


推荐教程:《PHP7》
先看如下示例代码:
$a = 'foo'; $b = 'bar'; $c = "I like $a and $b";
在 PHP 5.6 中执行代码,得到的 opcode 输出如下图: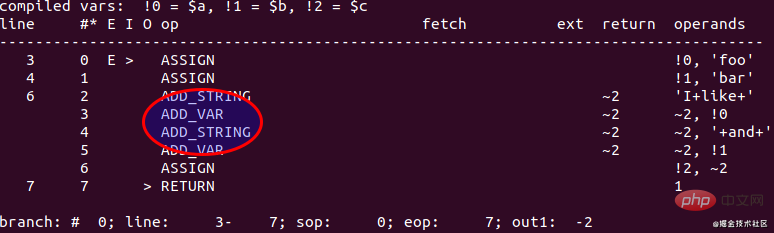
具体的执行过程:
在 PHP 7 中执行代码,得到的 opcode 输出如下入:
PHP 7 中对字符串的处理过程相对简单,首先创建一个堆栈 stack,然后将要连接的字符串片段存入栈空间,最后只需要分配一次内存空间,然后将结果从栈中移动到所分配的内存空间中。相较于 PHP 5,PHP 7 在处理过程中避免了反复申请内存的过程。而 PHP 7 在字符串处理方面性能的提升得益于数据结构 rope 的使用。
Rope 是一棵二叉树,其中每个叶子节点存储的是字符串的子串,每个非叶子节点存储的是位于该节点左侧的每个叶子节点所存储的子串中所包含的字符总数(方便了根据索引查找指定字符)。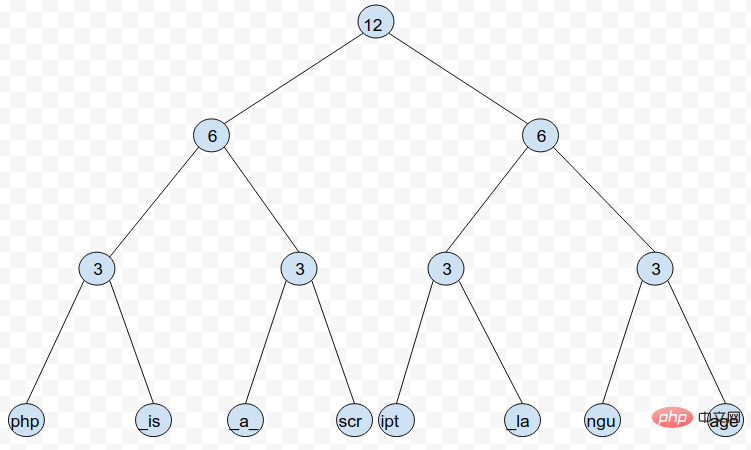
优势:
Due to the different structure of binary trees Compared with character arrays, it is more complicated, so the performance is worse when operating strings with smaller sizes.
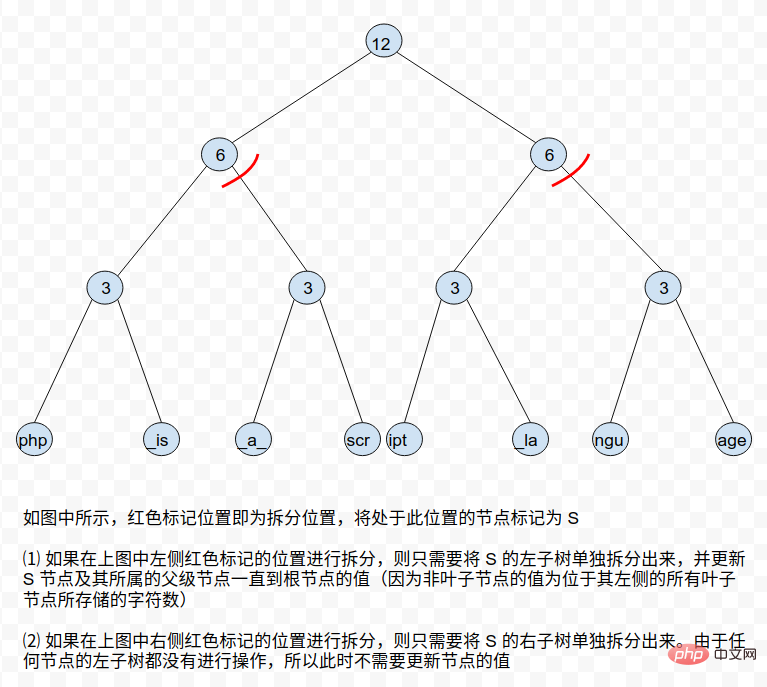
⓶ split When splitting a Rope tree, you will encounter two situations: the split position is exactly at the end of a node or the split position is in the middle of a leaf node. For the second case, we can split the corresponding leaf nodes to transform into the first case. As for the first situation, it can be divided into two situations according to the location of the node: À ˆ a. The branch where the node is located on the far left or the far rightThe operation of concat is relatively simple. You only need to join two Rope trees into a new Rope tree.
