The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
The authors of this paper are teachers and students from the Institute of Multi-Agent and Embodied Intelligence of Pengcheng Laboratory, Southern University of Science and Technology, and Sun Yat-sen University The team includes Professor Lin Liang (Director of the Institute, National Distinguished Young Scholar, IEEE Fellow), Professor Zheng Feng, Professor Liang Xiaodan, Wang Zhiqiang (Southern University of Science and Technology), Zheng Hao (Southern University of Science and Technology), Nie Yunshuang (CUHK), Xu Wenjun (Pengcheng) ), Ye Hua (Pengcheng), etc. The team of Professor Lin Liang of Pengcheng Laboratory is committed to building general basic platforms such as multi-agent collaboration and simulation training platforms and cloud collaborative embodied multi-modal large models to empower major application needs such as the industrial Internet and social governance and services.
Since this year, embodied intelligence is becoming a hot field in academia and industry, and related products and results are emerging one after another. Today, Pengcheng Laboratory's Institute of Multi-Agent and Embodied Intelligence (hereinafter referred to as Pengcheng Embodied Institute), together with Southern University of Science and Technology and Sun Yat-sen University, officially released and open sourced its latest academic achievements in the field of embodied intelligence - ARIO (All Robots) In One) embodied large-scale data set aims to solve the data acquisition problems currently faced in the field of embodied intelligence.


