Advances in sequence modeling have been extremely impactful as they play an important role in a wide range of applications, including reinforcement learning (e.g., robotics and autonomous driving), time series classification (e.g., financial fraud detection and medicine diagnosis) etc. In the past few years, the emergence of Transformer has marked a major breakthrough in sequence modeling. This is mainly due to the fact that Transformer provides a method that can take advantage of GPU parallelism. High-performance architecture for processing. However, Transformer has a high computational overhead during inference, mainly due to the quadratic expansion of memory and computing requirements, thus limiting its application in low-resource environments (such as , mobile and embedded devices). Although techniques such as KV caching can be adopted to improve inference efficiency, Transformer is still very expensive for low-resource domains due to: (1) memory that increases linearly with the number of tokens, and (2) caching all previous tokens into the model. This problem affects Transformer inference even more in environments with long contexts (i.e., large numbers of tokens). In order to solve this problem, researchers from the Royal Bank of Canada AI Research Institute Borealis AI and the University of Montreal provided a solution in the paper "Attention as an RNN". It is worth mentioning that we found Turing Award winner Yoshua Bengio appearing in the author column.
- ##Paper address: https://arxiv.org/ pdf/2405.13956
- Paper title: Attention as an RNN
##Specifically, the researcher first Examined the attention mechanism in Transformer, which is the component that causes quadratic growth in the computational complexity of Transformer. This study shows that the attention mechanism can be viewed as a special type of recurrent neural network (RNN), with the ability to efficiently compute many-to-one RNN outputs. Utilizing the RNN formulation of attention, this study demonstrates that popular attention-based models such as Transformer and Perceiver can be considered RNN variants.
However, unlike traditional RNNs such as LSTM and GRU, popular attention models such as Transformer and Perceiver can be considered RNN variants. Unfortunately, they cannot be updated efficiently with new tokens.
To solve this problem, this research introduces a new attention formula based on the parallel prefix scan algorithm , this formula can efficiently calculate the many-to-many RNN output of attention, thereby achieving efficient updates.
Based on this new attention formula, this study proposed Aaren ([A] attention [a] s a [re] current neural [n] etwork), This is a computationally efficient module that can not only be trained in parallel like a Transformer, but can also be updated as efficiently as an RNN.
Experimental results show that Aaren performs comparably to Transformer on 38 data sets covering four common sequence data settings: reinforcement learning, event prediction , time series classification and time series prediction tasks, while being more efficient in terms of time and memory. Method introduction
In order to solve the above problems, the author proposed an attention-based A highly efficient module that takes advantage of GPU parallelism while updating efficiently.
First, the authors show in Section 3.1 that attention can be viewed as a type of RNN with the special ability to efficiently compute the output of many-to-one RNNs (Figure 1a) . Leveraging the RNN form of attention, the authors further illustrate that popular attention-based models, such as Transformer (Figure 1b) and Perceiver (Figure 1c), can be considered RNNs. However, unlike traditional RNNs, these models cannot efficiently update themselves based on new tokens, limiting their potential in sequential problems where data arrives in the form of a stream. 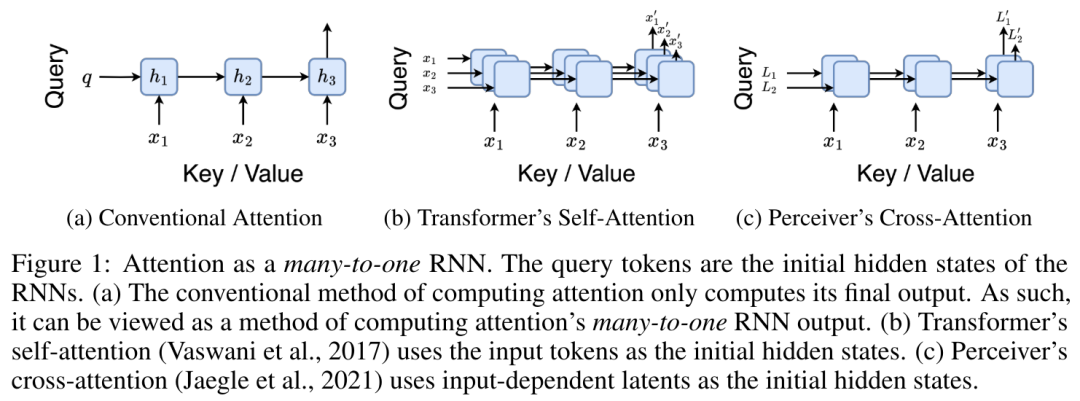
