


This article brings you the relevant knowledge about indexing in mysql database, which contains almost all the knowledge points of indexing. I hope it will be helpful to everyone.

The official introduction of index is Data structure that helps MySQLobtain data efficiently. To put it more generally, a database index is like the table of contents at the front of a book, which can speed up database queries.
Generally speaking, the index itself is also very large, and it is impossible to store it all in memory, so the index is often stored in a file on the disk (possibly stored In a separate index file, or possibly stored together with the data in the data file).
What we usually call indexes include clustered indexes, covering indexes, combined indexes, prefix indexes, unique indexes, etc. Without special instructions, the B-tree structure is used by default. Organized (multi-way search tree, not necessarily binary) index.
Advantages:
Yes Improve the efficiency of data retrieval and reduce the IO cost of the database, similar to the catalog of a book.
Sort data through index columns, reducing the cost of data sorting and reducing CPU consumption.
Disadvantages:
##The index will occupy disk space
Although indexes will improve query efficiency, they will reduce the efficiency of updating tables. For example, every time a table is added, deleted, or modified, MySQL must not only save the data, but also save or update the corresponding index file.
leftmost prefix matching principle (leftmost matching principle). Generally, combined indexes are used instead of multiple single-column indexes when conditions permit.
Obviously this is not suitable for use as a database index that often requires searches and range searches.
Binary search treeBinary tree, I think everyone will have a picture in their mind.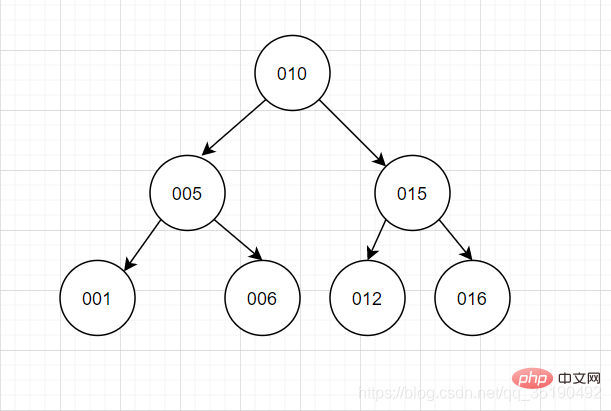
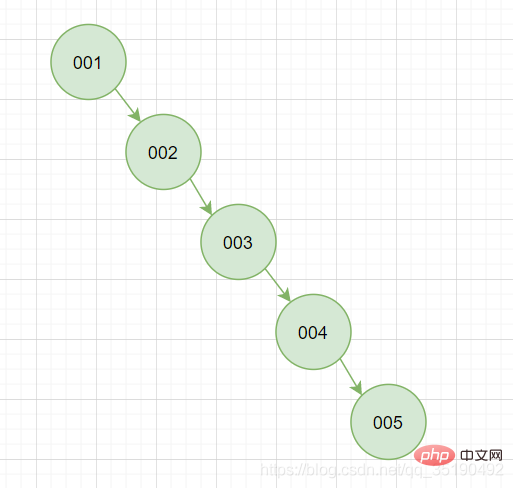
#Obviously this situation is unstable and we will choose a design that will inevitably avoid this situation
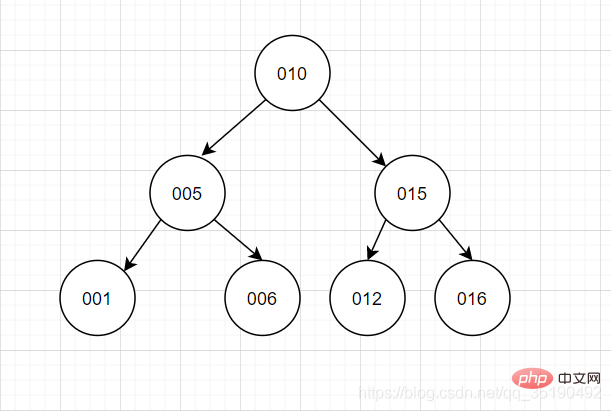
Balanced Binary TreeThe balanced binary tree adopts dichotomy thinking. In addition to the characteristics of the binary tree, the most important feature of the balanced binary search tree is that the levels of the left and right subtrees of the tree differ by at most 1. When inserting and deleting data, the left-turn/right-turn operation is used to maintain the balance of the binary tree. The left subtree will not be very tall and the right subtree will be short.The performance of using the balanced binary search tree query is close to the binary search method, and the time complexity is O(log2n). Querying id=6 requires only two IOs.
Looking at this feature, you may think this is very good and can achieve the ideal situation of a binary tree. However, there are still some problems:
Time complexity is related to tree height. How many times the tree needs to be retrieved depends on how high it is. The reading of each node corresponds to a disk IO operation. The height of the tree is equal to the number of disk IO operations each time data is queried. Each disk seek time is 10ms. When the amount of table data is large, the query performance will be very poor. (For a data volume of 1 million, log2n is approximately equal to 20 disk IO times, and the time is 20*10=0.2s)
The balanced binary tree does not support range query for fast search, and range query needs to be performed from The root node is traversed multiple times, and the query efficiency is not high.
MySQL data is stored in disk files. When querying and processing data, you need to load the data from the disk into the memory first. , disk IO operations are very time-consuming, so the focus of our optimization is to minimize disk IO operations. Accessing each node of the binary tree will cause an IO. If you want to reduce disk IO operations, you need to reduce the height of the tree as much as possible. So how to reduce the height of the tree?
