


With the popularity of JavaScript, a web browser scripting language, it will be beneficial for you to have a basic understanding of its event-driven interaction model and its difference from the common request-response models in Ruby, Python and Java. of. In this post, I'll explain some of the core concepts of JavaScript's concurrency model, including its event loop and message queues, in the hope of improving your understanding of a language you may already be using but perhaps don't fully understand. .
Who is this article written for?
This article is aimed at web developers who use or plan to use JavaScript on the client or server side. If you are already well versed in event loops, most of this article will be familiar to you. For those who aren't quite as proficient yet, I hope to give you a basic understanding that will better help you read and write code on a daily basis.
Non-blocking I/O
In JavaScript, almost all I/O is non-blocking. This includes HTTP requests, database operations, and disk reads and writes. Single-threaded execution requires that when an operation is performed during runtime, a callback function is provided and then continues to do other things. When the operation has completed, the message is inserted into the queue along with the provided callback function. At some point in the future, the message is removed from the queue and the callback function fires.
While this interaction model may be familiar to developers who are already used to working with user interfaces, such as "mousedown," and "click" events being triggered at some point. This is different from the synchronous request-response model typically performed in server-side applications.
Let’s compare two small pieces of code that make an HTTP request to www.google.com and print the response to the console. First, let’s take a look at Ruby and use it with Faraday (a Ruby HTTP client development library):
response = Faraday.get 'http://www.google.com' puts response puts 'Done!'
The execution path is easy to trace:
1. Execute the get method, and the executing thread waits until a response is received
2. The response is received from Google and returned to the caller, it is stored in a variable
3. The value of the variable (in this case, our response) is output to the console
4. The value "Done!" is output to the console
Let’s do the same thing in JavaScript using Node.js and the Request library:
request('http://www.google.com', function(error, response, body) {
console.log(body);
});
console.log('Done!');It looks slightly different on the surface, but the actual behavior is completely different:
1. Execute the request function, pass an anonymous function as a callback, and execute the callback when the response is available at some time in the future.
2. "Done!" is output to the console immediately
3. At some point in the future, when the response returns and the callback is executed, output its content to the console
Event Loop
Decouple the caller and response so that JavaScript can do other things while waiting for the asynchronous operation to complete and the callback to fire during the runtime. But how are these callbacks organized in memory and in what order are they executed? What causes them to be called?
The JavaScript runtime contains a message queue, which stores a list of messages that need to be processed and related callback functions. These messages are queued in response to external events involved in the callback function (such as mouse clicks or responses to HTTP requests). For example, if the user clicks a button and no callback function is provided, no message will be queued.
In a loop, the queue fetches the next message (each fetch is called a "tick"), and when an event occurs, the message's callback is executed.
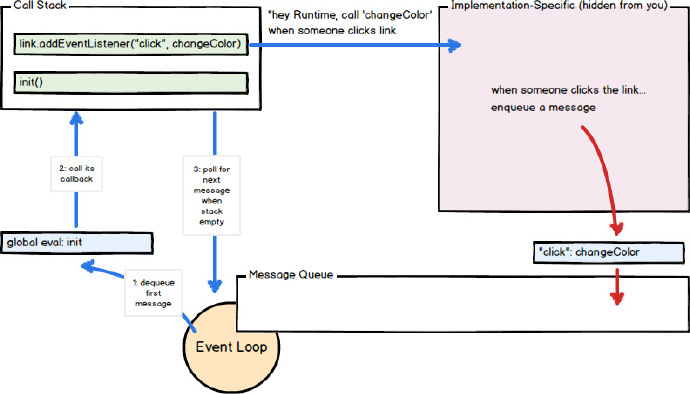
The call to the callback function acts as an initialization frame (fragment) in the call stack. Since JavaScript is single-threaded, future message extraction and processing are stopped while waiting for all calls in the stack to return. Subsequent (synchronous) function calls will add new call frames to the stack (for example, function init calls function changeColor).
function init() {
var link = document.getElementById("foo");
link.addEventListener("click", function changeColor() {
this.style.color = "burlywood";
});
}
init();
In this example, when the user clicks the "foo" element, a message (and its callback function changeColor) will be inserted into the queue and the "onclick" event will be triggered. When a message leaves the queue, its callback function changeColor is called. When changeColor returns (or throws an error), the event loop continues. As long as the function changeColor exists and is specified as a callback to the onclick method of the "foo" element, then clicking on that element will cause more messages (and the associated callback changeColor) to be inserted into the queue.
