


This article mainly introduces the method analysis of python crawling the JQuery course of w3shcool and saving it locally. Has very good reference value. Let’s take a look with the editor below
I have been busy looking for a job recently. In my spare time, I also found some reptile projects to practice my skills and write code. I know that I am a rookie, but I need to practice more. Shushan has Road work is the path. If you have any testing pits, can you introduce them to me? Automation, functions, and interfaces can all be done.
First of all, we clearly understand our needs. Many students want to see some technologies when they have nothing to do. For example, I want to see the syntax of JQuery, but I don’t have the Internet now, and I don’t have e-books on my mobile phone. Really It makes us uncomfortable, so don't worry, I'm here to meet your needs. First of all, your need is to obtain the syntax of JQuery, then I see this need, I have a website that responds, so let's go on Go analyze this website. www.w3school.com.cn/jquery/jquery_syntax.asp This is the syntax URL, http://www.w3school.com.cn/jquery/jquery_intro.asp This is the introduction URL, then we got a lot of URL analysis , our www.w3school.com.cn/jquery is the same, so let’s analyze how to get these in the interface. We can see that there is a corresponding target bar on the right, so let’s analyze it
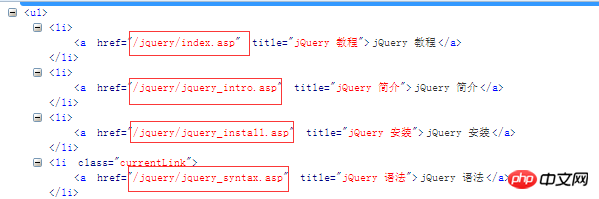
Let’s take a look at these links. We can splice these links together with http://www.w3school.com.cn. Then form our new url,
upload the code
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_textso that we can use the url_s function to get all our links.
['/jquery/index.asp', '/jquery/jquery_intro.asp', '/jquery/jquery_install.asp', '/jquery/jquery_syntax.asp', '/jquery/jquery_selectors.asp', '/jquery/jquery_events.asp', '/jquery/jquery_hide_show.asp', '/jquery/jquery_fade.asp', '/jquery/jquery_slide.asp', '/jquery/jquery_animate.asp', '/jquery/jquery_stop.asp', '/jquery/jquery_callback.asp', '/jquery/jquery_chaining.asp', '/jquery/jquery_dom_get.asp', '/jquery/jquery_dom_set.asp', '/jquery/jquery_dom_add.asp', '/jquery/jquery_dom_remove.asp', '/jquery/jquery_css_classes.asp', '/jquery/jquery_css.asp', '/jquery/jquery_dimensions.asp', '/jquery/jquery_traversing.asp', '/jquery/jquery_traversing_ancestors.asp', '/jquery/jquery_traversing_descendants.asp', '/jquery/jquery_traversing_siblings.asp', '/jquery/jquery_traversing_filtering.asp', '/jquery/jquery_ajax_intro.asp', '/jquery/jquery_ajax_load.asp', '/jquery/jquery_ajax_get_post.asp', '/jquery/jquery_noconflict.asp', '/jquery/jquery_examples.asp', '/jquery/jquery_quiz.asp', '/jquery/jquery_reference.asp', '/jquery/jquery_ref_selectors.asp', '/jquery/jquery_ref_events.asp', '/jquery/jquery_ref_effects.asp', '/jquery/jquery_ref_manipulation.asp', '/jquery/jquery_ref_attributes.asp', '/jquery/jquery_ref_css.asp', '/jquery/jquery_ref_ajax.asp', '/jquery/jquery_ref_traversing.asp', '/jquery/jquery_ref_data.asp', '/jquery/jquery_ref_dom_element_methods.asp', '/jquery/jquery_ref_core.asp', '/jquery/jquery_ref_prop.asp'], ['jQuery 教程', '', 'jQuery 教程', 'jQuery 简介', 'jQuery 安装', 'jQuery 语法', 'jQuery 选择器', 'jQuery 事件', '', 'jQuery 效果', '', 'jQuery 隐藏/显示', 'jQuery 淡入淡出', 'jQuery 滑动', 'jQuery 动画', 'jQuery stop()', 'jQuery Callback', 'jQuery Chaining', '', 'jQuery HTML', '', 'jQuery 获取', 'jQuery 设置', 'jQuery 添加', 'jQuery 删除', 'jQuery CSS 类', 'jQuery css()', 'jQuery 尺寸', '', 'jQuery 遍历', '', 'jQuery 遍历', 'jQuery 祖先', 'jQuery 后代', 'jQuery 同胞', 'jQuery 过滤', '', 'jQuery AJAX', '', 'jQuery AJAX 简介', 'jQuery 加载', 'jQuery Get/Post', '', 'jQuery 杂项', '', 'jQuery noConflict()', '', 'jQuery 实例', '', 'jQuery 实例', 'jQuery 测验', '', 'jQuery 参考手册', '', 'jQuery 参考手册', 'jQuery 选择器', 'jQuery 事件', 'jQuery 效果', 'jQuery 文档操作', 'jQuery 属性操作', 'jQuery CSS 操作', 'jQuery Ajax', 'jQuery 遍历', 'jQuery 数据', 'jQuery DOM 元素', 'jQuery 核心', 'jQuery 属性', '', ''])
This is the name of all links and the corresponding grammar modules of the corresponding links. Then our next step is to splice urls, using str splicing