If the key is bigint=8 bytes, each node has two pointers, each pointer is 4 bytes, and one node occupies 16 bytes of space (8 4*2=16).
Because the InnoDB storage engine of MySQL will read the amount of data of one page (default page is 16K) in one IO, while the effective amount of data in one IO of a binary tree is only 16 bytes, the space utilization is extremely low. In order to maximize the use of one IO space, a simple idea is to store multiple elements in each node and store as much data as possible in each node. Each node can store 1000 indexes (16k/16=1000), thus transforming the binary tree into a multi-fork tree. By increasing the fork tree of the tree, the tree is changed from tall and thin to short and fat. To construct 1 million pieces of data, the height of the tree only needs 2 levels (1000*1000=1 million), which means that only 2 disk IOs are needed to query the data. The number of disk IOs is reduced, and the efficiency of querying data is improved.
We call this data structure a B-tree. The B-tree is a multi-fork balanced search tree. The main features are as shown below:
The nodes of the B-tree are stored in With multiple elements, each internal node has multiple forks.
The elements in the node contain key values and data. The key values in the node are arranged from large to small. In other words, data is stored on all nodes.
Elements in the parent node will not appear in the child nodes.
All leaf nodes are located on the same layer, leaf nodes have the same depth, and there are no pointer connections between leaf nodes.
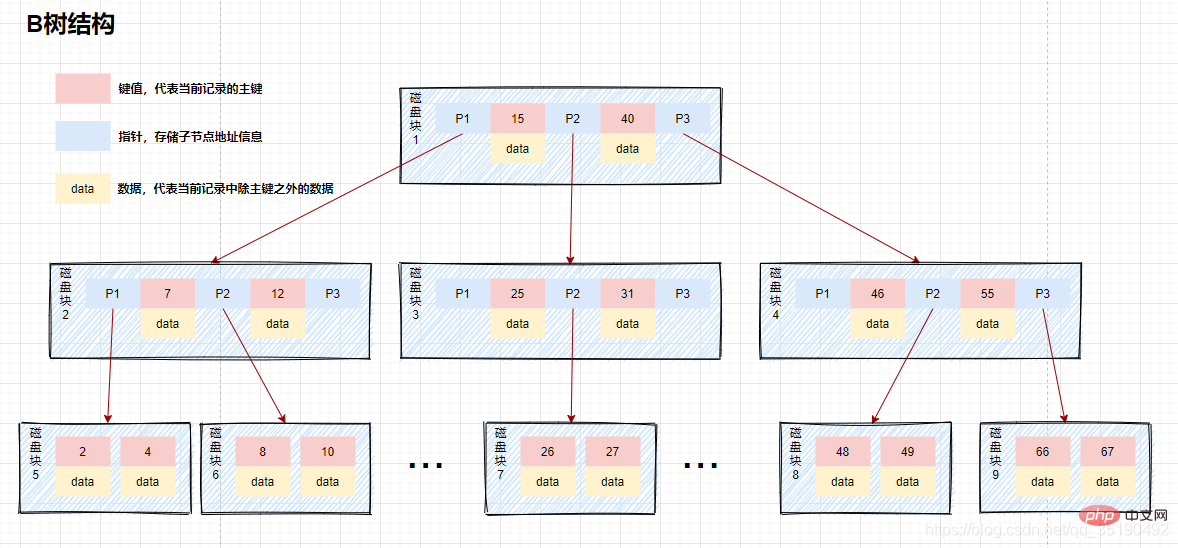
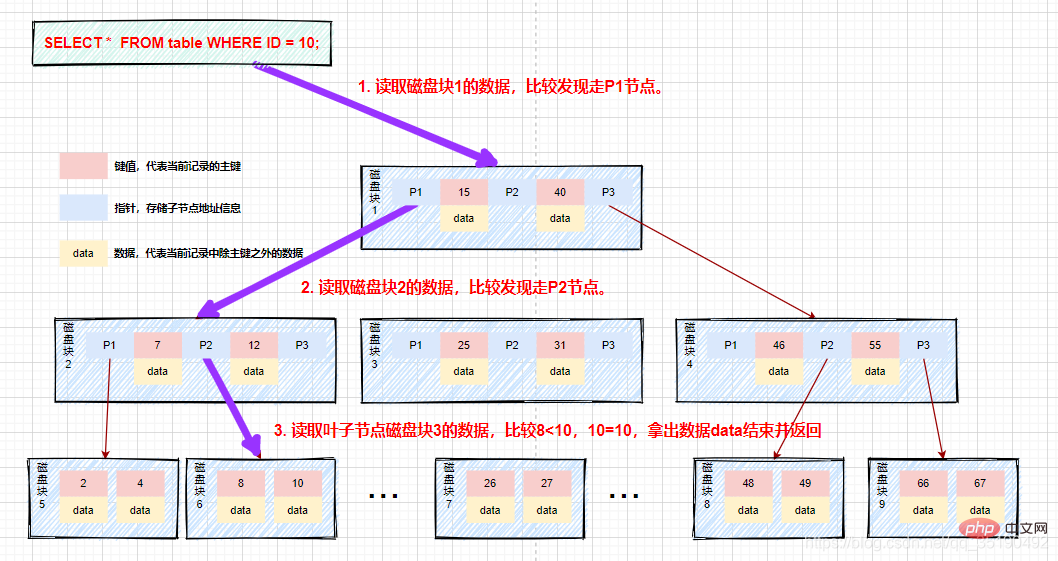
For example, when querying data in the b-tree:
If we query the value equal to 10 data. Query path disk block 1->disk block 2->disk block 5.