Queue append message
If a function is called asynchronously in code (such as setTimeout), the provided callback will eventually be executed as part of a different message queue, which will occur on some future action in the event loop. For example:
function f() {
console.log("foo");
setTimeout(g, 0);
console.log("baz");
h();
}
function g() {
console.log("bar");
}
function h() {
console.log("blix");
}
f();由于setTimeout的非阻塞特性,它的回调将在至少0毫秒后触发,而不是作为消息的一部分被处理。在这个示例中,setTimeout被调用, 传入了一个回调函数g且延时0毫秒后执行。当我们指定时间到达(当前情况是,几乎立即执行),一个单独的消息将被加入队列(g作为回调函数)。控制台打印的结果会是像这样:“foo”,“baz”,“blix”,然后是事件循环的下一个动作:“bar”。如果在同一个调用片段中,两个调用都设置为setTimeout -传递给第二个参数的值也相同-则它们的回调将按照调用顺序插入队列。
Web Workers
使用Web Workers允许您能够将一项费时的操作在一个单独的线程中执行,从而可以释放主线程去做别的事情。worker(工作线程)包括一个独立的消息队列,事件循 环,内存空间独立于实例化它的原始线程。worker和主线程之间的通信通过消息传递,看起来很像我们往常常见的传统事件代码示例。

首先,我们的worker:
// our worker, which does some CPU-intensive operation
var reportResult = function(e) {
pi = SomeLib.computePiToSpecifiedDecimals(e.data);
postMessage(pi);
};
onmessage = reportResult;然后,主要的代码块在我们的HTML中以script-标签存在:
// our main code, in a <script>-tag in our HTML page
var piWorker = new Worker("pi_calculator.js");
var logResult = function(e) {
console.log("PI: " + e.data);
};
piWorker.addEventListener("message", logResult, false);
piWorker.postMessage(100000);在这个例子中,主线程创建一个worker,同时注册logResult回调函数到其“消息”事件。在worker里,reportResult函数注册到自己的“消息”事件中。当worker线程接收到主线程的消息,worker入队一条消息同时带上reportResult回调函数。消息出队时,一条新消息发送回主线程,新消息入队主线程队列(带上logResult回调函数)。这样,开发人员可以将cpu密集型操作委托给一个单独的线程,使主线程解放出来继续处理消息和事件。
关于闭包的
JavaScript对闭包的支持,允许你这样注册回调函数,当回调函数执行时,保持了对他们被创建的环境的访问(即使回调的执行时创建了一个全新的调用栈)。理解我们的回调作为一个不同的消息的一部分被执行,而不是创建它的那个会很有意思。看看下面的例子:
function changeHeaderDeferred() {
var header = document.getElementById("header");
setTimeout(function changeHeader() {
header.style.color = "red";
return false;
}, 100);
return false;
}
changeHeaderDeferred();
在这个例子中,changeHeaderDeferred函数被执行时包含了变量header。函数 setTimeout被调用,导致消息(带上changeHeader回调)被添加到消息队列,在大约100毫秒后执行。然后 changeHeaderDeferred函数返回false,结束第一个消息的处理,但header变量仍然可以通过闭包被引用,而不是被垃圾回收。当 第二个消息被处理(changeHeader函数),它保持了对在外部函数作用域中声明的header变量的访问。一旦第二个消息 (changeHeader函数)执行结束,header变量可以被垃圾回收。
提醒
JavaScript 事件驱动的交互模型不同于许多程序员习惯的请求-响应模型,但如你所见,它并不复杂。使用简单的消息队列和事件循环,JavaScript使得开发人员在构建他们的系统时使用大量asynchronously-fired(异步-触发)回调函数,让运行时环境能在等待外部事件触发的同时处理并发操作。然而,这不过是并发的一种方法。
以上就是本文的全部内容,希望对大家的学习有所帮助。
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



