

This article brings you relevant knowledge about Redis, which mainly introduces the related issues about the Redis hot key large Value solution. Let’s take a look at it together. I hope it will be helpful to everyone. .

Recommended learning: Redis video tutorial
About Redis hot data & big key big value questions are also easy to ask high-level questions It is better to learn the problem at once and leave the interviewer speechless. In my personal work experience, hot data problems are more likely to be encountered at work than avalanches. However, most of the time, the hot spots are not hot enough and will be alerted and solved in advance. But once this problem cannot be controlled, the online problems caused will be enough to put your performance at the bottom this year. Let’s not talk nonsense and get to the point.
Under normal circumstances, data in the Redis cluster is evenly distributed to each node, and requests are evenly distributed to each shard. However, in some special scenarios, such as external crawlers, attacks, and hot products Wait, the most typical example is when a celebrity announces their divorce on Weibo, and people flood in to leave messages, causing the Weibo comment function to crash. In this short period of time, the number of visits to certain keys is too large, and requests will be made for the same keys. to the same data shard, resulting in a high load on the shard and becoming a bottleneck, leading to a series of problems such as avalanches.
Problem analysis: I was asked this question last time when I heard a big boss in the group interview Ali p7. The difficulty index is five stars. Wait for me. Being a noob is really a plus.
Answer: I have something to say about hot data. I have been aware of this problem since I first learned to use Redis, so when using it We will deliberately avoid and resolutely not dig holes for ourselves. The biggest problem with hotspot data will cause failures caused by unbalanced load in the Redis cluster (that is, data skew). These problems are fatal blows to the Redis cluster.