##  #
#
class Node:
def __init__(self, data):
self.parent = None
self.left = None
self.right = None
self.data = data
self.weight = 0
def __repr__(self):
return str(self.__dict__)
def __str__(self):
return str(self.__dict__)
class Rope:
# 每个叶子节点最多存储 5 个字符,包括空字符在内
LEAF_DATA_LEN = 5
def __init__(self):
self.root = None
def create_rope(self, parent, data, left_index, right_index):
"""
创建 rope 数据结构
:param parent: 父节点(根节点的父节点为空)
:param data: 用于创建 rope 数据结构的原始数据,这里只接受 list 和 str 两种类型
:param left_index: 起始位置索引
:param right_index: 结束位置索引
:return: Node
"""
if isinstance(data, str):
data = list(data)
elif not isinstance(data, list):
return
if right_index - left_index > self.LEAF_DATA_LEN:
node = Node("")
node.parent = parent
middle_index = (left_index + right_index) // 2
node.weight = middle_index - left_index
node.left = self.create_rope(node, data, left_index, middle_index)
node.right = self.create_rope(node, data, middle_index, right_index)
else:
node = Node(data[left_index: right_index])
node.parent = parent
node.weight = right_index - left_index
if node.parent is None:
self.root = node
return node
@staticmethod
def calc_weight(node):
"""
计算节点 weight 值
:param node:
:return:
"""
if node is None:
return 0
init_weight = node.weight
while node.right is not None:
node = node.right
init_weight += node.weight
return init_weight
def concat_rope(self, data1, data2):
"""
字符串连接
:param data1:
:param data2:
:return:
"""
r1 = Rope()
r1.create_rope(None, data1, 0, len(data1))
r2 = Rope()
r2.create_rope(None, data2, 0, len(data2))
node = Node("")
node.left = r1.root
node.right = r2.root
r1.root.parent = node
r2.root.parent = node
node.weight = self.calc_weight(r1)
self.root = node
def split_rope(self, data, index):
"""
字符串拆分
:param data: 要拆分的字符串
:param index: 拆分的位置(字符串索引从 0 开始计算)
:return: Rope
"""
if index < 0 or index > len(data) - 1:
return
node = self.create_rope(None, data, 0, len(data))
original_index = index
if index == self.root.weight - 1:
# 在根节点拆分
rope_left = node.left
rope_left.parent = None
rope_right = node.right
rope_right.parent = None
return rope_left, rope_right
elif index < self.root.weight - 1:
while index < node.weight - 1 and node.data == "":
node = node.left
else:
while index > node.weight - 1 and node.data == "":
index -= node.weight
node = node.right
if node.data != "":
# index 落在了最左侧和最右侧的两个叶子节点
if original_index < self.root.weight - 1:
# index 落在了最左侧的叶子节点
rope_left = self.create_rope(None, node.data[0:index + 1], 0, index + 1)
rope_right = self.root
# 更新 rope_right 的 weight
node.data = node.data[index + 1:]
while node is not None:
node.weight -= (index + 1)
node = node.parent
else:
# index 落在了最右侧的叶子节点
rope_left = self.root
rope_right = self.create_rope(None, node.data[index + 1:], 0, len(node.data[index + 1:]))
node.data = node.data[0:index + 1]
elif index == node.weight - 1:
# index 正好落在了节点的末尾
if original_index < self.root.weight:
# index 落在了最左侧分支中的非叶子节点的末尾
weight_sub = node.weight
rope_left = node.left
rope_left.parent = None
node.left = None
rope_right = self.root
# 更新节点 weight
while node is not None:
node.weight -= weight_sub
node = node.parent
else:
# index 落在了最右侧分支中的非叶子节点的末尾
rope_left = self.root
rope_right = node.right