Paper title: All Robots in One: A New Standard and Unified Dataset for Versatile.General-Purpose Embodied Agents
Paper link: http://arxiv.org/abs/2408.10899
Project homepage: https://imaei.github.io/project_pages/ario/
Pengcheng Laboratory Embodiment Institute website link: https://imaei.github.io/
作為具身機器人的大腦,想要讓具身大模型的表現更優,關鍵在於能否獲得高品質的具身大數據。不同於大語言模型或視覺大模型用到的文本或影像數據,具身數據無法從互聯網海量內容中直接獲取,而需透過真實的機器人操作來採集或高級仿真平台生成,因此具身數據的採集需要較高的時間和成本,很難達到較大的規模。
同時,目前開源的資料集也存在多項不足,如上表所示,JD ManiData、ManiWAV 和RH20T 本身資料量不大,DROID 資料用到的機器人硬體平台比較單一,Open-X Embodiment雖然達到了較大規模的資料量,但其感知資料模態不夠豐富,而且子資料集之間的資料格式不統一,品質也參差不齊,使用資料之前需要花大量時間進行篩選和處理,難以滿足複雜場景下具身智慧模型的高效率和針對性的訓練需求。
相較而言,這次發布的ARIO 資料集,包含了
2D、3D、文字、觸覺、聲音5 種模態的感知資料,涵蓋
操作和
導覽兩大類導航任務,既有
仿真數據,也有
真實場景數據,並且包含多種機器人硬件,有很高的豐富度。在資料規模達到三百萬的同時,也確保了資料的統一格式,是目前具身智慧領域同時達到高品質、多樣化和大規模的開源資料集。
對於具身智能的資料集而言,由於機器人有多種形態,如單臂、雙臂、人形、四足等,並且感知和控制方式也各不相同,有些透過關節角度控制,有些則是透過本體或末端位姿座標來驅動,所以具身資料本身比單純的影像和文字資料複雜得多,需要記錄很多控制參數。而如果沒有一個統一的格式,當多種類型的機器人資料聚合在一起,就需要花費大量的精力去做額外的預處理。
因此鵬城實驗室具身所首先設計了一套針對具身大數據的格式標準,該標準能記錄多種形態的機器人控制參數,並且有結構清晰的數據組織形式,還能相容於不同幀率的感測器並記錄對應的時間戳,以滿足具身智慧大模型對感知和控制時序的精確要求。下圖展示了 ARIO 資料集的整體設計。
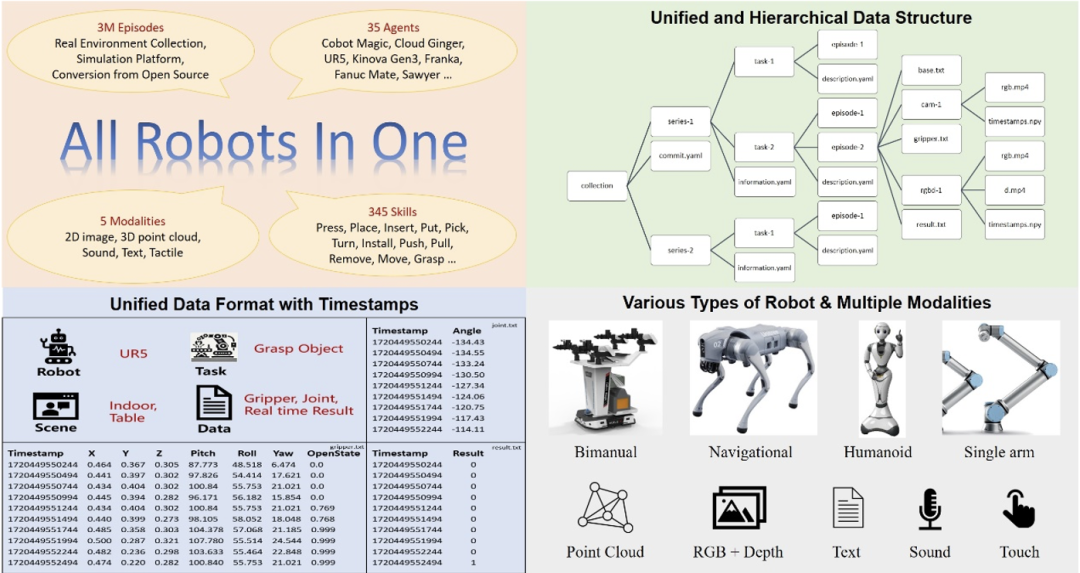
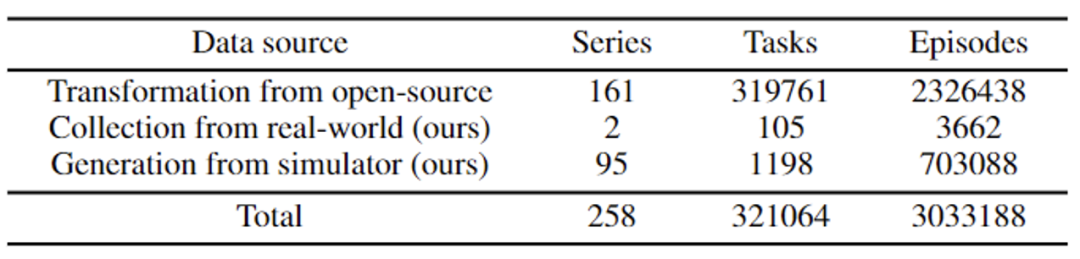
.個場景序列,321064 個任務,303 萬個範例。 ARIO 的資料有3 大來源,一是透過佈置真實環境下的場景與任務進行真人採集;二是
基於MuJoCo、Habitat 等模擬引擎
,設計虛擬場景與物件模型,透過模擬引擎驅動機器人模型的方式產生;三是
將目前已開源的具身資料集,逐一分析處理,轉換為符合ARIO 格式標準的資料
。下面展示了 ARIO 資料集的具體構成,以及 3 個來源的流程和範例。