First disk IO: Load disk block 1 into memory, traverse and compare in memory from the beginning, 10
The second disk IO: load disk block 2 into the memory, traverse and compare in the memory from the beginning, 7
The third disk IO: load disk block 5 into the memory, traverse and compare in the memory from the beginning, 10=10, find 10, take out the data, if the row record stored in the data is taken out, the query ends . If the disk address is stored, the data needs to be fetched from the disk according to the disk address, and the query is terminated.
Compared with the binary balanced search tree, during the entire search process, although the number of data comparisons is not significantly reduced, the number of disk IOs will be greatly reduced. At the same time, since our comparison is performed in memory, the comparison time is negligible. The height of the B-tree is generally 2 to 3 layers, which can meet most application scenarios, so using the B-tree to build an index can greatly improve the query efficiency.
The process is as shown:
When you see this, you must think that B-tree is ideal, but the seniors will tell you that it still exists and can be optimized. Place:
B-tree does not support fast search for range queries. Think about this situation. If we want to find data between 10 and 35, we will find 15. After that, you need to go back to the root node and traverse the search again. You need to traverse multiple times from the root node, and the query efficiency needs to be improved.
If data stores row records, the size of the rows will increase as the number of columns increases, and the space occupied will increase. At this time, the amount of data that can be stored in a page will decrease, the tree will become taller, and the number of disk IOs will increase.
B tree, as an upgraded version of B tree, is based on B tree. MySQL continues to transform on the basis of B tree. Build the index using a B-tree. The main difference between B-tree and B-tree is the question of whether non-leaf nodes store data
- B-tree: Both non-leaf nodes and leaf nodes store data.
- B tree: Only leaf nodes store data, and non-leaf nodes store key values. Leaf nodes are connected using bidirectional pointers, and the lowest leaf nodes form a bidirectional ordered linked list.
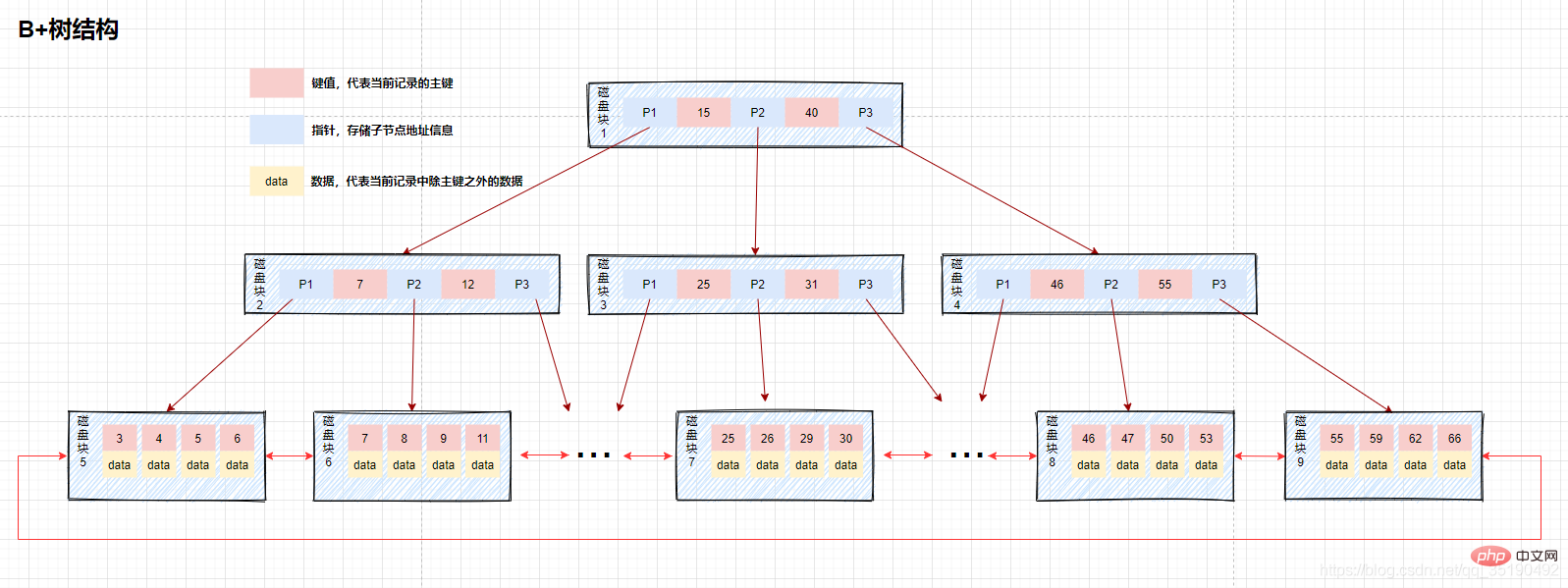
B The lowest leaf node of the tree contains all index items. As can be seen from the figure, when the B-tree searches for data, since the data is stored on the leaf nodes at the bottom, each search needs to retrieve the leaf nodes to query the data. Therefore, when data needs to be queried, the IO of each disk is directly related to the height of the tree. But on the other hand, since the data is placed in the leaf nodes, the number of indexes stored in the disk block lock of the index is It will increase with this, so compared to the B tree, the height of the B tree is theoretically shorter than the B tree. There are also cases where the index covers the query. The data in the index meets all the data required by the current query statement. In this case, you only need to find the index to return immediately, without retrieving the lowest leaf node.