rope_right.parent = None
node.right = None
else:
stack = []
if original_index < self.root.weight:
# index 落在了左子树中的节点
index -= node.weight
rope_left = node
rope_right = self.root
node.parent.left = None
node.parent = None
node = node.right
else:
# index 落在了右子树中的节点
rope_left = self.root
stack.append(node.right)
rope_right = None
node.right = None
node = node.left
while node.data == "" and index >= 0:
if index < node.weight - 1:
stack.append(node.right)
node.right = None
node = node.left
elif index > node.weight - 1:
node = node.right
index -= node.weight
else:
stack.append(node.right)
node.right = None
break
if node.data != "":
# 需要拆分叶子节点
new_node = Node(node.data[index + 1:])
new_node.weight = node.weight - index - 1
stack.append(new_node)
node.data = node.data[0:index + 1]
# 更新节点的 weight 信息
while node is not None:
if node.data != "":
node.weight = len(node.data)
else:
node.weight = self.calc_weight(node.left)
node = node.parent
# 组装 rope_right并更新节点的 weight 值
left_node = None
while len(stack) > 0:
root_node = Node("")
if left_node is None:
left_node = stack.pop()
root_node = left_node
else:
root_node.left = left_node
left_node.parent = root_node
right_node = stack.pop()
root_node.right = right_node
right_node.parent = root_node
root_node.weight = self.calc_weight(root_node.left)
left_node = root_node
if rope_right is None:
# index > self.root.weight - 1
rope_right = root_node
else:
# index < self.root.weight - 1
tmp = rope_right
while tmp.left is not None:
tmp = tmp.left
tmp.left = root_node
root_node.parent = tmp
while tmp.parent is not None:
tmp.weight = self.calc_weight(tmp.left)
tmp = tmp.parent
rope_right = tmp
rope_right.weight = self.calc_weight(rope_right.left)
return rope_left, rope_right
rope = Rope()
data = "php is a script language"
index = 18
left, right = rope.split_rope(data, index)
print(left)
print(right)PHP 5 中 zval 中定义的字符串的长度为 int(有符号整型) 类型,这就导致即使是在 64 为机器上字符串的长度也不能超过 (LP64 数据模型中,int 永远只有 32 位)。
// zval 中对字符串的定义,长度为 int 类型
typedef union _zvalue_value {
long lval;
double dval;
struct {
char *val; /* C string buffer, NULL terminated */
int len; /* String length : num of ASCII chars */
} str; /* string structure */
HashTable *ht;
zend_object_value obj;
zend_ast *ast;
} zvalue_value;
// 类实例结构体中对字符串的定义,此时字符串的长度为 zend_uint 类型,相较于 int 类型,字符串长度提升了一倍
struct _zend_class_entry {
char type;
const char *name; /* C string buffer, NULL terminated */
zend_uint name_length; /* String length : num of ASCII chars */
struct _zend_class_entry *parent;
int refcount;
zend_uint ce_flags;
/*……*/
}
// hashtable 的 key 中对字符串的定义,长度为 uint 类型
typedef struct _zend_hash_key {
const char *arKey; /* C string buffer, NULL terminated */
uint nKeyLength; /* String length : num of ASCII chars */
ulong h;
} zend_hash_key;PHP 5 中很多地方都支持二进制字符串,由于字符串没有一个固定的结构体,这就导致很多地方都有对字符串的定义。同时,由于各处对字符串长度的定义不同,导致各处支持的字符串长度也不同。
在较老版本的 PHP 中,由于没有引入 interned string,同一个字符串如果在多处被使用,为了互不影响,就需要复制多份出来,这就造成了对内存空间大量消耗。
static PHP_FUNCTION(session_id)
{
char *name = NULL;
int name_len, argc = ZEND_NUM_ARGS();
if (zend_parse_parameters(argc TSRMLS_CC, "|s", &name, &name_len) == FAILURE) {
return;
}
/* …… */
if (name) {
if (PS(id)) {
efree(PS(id));
}