Let’s first talk about the main reasons for the Reids cluster load imbalance failure:
So what faults will be caused by hot keys or large Values:
Answer: The solution to this problem is relatively broad. It depends on different business scenarios. For example, if a company organizes promotional activities, then there must be a way to count the products participating in the promotion in advance. , this scenario can pass the estimation method. For emergencies and uncertainties, Redis will monitor hotspot data by itself. To sum up:
public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) {
//从参数中获取key
String key = analysis(args);
//计数
counterKey(key);
//ignore
}Redis cluster proxy layer statistics:
Agent-based Redis distributed architectures such as Twemproxy and codis have a unified entrance and can be collected and reported at the Proxy layer. But the disadvantage is obvious. Not all Redis cluster architectures have proxies.
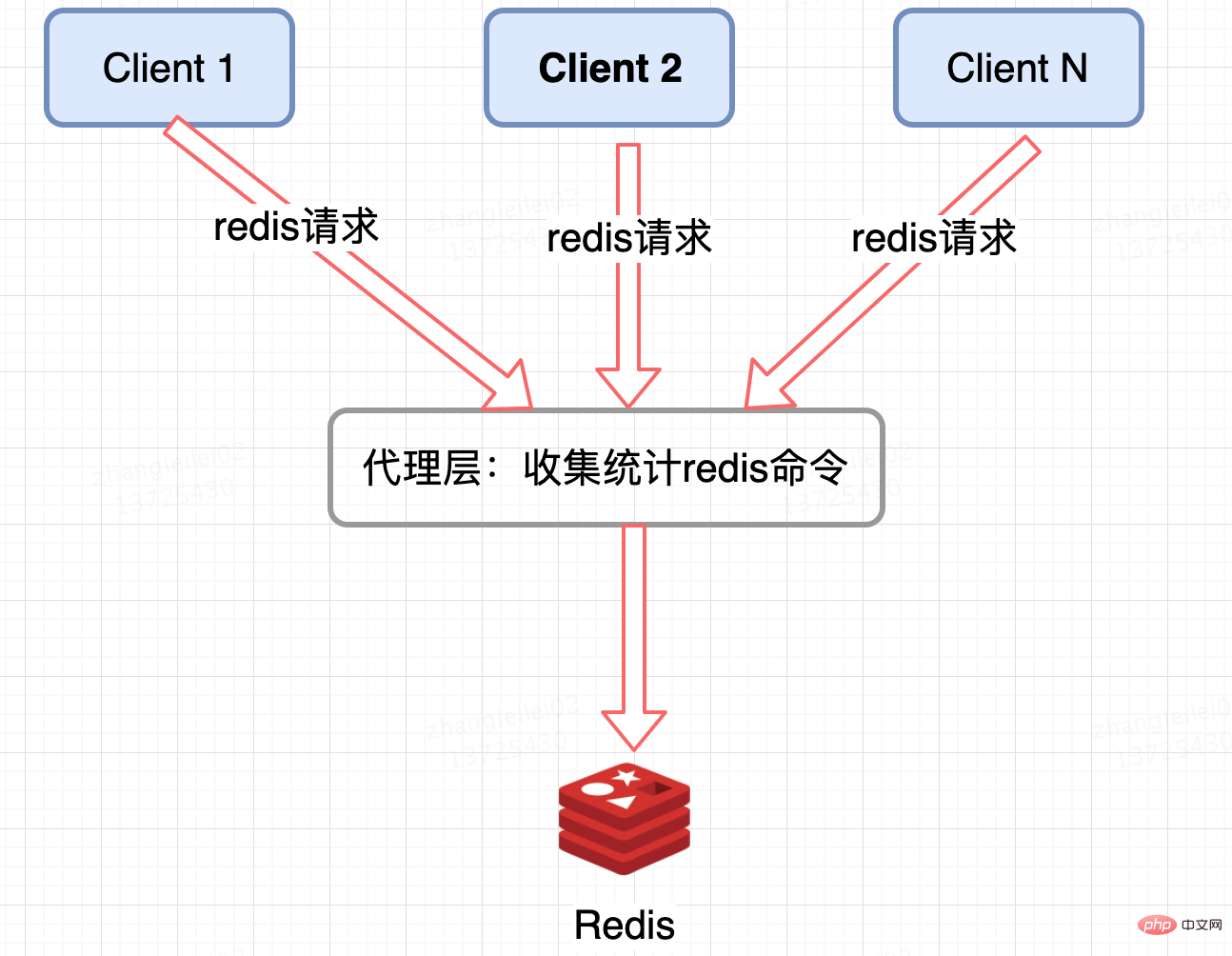
Redis server collection:
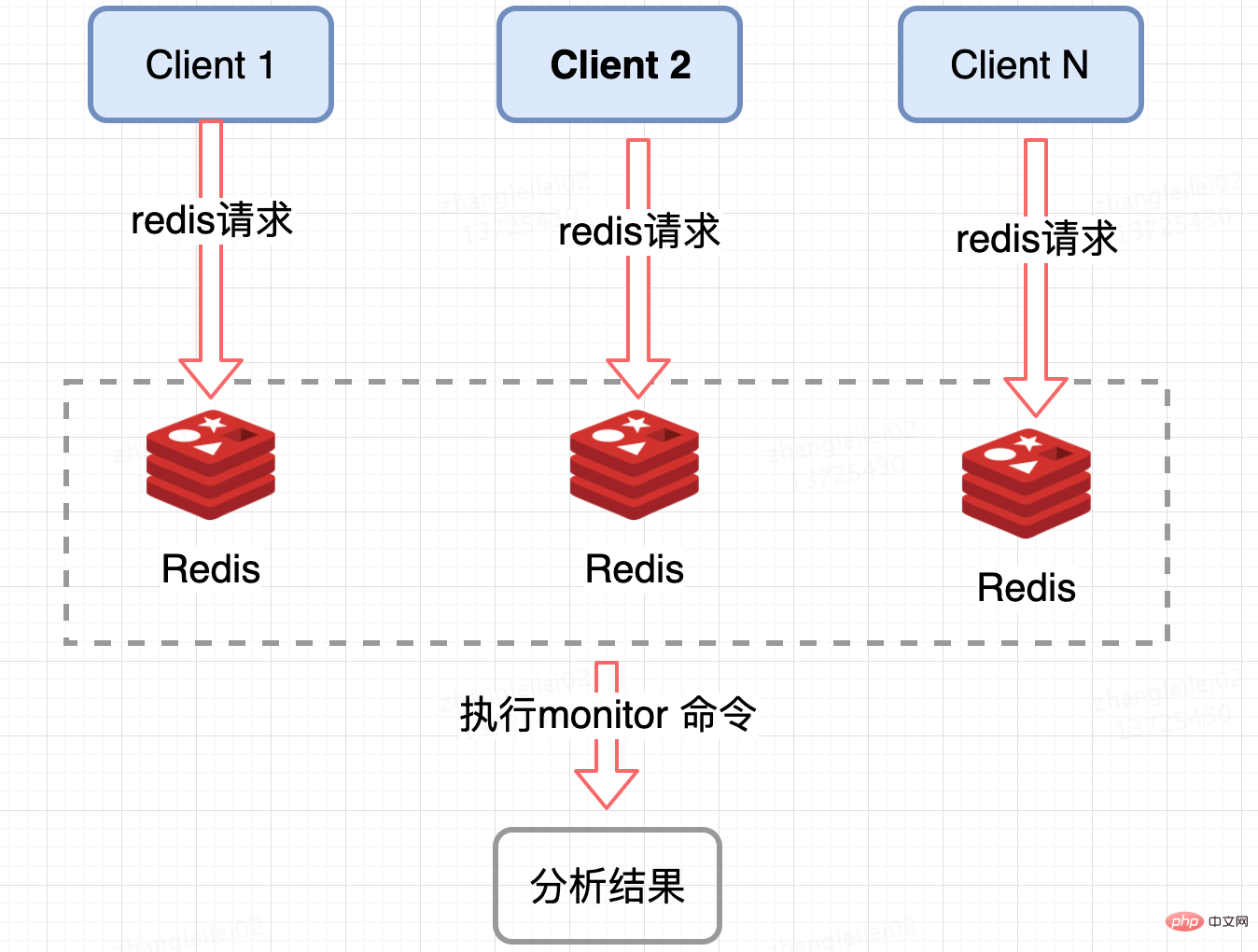
Monitor the QPS of a single Redis shard, and monitor the node where the QPS is tilted to a certain extent to obtain the hotspot key. Redis provides a monitor command, you can count all the commands on a certain Redis node within a period of time and analyze the hot key. Under high concurrency conditions, there will be hidden dangers of memory explosion and Redis performance, so this method is suitable for use in a short period of time; it is also only It can count the hotspot keys of a Redis node. For clusters, summary statistics are needed, which is a little troublesome from a business perspective.
The above four methods are commonly used in the industry. I have a new idea by studying the Redis source code. Type 5: Modify the Redis source code.
Modify the Redis source code: (Thinking of ideas from reading the source code)
I found that Redis4.0 has brought us many new things Features, including the LFU-based hotspot key discovery mechanism. With this new feature, we can implement hotspot key statistics on this basis. This is just my personal idea.
