


Recommended (free): redis introductory tutorial
1. Internet Big opportunity in the context of the times, why use NoSQL
1.1 The good old days of stand-alone MySQL
In the 1990s, the number of visits to a website was generally not large. This can be easily handled with a single database.
At that time, most of them were static web pages, and there were not many dynamic interactive websites. 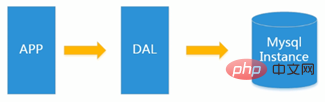
DAL dal is the English abbreviation of data access layer, which is the data access layer (Data Access Layer)
Under the above architecture, let’s take a look at what are the bottlenecks of data storage?
1. When the total size of the data cannot fit in one machine
2. When the data index (B Tree) cannot fit in the memory of one machine
3. The amount of access (mixed reading and writing) cannot be tolerated by one instance
If 1 or 3 of the above are met, evolve...
1.2.Memcached (cache) MySQL vertical split
Later, as the number of visits increased, almost Most websites using the MySQL architecture have begun to have performance problems on the database. Web programs no longer only focus on functions, but also pursue performance. Programmers began to use caching technology extensively to relieve the pressure on the database and optimize the structure and index of the database. At first, it was more popular to use file caching to relieve database pressure. However, when the number of visits continues to increase, multiple web machines cannot be shared through file caching. A large number of small file caching also brings relatively high IO pressure. . At this time, Memcached has naturally become a very fashionable technical product. 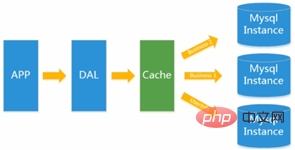 It is equivalent to the previous dao layer directly accessing the database, and now a cache layer is inserted in the middle. Frequent database access causes performance degradation. We put some of the content in the cache to reduce the pressure.
It is equivalent to the previous dao layer directly accessing the database, and now a cache layer is inserted in the middle. Frequent database access causes performance degradation. We put some of the content in the cache to reduce the pressure.
1.3. Mysql master-slave read-write separation
Due to the increased write pressure on the database,Memcached can only relieve the read pressure on the database. The concentration of reading and writing on one database makes the database overwhelmed. Most websites have begun to use master-slave replication technology to achieve separation of reading and writing to improve reading and writing performance and the scalability of reading databases. Mysql’s master-slave mode has become the standard configuration of the website at this time. 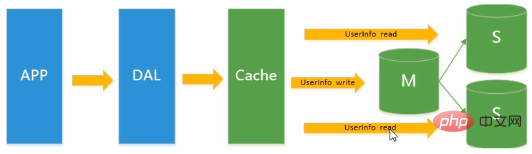 Explanation: There is a record update in the master database. In order to ensure the integrity of the data, it needs to be copied to the slave database. Read and write separation: Master/slaver. We can place write operations in the master library and read operations in the slave library.
Explanation: There is a record update in the master database. In order to ensure the integrity of the data, it needs to be copied to the slave database. Read and write separation: Master/slaver. We can place write operations in the master library and read operations in the slave library.
1.4. Split the mysql cluster horizontally into tables and databases
Based on Memcached’s cache, MySQL’s master-slave replication, and read-write separation,At this time, the writing pressure of the MySQL main database began to appear bottlenecks, and the amount of data continued to surge. Because MyISAM uses table locks, serious lock problems will occur under high concurrency, a large number of High-concurrency MySQL applications began to use the InnoDB engine instead of MyISAM. At the same time,
became popular to use sub-tables and sub-databases to alleviate write pressure and expansion issues of data growth. At this time, sub-table and sub-database have become a popular technology, a popular interview question and a hot technical issue discussed in the industry. At this time, MySQL launched table partitions that were not yet stable, which also brought hope to companies with average technical strength. Although MySQL has launched the MySQL Cluster cluster, its performance cannot meet the requirements of the Internet very well, but it only provides a very large guarantee in terms of high reliability. 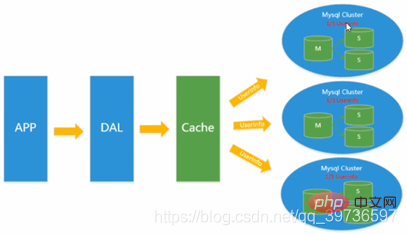 Table lock and row lock?
Table lock and row lock?
