


If you have idle equipment, maybe you can give it a try.
This time, the hardware device in your hand can also flex its muscles in the field of AI.
By combining iPhone, iPad, and Macbook, you can assemble a "heterogeneous cluster inference solution" and then run the Llama3 model smoothly.

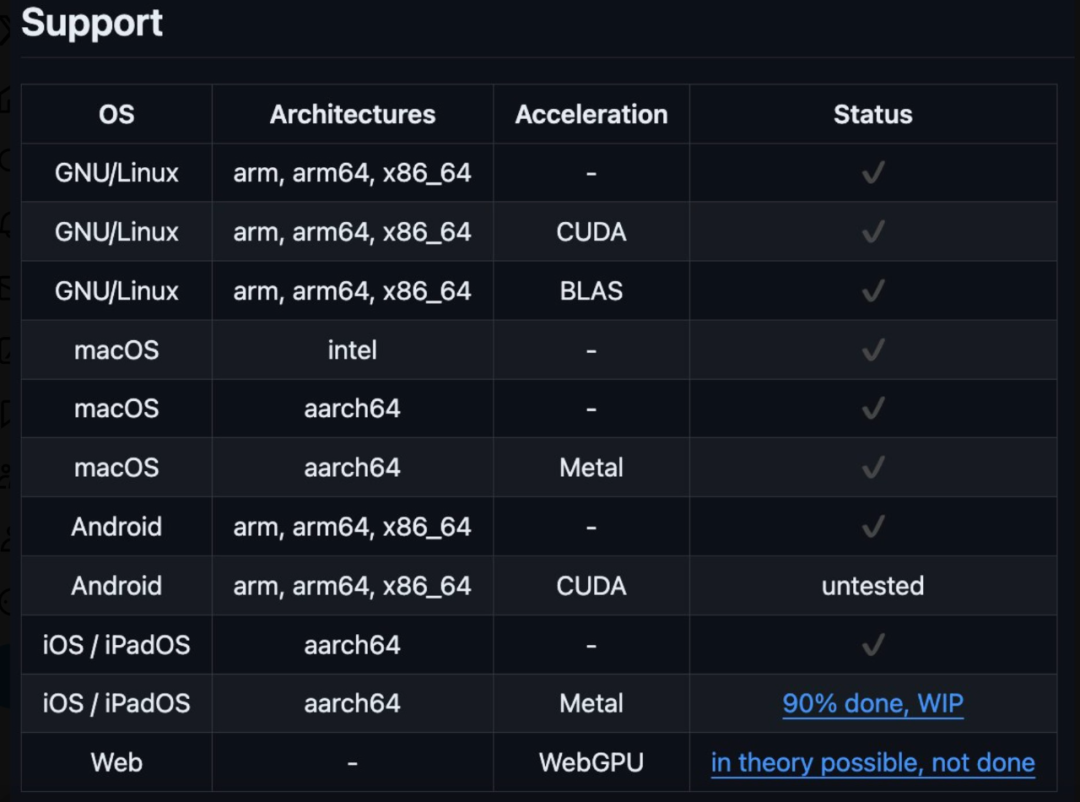
It is worth mentioning that this heterogeneous cluster can be a Windows system, Linux, or iOS system, and support for Android will be coming soon. The heterogeneous cluster is running.
 According to the project author @evilsocket, this heterogeneous cluster includes iPhone 15 Pro Max, iPad Pro, MacBook Pro (M1 Max), NVIDIA GeForce 3080, 2x NVIDIA Titan X Pascal. All code has been uploaded to GitHub. Seeing this, netizens expressed that this old man is indeed not simple.
According to the project author @evilsocket, this heterogeneous cluster includes iPhone 15 Pro Max, iPad Pro, MacBook Pro (M1 Max), NVIDIA GeForce 3080, 2x NVIDIA Titan X Pascal. All code has been uploaded to GitHub. Seeing this, netizens expressed that this old man is indeed not simple.
However, some netizens are beginning to worry about energy consumption. Regardless of speed, the electricity bill cannot be afforded. Moving data back and forth causes too much loss.


Project address: https://github.com/evilsocket/cake
The main idea of Cake is to shard transformer blocks to multiple devices to be able to run inference on models that typically do not fit into the GPU memory of a single device . Inference on consecutive transformer blocks on the same worker thread is done in batches to minimize delays caused by data transfer. 
cargo build --release
Copy after login
make ios
Use
to run the worker node:cake-cli --model /path/to/Meta-Llama-3-8B \ # model path, read below on how to optimize model size for workers --mode worker \# run as worker --name worker0 \ # worker name in topology file --topology topology.yml \# topology --address 0.0.0.0:10128 # bind address
Copy after login
cake-cli --model /path/to/Meta-Llama-3-8B \ --topology topology.yml
linux_server_1:host: 'linux_server.host:10128'description: 'NVIDIA Titan X Pascal (12GB)'layers:- 'model.layers.0-5'linux_server_2:host: 'linux_server2.host:10128'description: 'NVIDIA GeForce 3080 (10GB)'layers:- 'model.layers.6-16'iphone:host: 'iphone.host:10128'description: 'iPhone 15 Pro Max'layers:- 'model.layers.17'ipad:host: 'ipad.host:10128'description: 'iPad'layers:- 'model.layers.18-19'macbook:host: 'macbook.host:10128'description: 'M1 Max'layers: - 'model.layers.20-31'
cake-split-model --model-path path/to/Meta-Llama-3-8B \ # source model to split --topology path/to/topology.yml \# topology file --output output-folder-name
The above is the detailed content of so cool! Old iPhone, iPad, and MacBook devices form a heterogeneous cluster and can run Llama 3. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