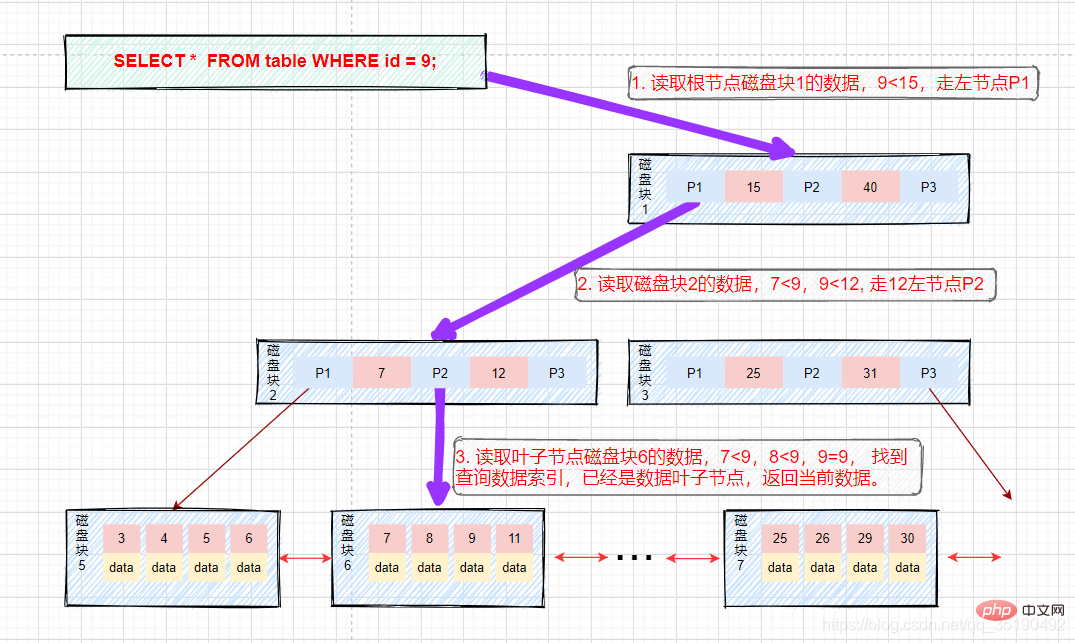
For example:
- Equal value query:
If our query value is equal to 9 The data. Query path disk block 1->disk block 2->disk block 6.
First disk IO: Load disk block 1 into memory, traverse and compare in memory from the beginning, 9
The second disk IO: load disk block 2 into memory, traverse and compare in memory from the beginning, 7
The third disk IO: load disk block 6 into the memory, traverse and compare in the memory from the beginning, find 9 in the third index, take out the data, if the data is stored Row the record, take out the data, and the query ends. If the disk address is stored, the data needs to be fetched from the disk according to the disk address, and the query is terminated. (What needs to be distinguished here is that Data in InnoDB stores row data, while MyIsam stores disk addresses.)
The process is as shown in the figure:
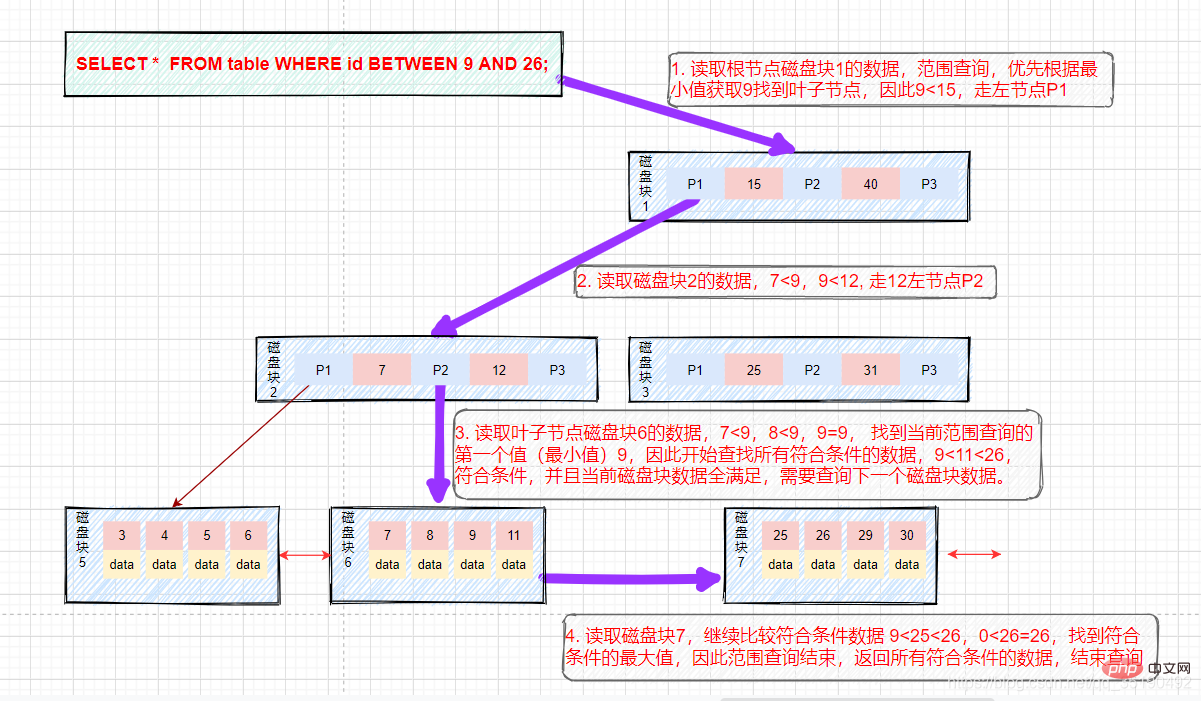
- Range query:
If we want to find data between 9 and 26. The search path is disk block 1->disk block 2->disk block 6->disk block 7.
