


This article mainly shares with you how to completely write a request method for a crawler framework. It has a good reference value and I hope it will be helpful to everyone. Let’s follow the editor to take a look, I hope it can help everyone.
Generate crawler framework:
1. Create a scrapy crawler project
2. Generate a scrapy crawler in the project
3. Configure the spider crawler
4. Run the crawler to obtain the web page
Specific operations:
1. Create a project
Define a project with the name: python123demo
Method:
In cmd, d: Enter the d drive, cd pycodes Enter the file pycodes
Then enter
scrapy startproject python123demo
A file will be generated in pycodes:


##_init_.py does not require user writing


2. Generate a scrapy crawler in the project
Execute a command to Output the name of the crawler and the crawled website
Generate the crawler:

Generate a name Spider
for demo can only generate demo.py, its content is:

name = 'demo' The current crawler name is demo
allowed_domains = " Crawl the links below the domain name of the website. The domain name is entered from the cmd command console
start_urls = [] The initial page to be crawled
parse() is used to process the response, parse the content to form a dictionary, and discover new url crawling requests
3. Configure the generated spider crawler to meet our needs
Save the parsed page into a file
Modify the demo.py file

##4. Run the crawler to get the web page
Open cmd and enter the command line to crawl

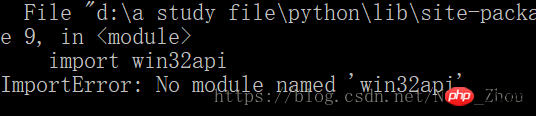
#pip3 install pypiwin32
This is the solution for py3
Note: If you use the pip install pypiwin32 command for the py3 version, an error will occur
After the installation is completed, Run the crawler again, success! Throw flowers!
The captured page is stored in the demo.html file

##The complete code corresponding to demo.py:

The two versions are equivalent:

The above is the detailed content of How to write a complete crawler framework. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