Sub-library and sub-table 1-3000 enter the No. 1 database. 3001-6000 go to warehouse 2. Wait
1.5. MySQL scalability bottleneck
MySQL database also often stores some large text fields, resulting in very large database tables. When doing database recovery This causes it to be very slow and difficult to restore the database quickly. For example, 10 million 4KB text is close to 40GB in size. If this data can be omitted from MySQL, MySQL will become very small. Relational databases are powerful, but they cannot cope with all application scenarios. MySQL has poor scalability (requires complex technology to implement), high IO pressure under big data, and difficulty in changing the table structure. These are the problems faced by developers currently using MySOL.1.6. What does it look like today? ?
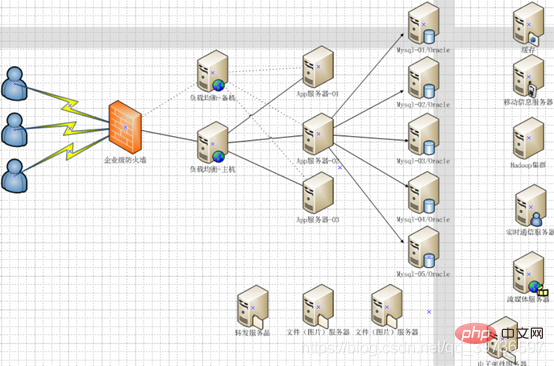 Firewall-nginx-Tomcat Cluster
Firewall-nginx-Tomcat Cluster
1.7.Why Use NoSQL
Today we can easily access and capture data through third-party platforms (such as Google, Facebook, etc.). Users' personal information, social networks, geographical locations, user-generated data and user operation logs have increased exponentially. If we want to mine these user data, then SQL databases are no longer suitable for these applications. However, the development of NoSQL databases can handle these large data very well. 
2. What is
NoSQL (NoSQL = Not Only SQL), which means "not just SQL", generally Refers to non-relational database. With the rise of Internet web2.0 websites, traditional relational databases have become unable to cope with web2.0 websites, especially ultra-large-scale and highly concurrent SNS type web2.0 purely dynamic websites, exposing many insurmountable problems. Non-relational databases have developed very rapidly due to their own characteristics. NoSQL databases were created to solve the challenges brought by large-scale data collections and multiple data types, especially big data application problems, including the storage of ultra-large-scale data.
(Google or Facebook, for example, collect trillions of bits of data on their users every day). These types of data stores do not require a fixed schema and can be scaled out without redundant operations.
3. What can be done
Easy to expand
There are many types of NoSQL databases, but one common feature is to remove Relational characteristics of relational databases. There is no relationship between data, so it is very easy to expand. It also invisibly brings scalability capabilities at the architectural level.
High performance for large data volumes
NoSQL databases have very high read and write performance, especially under large data volumes, they also perform well.
This is due to its non-relationship and simple database structure.
Generally, MySQL uses Query Cache. The cache becomes invalid every time the table is updated. It is a large-grained cache. In applications with frequent interactions in web2.0, the cache performance is not high.
The Cache of NoSQL is record-level and a fine-grained Cache, so NoSQL has much higher performance at this level.
Diverse and flexible data models
NoSQL does not need to create fields for the data to be stored in advance, and can store customized data formats at any time.
In a relational database, adding and deleting fields is a very troublesome thing. If it is a table with a very large amount of data, adding fields is simply a nightmare.
Traditional RDBMS VS NOSQL
RDBMS
Highly organized structured data
Structured Query Language (SQL)
Both data and relationships are stored In separate tables
Data manipulation language, data definition language
Strict consistency
Basic transactions
NoSQL
Represents more than just SQL
No declarative queries Language
No predefined schema
Key-value stores, column stores, document stores, graph databases
Eventual consistency, not ACID properties
Unstructured and unpredictable data:
CAP Theorem
High performance, high availability and scalability
4. What are the NoSQL
Redis (data types and caches, Excellent in all aspects)
Memcached (cache)
MongDB (most similar to a relational database)
5. How to play
KV
Cache
Persistence
Talk about your understanding of Redis, just say KV-CACHE-PERSISITENCE
3V 3 High
Big Data The 3V of the era:
Massive Volume
Diverse Variety
Real-time Velocity
Description of some problems on the system, Taobao Double Eleven massive data. A Weibo, text field, video field, background field, etc. diversification. 12306 has high real-time requirements. Absolute real-time is not possible
Three high Internet requirements:
High concurrency
Highly inclusive
High performance
The system must support high concurrency, such as 12306. Four ways to obtain thread.
Scalability, horizontally and vertically. Horizontally, if one machine is not enough, add more machines.
High performance requirements
For more related learning, please visit the redis column. .
The above is the detailed content of Introduction to redis learning NoSQL. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