['http://www.w3school.com.cn//jquery/index.asp', 'http://www.w3school.com.cn//jquery/jquery_intro.asp', 'http://www.w3school.com.cn//jquery/jquery_install.asp', 'http://www.w3school.com.cn//jquery/jquery_syntax.asp', 'http://www.w3school.com.cn//jquery/jquery_selectors.asp', 'http://www.w3school.com.cn//jquery/jquery_events.asp', 'http://www.w3school.com.cn//jquery/jquery_hide_show.asp', 'http://www.w3school.com.cn//jquery/jquery_fade.asp', 'http://www.w3school.com.cn//jquery/jquery_slide.asp', 'http://www.w3school.com.cn//jquery/jquery_animate.asp', 'http://www.w3school.com.cn//jquery/jquery_stop.asp', 'http://www.w3school.com.cn//jquery/jquery_callback.asp', 'http://www.w3school.com.cn//jquery/jquery_chaining.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_get.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_set.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_add.asp', 'http://www.w3school.com.cn//jquery/jquery_dom_remove.asp', 'http://www.w3school.com.cn//jquery/jquery_css_classes.asp', 'http://www.w3school.com.cn//jquery/jquery_css.asp', 'http://www.w3school.com.cn//jquery/jquery_dimensions.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_ancestors.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_descendants.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_siblings.asp', 'http://www.w3school.com.cn//jquery/jquery_traversing_filtering.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_intro.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_load.asp', 'http://www.w3school.com.cn//jquery/jquery_ajax_get_post.asp', 'http://www.w3school.com.cn//jquery/jquery_noconflict.asp', 'http://www.w3school.com.cn//jquery/jquery_examples.asp', 'http://www.w3school.com.cn//jquery/jquery_quiz.asp', 'http://www.w3school.com.cn//jquery/jquery_reference.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_selectors.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_events.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_effects.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_manipulation.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_attributes.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_css.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_ajax.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_traversing.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_data.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_dom_element_methods.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_core.asp', 'http://www.w3school.com.cn//jquery/jquery_ref_prop.asp']
Then we have all these urls, then let’s analyze the article text.
Analysis can show that all our texts are in an id=maincontent, then we directly parse the id=maincontent tag in each interface, obtain the response text document, and save it.
So all our code is as follows:
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text
def xml():
url,url_text=url_s()
url_jque=[]
for link in url:
url_jque.append('http://www.w3school.com.cn/'+link)
return url_jque
def xiazai():
urls=xml()
i=0
for url in urls:
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='maincontent')
with open(r'%s.txt'%i,'wb') as f:
for h in me:
f.write(h.text.encode('utf-8'))
print(i)
i+=1
if __name__ == '__main__':
xiazai()import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[]
m_url=[]
for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('\n')
return m_url,m_url_text
def xml():
url,url_text=url_s()
url_jque=[]
for link in url:
url_jque.append('http://www.w3school.com.cn/'+link)
return url_jque
def xiazai():
urls=xml()
i=0
for url in urls:
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='maincontent')
with open(r'%s.txt'%i,'wb') as f:
for h in me:
f.write(h.text.encode('utf-8'))
print(i)
i+=1
if __name__ == '__main__':
xiazai()Result
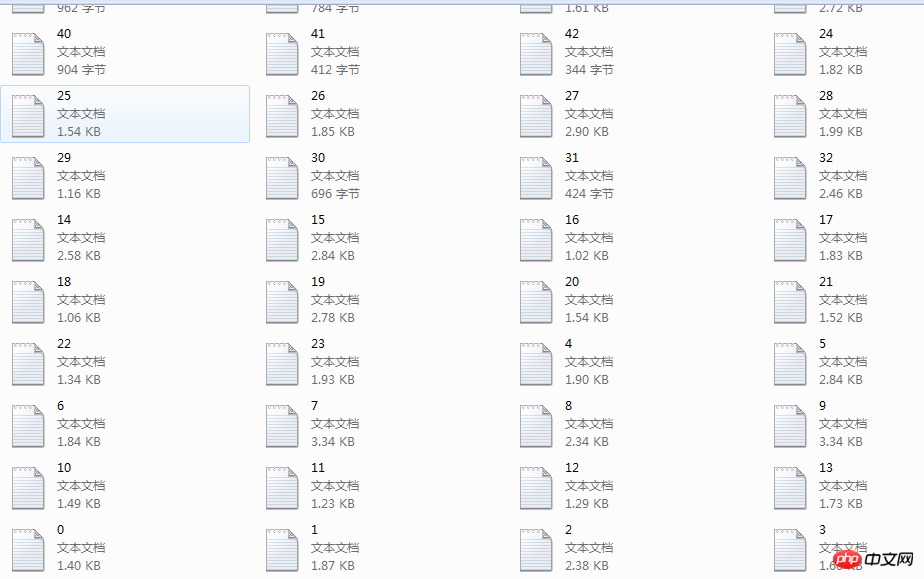
The above is the detailed content of A course that teaches you to use python to crawl w3shcool and save it to local code examples. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