First search for data with a value equal to 9, and cache the data with a value equal to 9 to the result set. This step is the same as the previous equivalent query process, and three disk IOs occur.
After finding 15, the underlying leaf node is an ordered list. We start from disk block 6 and key value 9 and traverse backwards to filter all data that meets the filtering conditions.
The fourth disk IO: Address and locate disk block 7 according to the successor pointer of disk 6, load disk 7 into the memory, traverse and compare in the memory from the beginning, 9< ;25
The primary key is unique (there will be no
You can see that the B tree can ensure fast search for equal value and range queries. MySQL’s index uses B Tree data structure.
After introducing the index data structure, it must be brought into Mysql to see the real usage scenario, so here we analyze the two storage methods of Mysql Index implementation of the engine: MyISAM Index and InnoDB Index
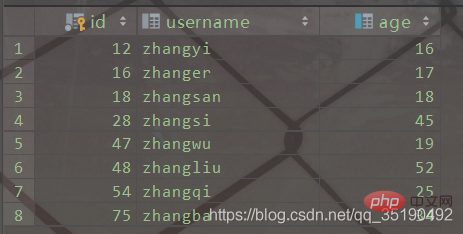
Take a simple user table as an example. There are two indexes in the user table, the id column is the primary key index, and the age column is the ordinary index
CREATE TABLE `user`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = MyISAM AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
The data files and index files of MyISAM are stored separately. When MyISAM uses B-tree to build an index tree, the key value stored in the leaf node is the value of the index column, and the data is the disk address of the row where the index is located.

The index of table user is stored in the index file user.MYI, and the data file is stored in the data file user.MYD in.