PS(id) = estrndup(name, name_len);
}
}以 PHP 函数 session_id 为例,该函数最终将 name 完全复制一份然后存入 PS(id)。这样,后续代码对 name 进行的任何操作都不会影响 PS(id) 中存储的值。
从 PHP 5.4 起,为了解决上述字符串复制导致内存消耗大的问题,PHP 引入了 interned string 。另外,由于 interned string 需要共享内存空间,所以在线程安全的 PHP 版本中并不被支持。
所谓 interned string,即一个字符串在一个进程中只存储一次。当一个 php-fpm 进程启动时,会申请一块 size 为 1MB 的 buffer,持久化的字符串(字符串常量、函数名、变量名、类名、方法名……)会被存储到该缓冲并添加到一个 hashtable 中。由于 PHP 处理的 request 之间是相互独立的,所以一个 request 处理完成后,其间在内存中产生的数据都会被销毁。为了在处理 request 的过程中也能使用 interned string,在 request 到来时 PHP 会记录当前 interned string buffer 的 top 位置,在该 request 请求的处理完成后,top 位置之后消耗的空间又会被恢复。

- interned string 的初始化,只会发生在 PHP 启动以及 PHP 脚本的编译阶段
- interned string 是只读的,既不能修改,也不能销毁
- 由于 interned string buffer 只有 1MB 的空间,当 1MB 的空间存满后,后续的字符串处理还会回到引入 interned string 之前的状态
interned string 的优势
由于需要操作 hashtable,interned string 的初始化和创建会比较复杂,也正因为如此,并不是所有的字符串都适合存入 interned string。
struct _zend_string {
zend_refcounted_h gc;
zend_ulong h; /* hash value */
size_t len;
char val[1];
};
typedef struct _zend_refcounted_h {
uint32_t refcount; /* reference counter 32-bit */
union {
uint32_t type_info;
} u;
} zend_refcounted_h;PHP 7 中字符串有了固定的结构 zend_string
PHP 7 中字符串的长度类型为 size_t,字符串的长度不再局限于 PHP 5 中的 ,尤其在 64 位的机器上,字符串的长度取决于平台支持的最大长度。
PHP 7 中字符串内容的存储不再像之前使用 char * ,而是使用了 struct hack ,使得字符串内容和 zend_string 一起存储在一块连续的内存空间。同时,zend_string 还内嵌了字符串的 hash 值,这样,对于一个指定的字符串只需要进行一次 hash 计算。
PHP 7 中字符串引入了引用计数,这样,只要字符串还在被使用,就不用担心会被销毁。
static PHP_FUNCTION(session_id)
{
zend_string *name = NULL;
int argc = ZEND_NUM_ARGS();
/* …… */
if (name) {
if (PS(id)) {
zend_string_release(PS(id));
}
PS(id) = zend_string_copy(name);
}
}
static zend_always_inline zend_string *zend_string_copy(zend_string *s)
{
if (!ZSTR_IS_INTERNED(s)) {
GC_REFCOUNT(s)++;
}
return s;
}
static zend_always_inline void zend_string_release(zend_string *s)
{
if (!ZSTR_IS_INTERNED(s)) {
if (--GC_REFCOUNT(s) == 0) {
pefree(s, GC_FLAGS(s) & IS_STR_PERSISTENT);
}
}
}仍以函数 session_id 为例,设置 session_id 时不再需要将 name 完全复制,而只是将 name 的引用计数加 1。在删除字符串时也是同样,将字符串的引用计数减 1,只有引用计数为 0 时才会真正销毁字符串。
PHP 7 中的 interned string 不再需要单独申请 interned string buffer 来存储,而是在 zend_string 的 gc 中将 type_info 标记为 IS_STR_INTERNED。这样,在销毁字符串时,zend_string_release 会检查字符串是否为 interned string,如果是则不会进行任何操作。
The above is the detailed content of About the optimization of string processing logic in PHP7!. For more information, please follow other related articles on the PHP Chinese website!
 How to check for plagiarism on CNKI Detailed steps for checking for plagiarism on CNKI
How to check for plagiarism on CNKI Detailed steps for checking for plagiarism on CNKI
 How to open php file
How to open php file
 Check friends' online status on TikTok
Check friends' online status on TikTok
 NTSD command usage
NTSD command usage
 How to solve the problem that mysql link reports 10060
How to solve the problem that mysql link reports 10060
 WeChat restore chat history
WeChat restore chat history
 The difference between anchoring and aiming
The difference between anchoring and aiming
 What is the difference between Douyin and Douyin Express Edition?
What is the difference between Douyin and Douyin Express Edition?









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



