


This article mainly introduces the implementation of Huffman encoding/decoding in PHP, which has certain reference value. Now I share it with you. Friends in need can refer to it.
Huffman encoding is a data compression algorithm. The core of our commonly used zip compression is Huffman encoding, and in HTTP/2, Huffman encoding is used to compress HTTP headers.
This article will use PHP to practice Huffman encoding and decoding.
The first step of Huffman encoding is to count the number of occurrences of each character in the document. PHP’s built-in function count_chars( ) You can do this:
$input = file_get_contents('input.txt');$stat = count_chars($input, 1);
Next, construct the Huffman tree based on the statistical results. The construction method is described in detail in Wikipedia. Here is a simple version written in PHP:
$huffmanTree = [];foreach ($stat as $char => $count) { $huffmanTree[] = [ 'k' => chr($char), 'v' => $count, 'left' => null, 'right' => null,
];
}// 构造树的层级关系,思想见wiki:https://zh.wikipedia.org/wiki/%E9%9C%8D%E5%A4%AB%E6%9B%BC%E7%BC%96%E7%A0%81$size = count($huffmanTree);for ($i = 0; $i !== $size - 1; $i++) {
uasort($huffmanTree, function ($a, $b) {
if ($a['v'] === $b['v']) { return 0;
} return $a['v'] < $b['v'] ? -1 : 1;
}); $a = array_shift($huffmanTree); $b = array_shift($huffmanTree); $huffmanTree[] = [ 'v' => $a['v'] + $b['v'], 'left' => $b, 'right' => $a,
];
}$root = current($huffmanTree);After calculation, $root will point to the root node of the Huffman tree
With the Huffman tree, you can generate a dictionary for encoding:
function buildDict($elem, $code = '', &$dict) {
if (isset($elem['k'])) { $dict[$elem['k']] = $code;
} else {
buildDict($elem['left'], $code.'0', $dict);
buildDict($elem['right'], $code.'1', $dict);
}
}$dict = [];
buildDict($root, '', $dict);Use the dictionary to encode the file content and write it to the file. There are several things to pay attention to when writing Huffman encoding to a file:
After writing the encoding dictionary and encoding content to the file together, it is impossible to distinguish their boundaries, so you need to The file starts writing the number of bytes they each occupy
##fwrite() function provided by PHP can write 8-bit (one byte) or An integer multiple of 8 bits. However, in Huffman encoding, a character may be represented by only 1-bit, and PHP does not support the operation of writing only 1-bit to the file. Therefore, we need to splice the encoding ourselves, and only write the file after every 8-bit is obtained.
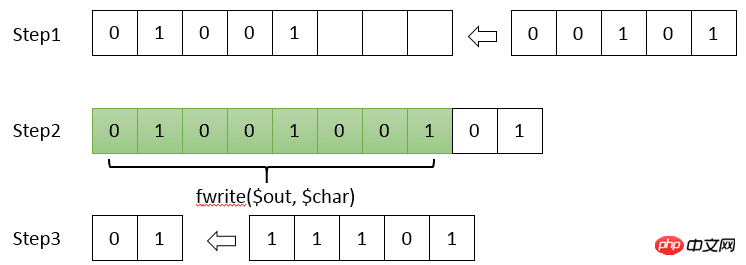
$dictString = serialize($dict);// 写入字典和编码各自占用的字节数$header = pack('VV', strlen($dictString), strlen($input));
fwrite($outFile, $header);// 写入字典本身fwrite($outFile, $dictString);// 写入编码的内容$buffer = '';$i = 0;while (isset($input[$i])) { $buffer .= $dict[$input[$i]]; while (isset($buffer[7])) { $char = bindec(substr($buffer, 0, 8));
fwrite($outFile, chr($char)); $buffer = substr($buffer, 8);
} $i++;
}// 末尾的内容如果没有凑齐 8-bit,需要自行补齐if (!empty($buffer)) { $char = bindec(str_pad($buffer, 8, '0'));
fwrite($outFile, chr($char));
}
fclose($outFile);<?php$content = file_get_contents('a.out');// 读出字典长度和编码内容长度$header = unpack('VdictLen/VcontentLen', $content);$dict = unserialize(substr($content, 8, $header['dictLen']));$dict = array_flip($dict);$bin = substr($content, 8 + $header['dictLen']);$output = '';$key = '';$decodedLen = 0;$i = 0;while (isset($bin[$i]) && $decodedLen !== $header['contentLen']) { $bits = decbin(ord($bin[$i])); $bits = str_pad($bits, 8, '0', STR_PAD_LEFT); for ($j = 0; $j !== 8; $j++) { // 每拼接上 1-bit,就去与字典比对是否能解码出字符
$key .= $bits[$j]; if (isset($dict[$key])) { $output .= $dict[$key]; $key = ''; $decodedLen++; if ($decodedLen === $header['contentLen']) { break;
}
}
} $i++;
}echo $output;Before encoding: 418,504 bytes After encoding: 280,127 bytesThe space is saved by 33%. If the original text has a lot of repeated content, the space saved by Huffman encoding can reach more than 50%.In addition to the text content, we try to Huffman encode a binary file, such as the f.lux installation program. The test results are as follows:
Before encoding: 770,384 bytes After encoding: 773,076 bytesAfter encoding, it takes up more space. On the one hand, we do not do additional processing when we store the dictionary, which takes up a lot of space. On the other hand, in binary files, the probability of each character appearing is relatively even, and the advantages of Huffman coding cannot be used. Related recommendations:
Use PHP to implement a singly linked list
The above is the detailed content of PHP implements Huffman encoding/decoding. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