Briefly analyze the disk IO situation during query:
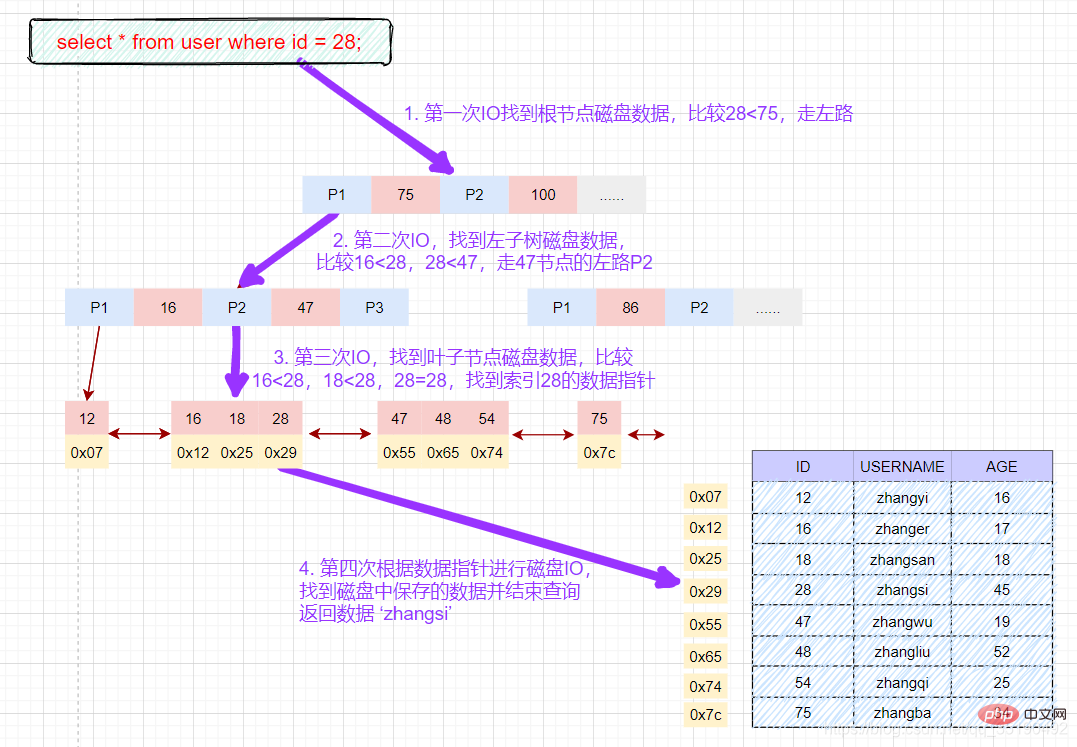
Query data based on primary key equivalent:
select * from user where id = 28;
磁盘IO次数:3次索引检索+记录数据检索。
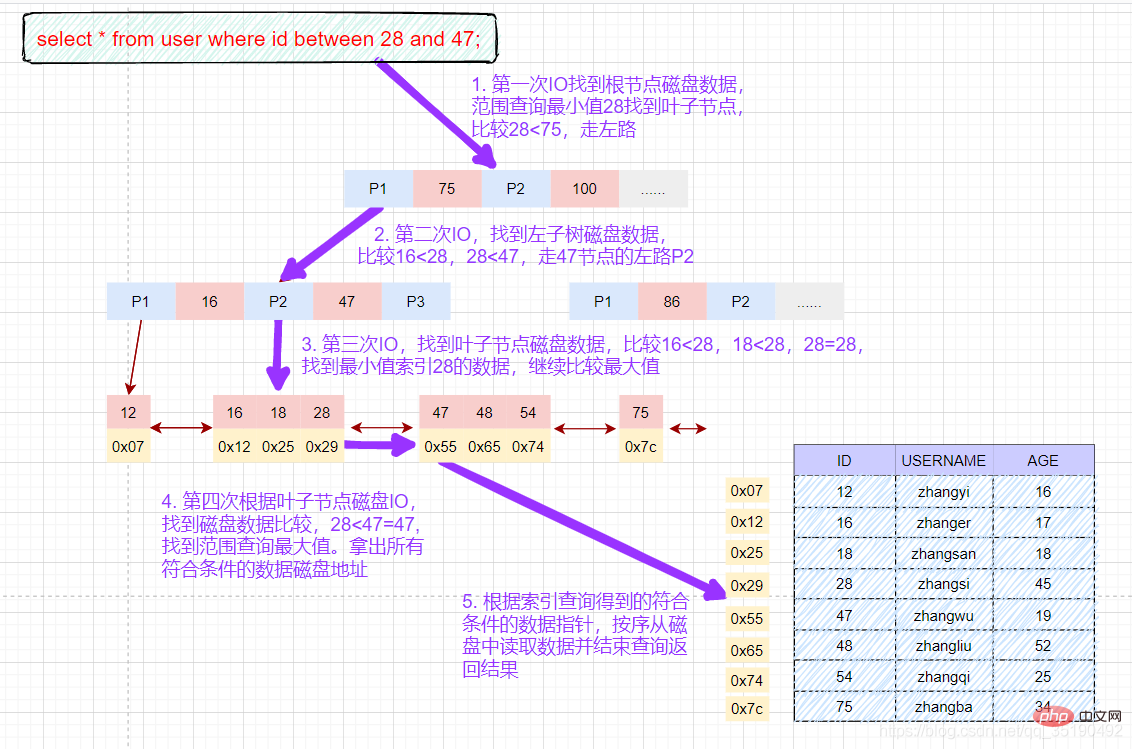
根据主键范围查询数据:
select * from user where id between 28 and 47;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28
将左子树节点加载到内存中,比较16
检索到叶节点,将节点加载到内存中遍历比较16
根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
我们的查询语句时范围查找,需要向后遍历底层叶子链表,直至到达最后一个不满足筛选条件。
向后遍历底层叶子链表,将下一个节点加载到内存中,遍历比较,28
最后得到两条符合筛选条件,将查询结果集返给客户端。
磁盘IO次数:4次索引检索+记录数据检索。
**备注:**以上分析仅供参考,MyISAM在查询时,会将索引节点缓存在MySQL缓存中,而数据缓存依赖于操作系统自身的缓存,所以并不是每次都是走的磁盘,这里只是为了分析索引的使用过程。
在 MyISAM 中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点的数据存储的都是行记录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。
查询数据时,由于辅助索引的键值不唯一,可能存在多个拥有相同的记录,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据。
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下:
- 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值都。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。
CREATE TABLE `user_innodb`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = InnoDB;
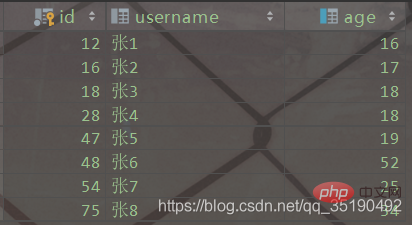
InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
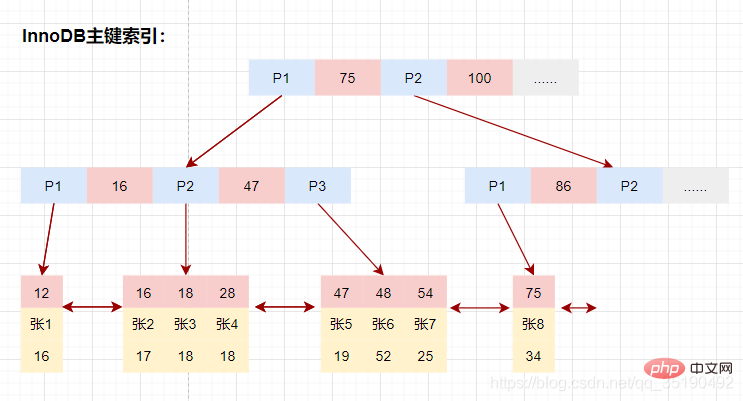
等值查询数据:
select * from user_innodb where id = 28;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28
将左子树节点加载到内存中,比较16
检索到叶节点,将节点加载到内存中遍历,比较16
磁盘IO数量:3次。
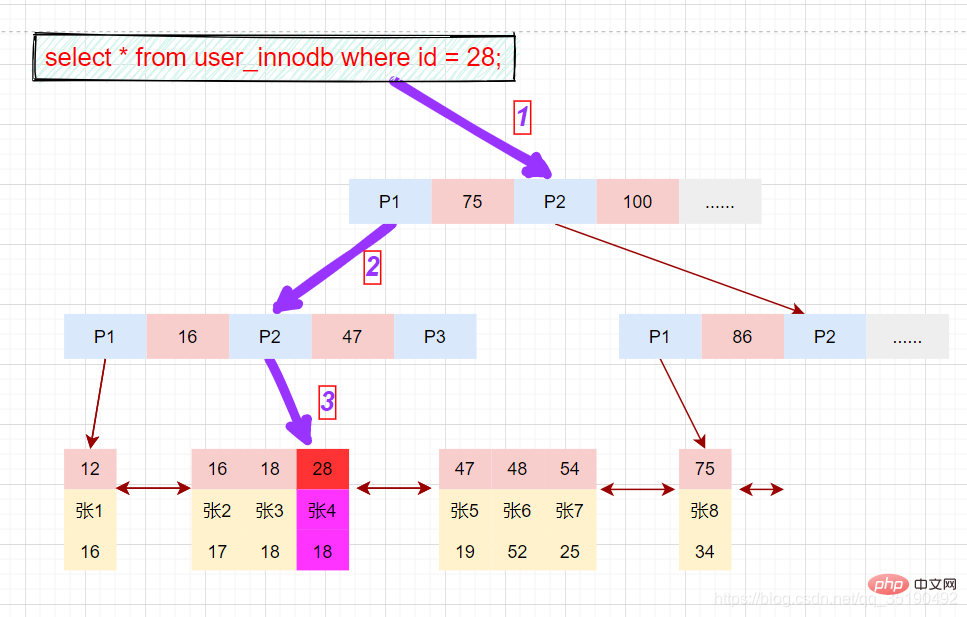
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。
以表user_innodb的age列为例,age索引的索引结果如下图。
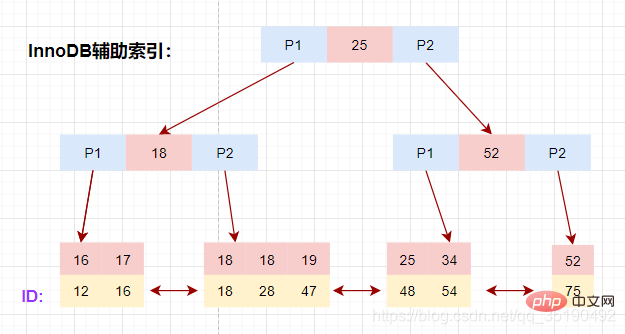
底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。
画图分析等值查询的情况:
