


Dify is an open-sourced SaaS platform for building LLM workflows online. I'm using the API to create conversational AI experience on my app. I was struggling with getting TTS streams as the API response and play it. Here I demonstrates how to process the audio streams and play it correctly.
I'm using the API endpoint https://api.dify.ai/v1/chat-messages for text chat. It returns audio data in the same stream as the text response if we enabled Text to Speach feature in our Dify apps.
Press ADD FEATURE button and add Text to Speach feature.
You can check the response from API with the following curl command.
curl -X POST 'https://api.dify.ai/v1/chat-messages' \ --header 'Authorization: Bearer YOUR_API_KEY' \ --header 'Content-Type: application/json' \ --data-raw '{ "inputs": {}, "query": "What are the specs of the iPhone 13 Pro Max?", "response_mode": "streaming", "conversation_id": "", "user": "abc-123", "files": [] }'
I demonstrate in TypeScript / JavaScript but you can apply the same logic to your programming language.
First, let's understand what kind of data Dify is using for the streams.
Dify is using the following text data format. It is like JSON lines but it is not the same exactly.
data: {"event": "workflow_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "50100b30-e458-4632-ad7d-8dd383823376", "workflow_id": "debdb4fa-dcab-4233-9413-fd6d17b9e36a", "sequence_number": 334, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123"}, "created_at": 1724478014}} data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": null, "created_at": 1724478013, "extras": {}}} data: {"event": "node_finished", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "process_data": null, "outputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "status": "succeeded", "error": null, "elapsed_time": 0.001423838548362255, "execution_metadata": null, "created_at": 1724478013, "finished_at": 1724478013, "files": []}} data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "89ed58ab-6157-499b-81b2-92b1336969a5", "node_id": "llm", "node_type": "llm", "title": "LLM", "index": 2, "predecessor_node_id": "1721365917005", "inputs": null, "created_at": 1724478013, "extras": {}}} ...
In the response, Dify pushes text answer and audio data.
Example line of text answer
data: {"event": "message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "answer": "MP"}
Example line of audio data
data: {"event": "tts_message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "audio": "//PkxABhvDm0DVp4ACUUfvWc1CFlh0tR9Oh7LxzHRsGBuGx155x3JqTJiwKKZf8wIcxpMzJU0h4zhgyQwwwIsgWQMAALQMkanBTjfCPgZwFsDOGGIYJoJoJoJoPQPQLYEgAOwM4SMXMW8TcNWGrEPEME0HoIQTg0DQNA0C5k7IOLeJuDnDVi5nWyJwgghAagQwTQQgJAGrDVibiFhqw1YR8HOEjBUA5AcgagQwTQTQQgJAAtgLYKsQ8hZc0PV7OrE4SgQgFIAsAQAwA6H0Uv4t4m4m49Yt4uYOQHIBkAyAqAkAuB0Mm6UeKxDGRrIODkByBqBNBCA1ARwHIEgBVg5wkY41W2GgdEVDFBNe+HicQw0ydk7HrHrIWXM62d48ePNfCkNATcTcNWGrCRhqxDxcwMYBwBkByCGC4EILgoJTQUDeW8W8TcTchZ1qBWIYchOBbBCA1AhgSMJGGrFzLmh6fL+LeBkAyAZAcgSAXAhB0Kxnj4YDkJwXA6FAzwj8IIJoJoPQXA6EPOcg4R8FOBnCRljRAwlwoh4EUwLhFTCVA+MR0R8wyxOhgAwwDgJjBUABMM0hMxBgnTPtMrMBEEcwJQCzIXIdMZMG821DmjDKHJAwLDKHRMQsJkwbwVRoFs//PkxEx5dDnwAZ7wANHgEUFJHGCUCQp3LWCQQYGAATI5QzwHBJF4UFktpfATT2l0goAGNADLOU64HAMCQCK50szABAIkDS2/j8gl6l6Di7QgBEiAfMEADBnyZBgeAWCMK4xvBbhoRZj1M+ktsNMTrMNcHEwHQEzAjAHMGQAQwRQZTBHALMGMDkzhh2jGhLtMgsMMwfhOzCnGLMMcKgwOw8pqHMoGtvdDzos0AIAiXIsBAmGsRFtYcBABmB0AUYjQfhhDAfjoCrETAGArMOAJ4iAAMCMFkwXwh5fffuhpYMhyP2bl3MVAJQrSYQDsna7G2+fx/GvyAwUQbTAdAFCAHVKyIAduTXHZZXDjNS57/VeVJ5+JBJ+0kATkCSells8/NBt/2/5Dj1s+chDBYSINutNS9FQwDwBWHjgASKRgAAJOyYC4Ao0CMNAKBgB6KK1hYBkAAHROM9mLsknb8avTcB0MerV6jl7llE70egOerRh9WcP/FoHqtVsO/In2f+G2tsdnH+L/KSSvBQB4OATam27Yi4jiBgBFOpq15bTQU6k1G4LoWo1mMAwDQwlBEzEnKsMkA7c5JYuTOzK2MvAbEysSPTM+dOOn1XEzGgIzXzmPODVvs1cyNTJxQ9MsAWwy//PkxDlz7DIMAd7gAek5EwnjcjX9QVN1N0czFyijQKOmMi4IYw8RvzFvCHMHYBQwdQlTRxVNvm8ycGjLYlMTAQ=="}
We can distinguish JSON lines of audio data by checking the event property. Audio JSON has tts_message as the value. The audio mp3 binary is stored in the audio property of the JSONs in base64 format.