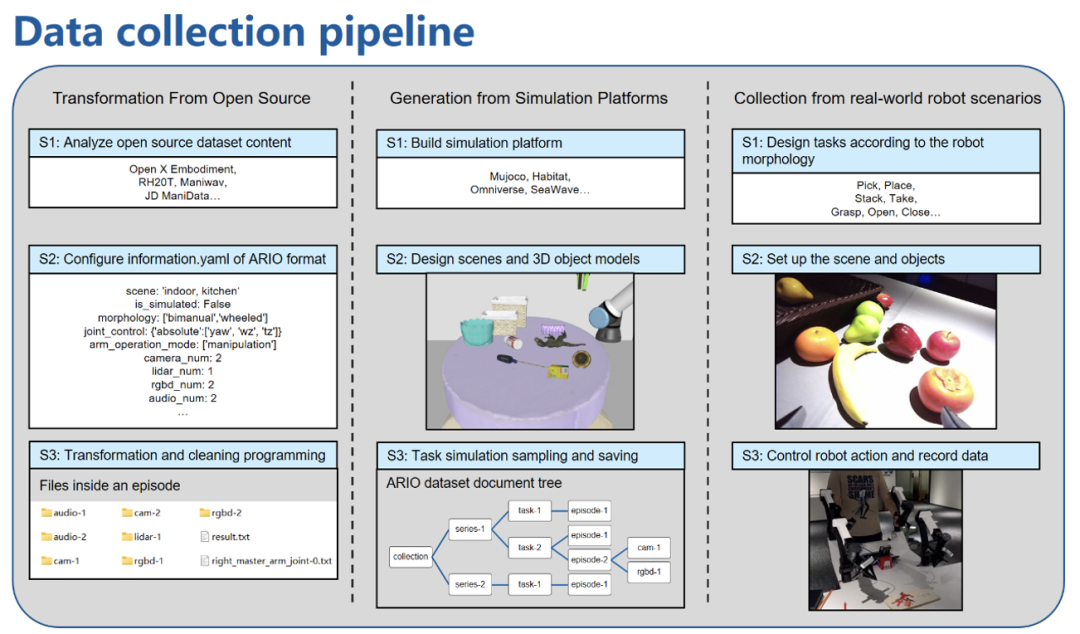
真實場景的高品質的機器人資料不易獲取,但意義重大。鵬城實驗室基於Cobot Magic 主從雙臂機器人,設計了30 多種任務,包括簡單—— 中等—— 困難3 個操作難易等級,並透過增加干擾物體、隨機改變物體和機器人位置、改變佈置環境等方式增加範例的多樣性,最終得到3000 多張包含3 個rgbd 相機的軌跡資料。下面展示了不同任務的採集範例以及擷取影片。
圖3. ARIO 真實機器人資料擷取範例 Cobot Magic 機械手臂擷取資料範例影片

 以Dataa SeaWave平台的模擬資料產生範例影片
以Dataa SeaWave平台的模擬資料產生範例影片
 從RH20T 轉換中的資料範例影片於
利資料的統一格式設計,能夠很方便地對它的資料組成進行統計分析。下圖展示了從 series、task、episode 三個層面對 ARIO 的場景(圖 a)和技能(圖 b)的分佈進行統計。從中可見,目前大部分的具身資料都集中在室內生活家居環境中的場景和技能。
從RH20T 轉換中的資料範例影片於
利資料的統一格式設計,能夠很方便地對它的資料組成進行統計分析。下圖展示了從 series、task、episode 三個層面對 ARIO 的場景(圖 a)和技能(圖 b)的分佈進行統計。從中可見,目前大部分的具身資料都集中在室內生活家居環境中的場景和技能。
 除了場景和技能,在 ARIO 數據中,還能從機器人本身的角度進行統計分析,並從中了解當前機器人行業的一些發展態勢。 ARIO 資料集提供了機器人形態、運動物件、物理控制變數、感測器種類和安裝位置、視覺感測器的數量、控制方式比例、資料擷取方式比例、機械手臂自由度數量比例的統計數據,對應下圖 a-i。
除了場景和技能,在 ARIO 數據中,還能從機器人本身的角度進行統計分析,並從中了解當前機器人行業的一些發展態勢。 ARIO 資料集提供了機器人形態、運動物件、物理控制變數、感測器種類和安裝位置、視覺感測器的數量、控制方式比例、資料擷取方式比例、機械手臂自由度數量比例的統計數據,對應下圖 a-i。
 以下圖 a 為例,從中可以發現,目前大部分的資料來自單臂機器人,人形機器人的開源資料很少,且主要來自鵬城實驗室的真實採集與模擬產生。
更多關於 ARIO 資料集的詳細資訊與下載鏈接,請參考論文原文與專案主頁。
以下圖 a 為例,從中可以發現,目前大部分的資料來自單臂機器人,人形機器人的開源資料很少,且主要來自鵬城實驗室的真實採集與模擬產生。
更多關於 ARIO 資料集的詳細資訊與下載鏈接,請參考論文原文與專案主頁。
The above is the detailed content of It is always said that embodied intelligence data is too expensive, Pengcheng Laboratory open sourced a million-scale standardized data set. For more information, please follow other related articles on the PHP Chinese website!

































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



