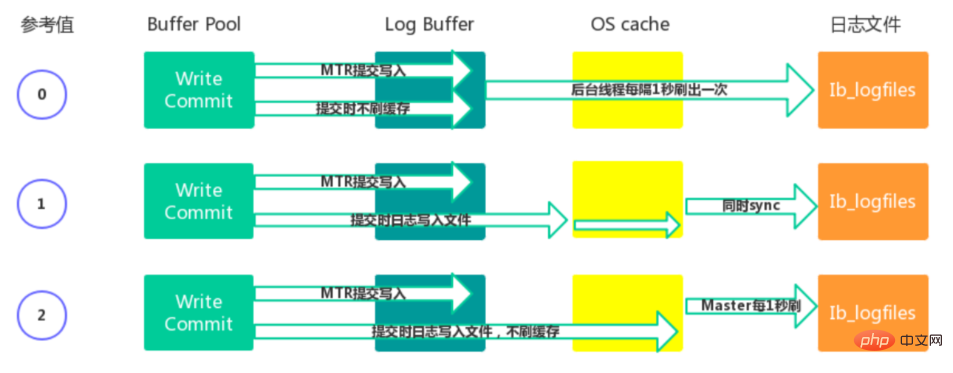
- 0:每秒提交 Redo buffer ->OS cache -> flush cache to disk,可能丢失一秒内的事务数据。由后台Master线程每隔 1秒执行一次操作。
- 1(默认值):每次事务提交执行 Redo Buffer -> OS cache -> flush cache to disk,最安全,性能最差的方式。
- 2:每次事务提交执行 Redo Buffer -> OS cache,然后由后台Master线程再每隔1秒执行OS cache -> flush cache to disk 的操作。
- 一般建议选择取值2,因为 MySQL 挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数
据。
Binlog日志
-
Binlog 记录模式
- Redo Log 是属于InnoDB引擎所特有的日志,而MySQL Server也有自己的日志,即 Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
- 主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
- 数据恢复:通过mysqlbinlog工具来恢复数据。
- Binlog文件名默认为“主机名_binlog-序列号”格式,例如oak_binlog-000001,也可以在配置文件中指定名称。文件记录模式有STATEMENT、ROW和MIXED三种,具体含义如下。
- ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
- 优点:能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。
- 缺点:批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。
- STATMENT(statement-based replication, SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。
- 优点:日志量小,减少磁盘IO,提升存储和恢复速度
- 缺点:在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。
- MIXED(mixed-based replication, MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择写入模式。
-
Binlog 文件结构

-
Binlog写入机制
- 根据记录模式和操作触发event事件生成log event(事件触发执行机制)
- 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
- 事务在提交阶段会将产生的log event写入到外部binlog文件中。
- 不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在binlog文件中是连续的,中间不会插入其他事务的log event。
-
Binlog文件操作
- 根据记录模式和操作触发event事件生成log event(事件触发执行机制)
- 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区
- Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
- 事务在提交阶段会将产生的log event写入到外部binlog文件中。
- 不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在
binlog文件中是连续的,中间不会插入其他事务的log event。
-
Binlog文件操作
-
Binlog状态查看
show variables like 'log_bin';
Copy after login
-
开启Binlog功能
-
使用show binlog events命令
show binary logs; //等价于show master logs;
show master status;
show binlog events;
show binlog events in 'mysqlbinlog.000001';
Copy after login
-
使用 mysqlbinlog 命令
mysqlbinlog "文件名"
mysqlbinlog "文件名" > "test.sql"
Copy after login
-
使用 binlog 恢复数据
-
删除Binlog文件
-
Redo Log和 Binlog区别
- Redo Log是属于InnoDB引擎功能,Binlog是属于MySQL Server自带功能,并且是以二进制文件记录。
- Redo Log属于物理日志,记录该数据页更新状态内容,Binlog是逻辑日志,记录更新过程。
- Redo Log日志是循环写,日志空间大小是固定,Binlog是追加写入,写完一个写下一个,不会覆盖使用。
- Redo Log作为服务器异常宕机后事务数据自动恢复使用,Binlog可以作为主从复制和数据恢复使用。Binlog没有自动crash-safe能力。
推荐学习:mysql视频教程
The above is the detailed content of Detailed graphic explanation of mysql architecture principles. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