The first problem that we have when we play TTS audio real-time is the JSON lines are split into packets and each packet is not valid JSON data as it is.
Example packet which is cut in a middle
euimRrhsPMZiMAl+BqSZMDmIkQEcDb/8+TEtHm8MhwA3p/p8dA0CCpAxwMMPABoYMIWwUDG6BRmiYZg2G6gRidGanOm5i5iaIYmfkH8Z/FmEopqJGZKXihYEIRxCKYKtlQuMvPjPQIwUVFFECDRnRCYEimGmA6cji41yQMImMEmhaHrVKpCxo2OYx6Q5RcJKAKkah4X6MckHEqdwKgHGHltDUjCy46HMgTCpwodAM8KijREwSSEk5hB4gRGFfC0ouYoeDiYtNREDgKQsTT6EI4egmMMBxpQZmoUJmAAg6YPDmQISgSECAZQOLfAUEQAG/dgxAVkxfFHGorEHB4CS+Yugwk2gq8akIwMsZIuIzUSrCAGm1iBnoYA8lcoYSlaIJ5RjCblwbsh8sB3skA7Gcx3zmSOKnXNJO6ObKklhuYjlVL1dSMhgwVJtFzMeWFufNKy3ODmCExBTUUzLjEwMKqqqqqqqqqqqqqqqqqqCIEWFIAA4DAWKkMDDIBA4lBqGDdmZwzAkGJFoYiwEV0IQOQHg1AATJiUM6F0z2fDE6PMvlc6DhTMJ+MNH4xWwzBwKMMCgHAwwUFQwjGEgMgovgIBMIMECYxYSDKAwSoMOBC4Ez682pEZIB8kBuiawZEaSnFAjIEwSFRxGUJIXMGRMmfNCPApcKL/8+TEiVdEKlJm5pM9gz0MyScwo04BgqjEFh489MGKVw=="}
The packet is starting from the middle of a JSON line. We have to combine multiple packets to get valid JSONs lines.
The second problem is the audio data chunk in a JSON is not a valid audio data. The data is cut in a middle of mp3 frames.
To handle the split data of JSON and mp3, we have to do some smart way. The flow of the process is following:
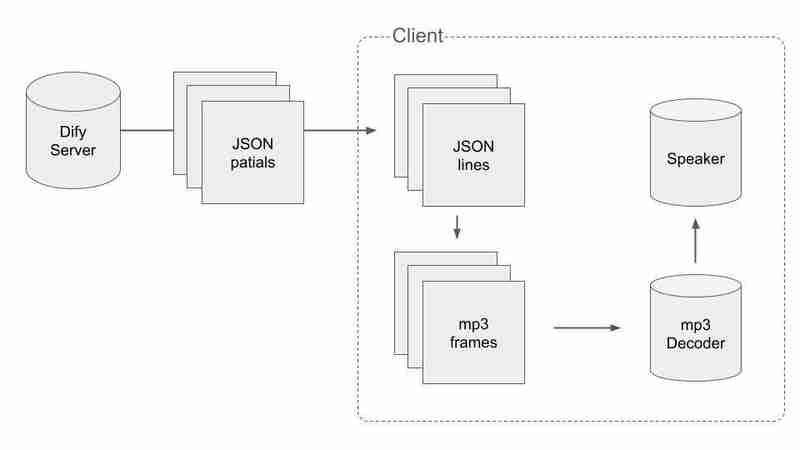
First, we have to get valid JSON data and split into JSONs while receiving packets. When we got a packet with n at the end, we can say the concatenation of the packets received so far is not cut in the middle. The pseudo code is like this.
let packets = [] stream.on('data', (bytes) => { const text = bytes.toString() packets.push(text) if (text.endsWith('\n')) { // Extract audio data from the packets. const audioChunks = extractAudioChunks(packets.join('')) // Clear the packet array packets = [] } })
Second, we have to split the audio chunks into mp3 frames. We concat the audio chunks into a binary and find each mp3 frames in it.
const mp3Frames = [] const binaryToProcess = Buffer.concat([...audioChunks]) let frameStartIndex = 0 for (let i = 0; i < binaryToProcess.length; i += 1) { const currentByte = binaryToProcess[i] const nextByte = binaryToProcess[i + 1] // MP3 frame header always starts with eleven 1 bits. Checking 2 bytes. // It is a beginning of mp3 frame if current byte is 0xff and the beginning of the next byte is 111. // MP3 Spacification // http://www.mp3-tech.org/programmer/frame_header.html if (currentByte === 0xff && (nextByte & 0b11100000) === 0b11100000) { mp3Frames.push(binaryToProcess.subarray(frameStartIndex, i)) frameStartIndex = i } }
This is not the full implementation of splitting into mp3 frames. In the actual process, we have to consider cases that we have remainder bytes when we extracted mp3 frames from the audio binary and use the remainder as the beginning of the audio bytes in the next iteration. Please check my Github repo for the full implementation.
The above is the detailed content of How to realize Real-Time Speech with Dify API. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



