


This article mainly introduces Python's method of finding the longest non-repeating substring for a given string, involving Python's traversal, sorting, calculation and other related operation skills for strings. Friends who need it can refer to it
The example in this article describes Python's method of finding the longest non-repeating substring for a given string. Share it with everyone for your reference, the details are as follows:
Question:
Given a string, find the longest repeating subsequence in it , if the string is composed of a single character, such as "aaaaaaaaaaaaa", then the output that meets the requirements is a
Thinking:
There are two ideas here The first thing I can think of is
(1) Traverse the string from the beginning, set the flag bit, and when you find that it coincides with the previous flag bit in the process of going back, go back and check the new substring. Whether the string is the same as the previous string or the substring of the previous string, if it is the same, the substring is recorded and the count is increased by 1 until the processing is completed
(2) Use the sliding window slicing mechanism to generate all slice connections For statistics and processing, the function of double sorting is mainly used.
This article uses the second method. The following is the specific implementation:
#!usr/bin/env python
#encoding:utf-8
'''''
__Author__:沂水寒城
功能:给定一个字符串,寻找最长重复子串
'''
from collections import Counter
def slice_window(one_str,w=1):
'''''
滑窗函数
'''
res_list=[]
for i in range(0,len(one_str)-w+1):
res_list.append(one_str[i:i+w])
return res_list
def main_func(one_str):
'''''
主函数
'''
all_sub=[]
for i in range(1,len(one_str)):
all_sub+=slice_window(one_str,i)
res_dict={}
#print Counter(all_sub)
threshold=Counter(all_sub).most_common(1)[0][1]
slice_w=Counter(all_sub).most_common(1)[0][0]
for one in all_sub:
if one in res_dict:
res_dict[one]+=1
else:
res_dict[one]=1
sorted_list=sorted(res_dict.items(), key=lambda e:e[1], reverse=True)
tmp_list=[one for one in sorted_list if one[1]>=threshold]
tmp_list.sort(lambda x,y:cmp(len(x[0]),len(y[0])),reverse=True)
#print tmp_list
print tmp_list[0][0]
if __name__ == '__main__':
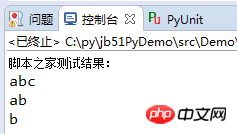
print "脚本之家测试结果:"
one_str='abcabcd'
two_str='abcabcabd'
three_str='bbbbbbb'
main_func(one_str)
main_func(two_str)
main_func(three_str)The results are as follows:
Related recommendations:
Python implementation follows Specify the requirement to output a number in reverse order
Python implements the method of inputting multiple lines in IDLE
The above is the detailed content of Python implements finding the longest non-repeating substring for a given string. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