Interviewer's psychology: The young man is quite thoughtful and broad-minded, and he also pays attention to modifying the source code. I don't have this ambition. We need people like this in our team.
(Discover problems, analyze problems, solve problems, and directly tell how to solve hot data problems without waiting for the interviewer to ask questions. This is the core content)
Answer: Regarding how to manage hot data issues, we mainly consider two aspects to solve this problem. The first is data sharding, so that The pressure is evenly distributed to multiple shards of the cluster to prevent a single machine from hanging. The second is migration isolation.
Summary summary:
Interviewer: You answered very well and considered it very comprehensively.
Problem analysis: Compared with the big concept of hot key, the concept of big Value is better to understand. Since Redis runs in a single thread, if the value of an operation is very large, it will affect the entire operation. The response time of redis has a negative impact because Redis is a Key-Value structure database. A large value means that a single value takes up a large amount of memory. The most direct impact on the Redis cluster is data skew.
Answer: (You want to stump me? I am prepared.)
Let me first talk about how big the Value is, which is given based on the company's infrastructure. The experience value can be divided as follows:
Note: (The experience value is not a standard, it is summarized based on long-term observation of online cases by cluster operation and maintenance personnel)
Since Redis runs in a single thread, if the value of an operation is very large, it will have a negative impact on the response time of the entire redis. Therefore, it can be split if it can be split in terms of business. Here are a few typical splits: Demolition plan:
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
推荐学习:Redis学习教程
The above is the detailed content of Let's analyze the solutions to Redis hot data problems together. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