select * from t_user_innodb where age=19;
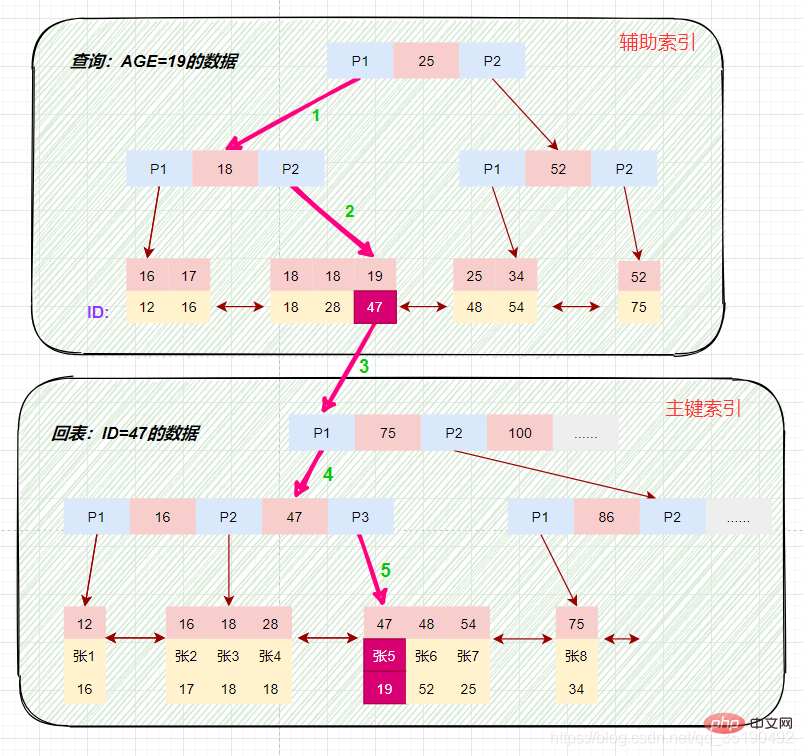
根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
磁盘IO数:辅助索引3次+获取记录回表3次
还是以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。
CREATE TABLE `abc_innodb`( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` varchar(10) DEFAULT NULL, `d` varchar(10) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_abc` (`a`, `b`, `c`)) ENGINE = InnoDB;
select * from abc_innodb order by a, b, c, id;
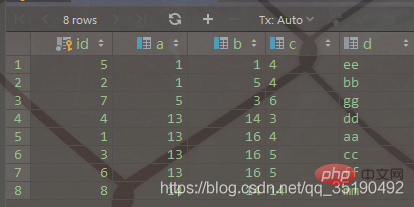
组合索引的数据结构:
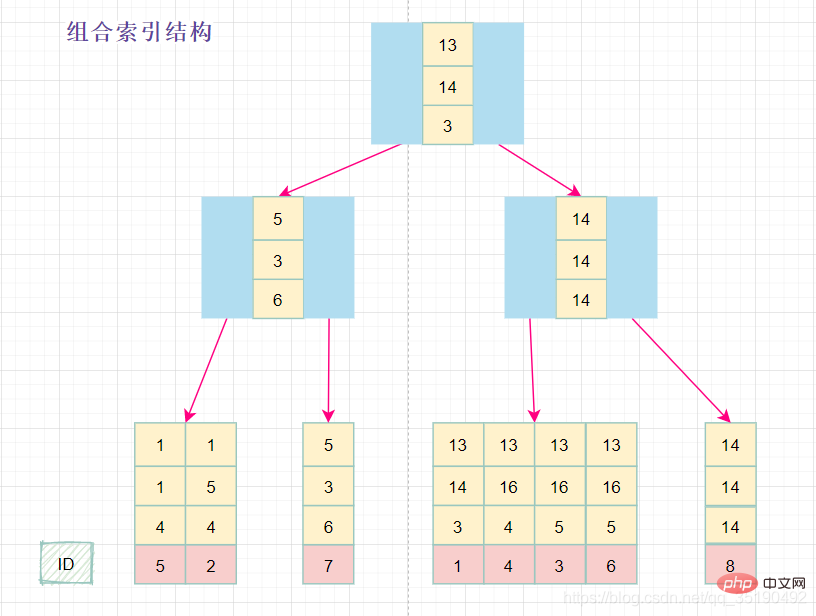
组合索引的查询过程:
select * from abc_innodb where a = 13 and b = 16 and c = 4;
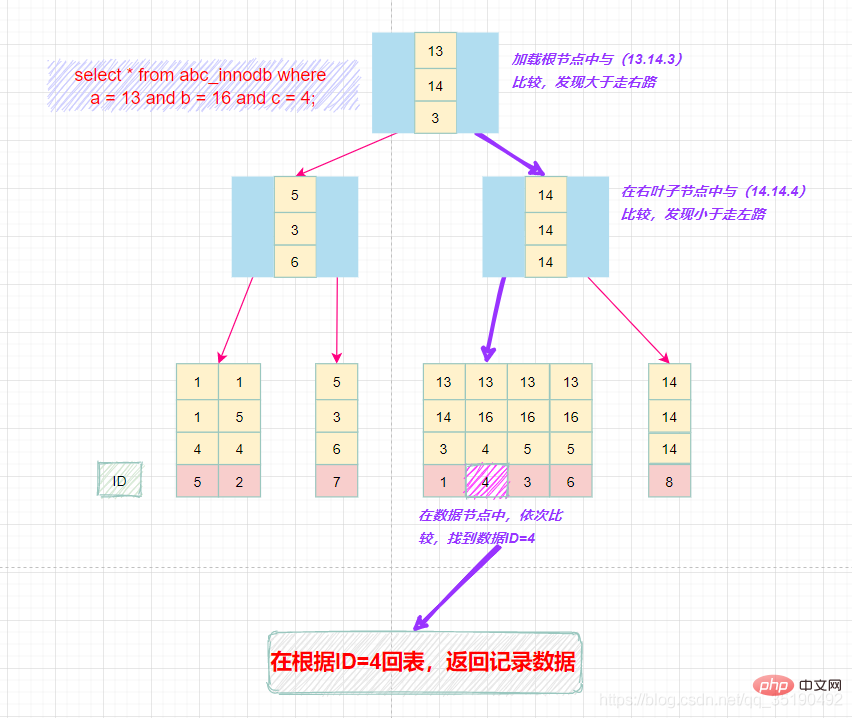
最左匹配原则:
最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。、
组合索引的最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
可以看一下执行计划:
覆盖索引的情况:

未使用到覆盖索引:

看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。比如:
在InnoDB的存储引擎中,使用辅助索引查询的时候,因为辅助索引叶子节点保存的数据不是当前记录的数据而是当前记录的主键索引,索引如果需要获取当前记录完整数据就必然需要根据主键值从主键索引继续查询。这个过程我们成位回表。想想回表必然是会消耗性能影响性能。那如何避免呢?
使用索引覆盖,举个例子:现有User表(id(PK),name(key),sex,address,hobby…)
If in a scenario, select id,name,sex from user where name ='zhangsan';This statement is frequently used in business, while other fields in the user table are used much less frequently. In this case, if we do not use a single index when establishing the index of the name field, but use a joint index (name, sex), then if we execute this query statement, will the result be obtained based on the auxiliary index? You can get the complete data of the current statement. This can effectively avoid returning to the table to obtain sex data.
Here is a typical optimization strategy using covering indexes to reduce table returns.
Joint index When creating an index, try to determine whether a joint index can be used on multiple single-column indexes. The use of joint indexes not only saves space, but also makes it easier to use index coverage. Just imagine, the more fields indexed, the easier it will be to satisfy the data returned by the query. For example, the joint index (a_b_c) is equivalent to having three indexes: a, a_b, a_b_c. Does this save space? Of course, the space saved is not three times that of the three indexes (a, a_b, a_b_c). Because the data in the index tree has not changed, but the data in the index data field is indeed saved.
Principles of creating a joint index When creating a joint index, frequently used columns and columns with high differentiation should be placed in front. Frequent use represents high index utilization and differentiation. High degree means large filtering granularity. These are optimization scenarios that need to be considered when creating an index. Fields that are often returned as queries can also be added to the joint index. If a field is added to the joint index and coverage is used, Index, then I recommend using a joint index in this case.
Use of joint index
The current index contains columns that are frequently used as return fields. At this time, you can consider whether the current column can be added to the existing index so that the query statement can use the covering index.
[Recommended: mysql video tutorial]
The above is the detailed content of Understand all the knowledge points of MySQL index in one article (recommended to collect). For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