In order to solve this problem, the author introduces a many-to-many RNN calculation based on the parallel prefix scanning algorithm in Section 3.2 Highly effective ways to focus. On this basis, the author introduced Aaren in Section 3.3 - a computationally efficient module that can not only be trained in parallel (just like Transformer), but can also be efficiently updated with new tokens during inference. Inference only requires a constant Memory (just like traditional RNN).Consider attention as a many-to-one RNNQuery vector q Attention can be viewed as a function that maps the keys and values of N context tokens x_1:N to a single output o_N = Attention (q, k_1:N, v_1:N). Given s_i = dot (q, k_i), the output o_N can be expressed as: 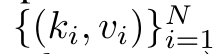
and the denominator is
. Thinking of attention as an RNN, 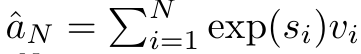 and
and  can be iteratively calculated in a rolling summation manner when k = 1,...,.... In practice, however, this implementation is unstable and suffers from numerical problems due to limited precision representation and potentially very small or very large exponents (i.e., exp (s)). In order to alleviate this problem, the author uses the cumulative maximum value term
can be iteratively calculated in a rolling summation manner when k = 1,...,.... In practice, however, this implementation is unstable and suffers from numerical problems due to limited precision representation and potentially very small or very large exponents (i.e., exp (s)). In order to alleviate this problem, the author uses the cumulative maximum value term 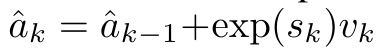 to rewrite the recursion formula to calculate
to rewrite the recursion formula to calculate  and
and 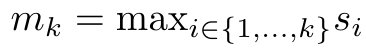 . It is worth noting that the end result is the same
. It is worth noting that the end result is the same 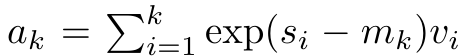 , the loop calculation of m_k is as follows:
, the loop calculation of m_k is as follows: 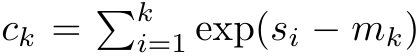
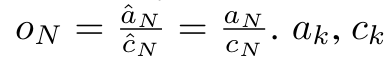
By encapsulating the loop calculations of a_k, c_k and m_k from a_(k-1), c_(k-1) and m_(k-1), the author introduces an RNN unit that can iteratively calculate attention output (see Figure 2). The attention RNN unit takes (a_(k-1), c_(k-1), m_(k-1), q) as input and computes (a_k, c_k, m_k, q). Note that the query vector q is passed in the RNN unit. The initial hidden state of the attention RNN is (a_0, c_0, m_0, q) = (0, 0, 0, q).  Methods to calculate attention: By considering attention as an RNN, you can see different ways to calculate attention: loop calculation token by token in O (1) memory (i.e. sequential calculation) ;or computed in the traditional way (i.e. parallel computing), which requires linear O (N) memory. Since attention can be regarded as an RNN, the traditional method of calculating attention can also be regarded as an efficient method of calculating the output of the attention many-to-one RNN, that is, the output of the RNN takes multiple context tokens as input, but in At the end of the RNN, only one token is output (see Figure 1a). Finally, attention can also be computed as an RNN that processes tokens chunk by chunk, rather than fully sequentially or fully in parallel, which requires O(b) memory, where b is the size of the chunk. Consider existing attention models as RNNs. By treating attention as an RNN, existing attention-based models can also be viewed as variants of RNN. For example, the Transformer's self-attention is an RNN (Figure 1b), and the context token is its initial hidden state. Perceiver’s cross-attention is an RNN (Figure 1c) whose initial hidden state is a context-dependent latent variable. By leveraging RNN forms of their attention mechanism, these existing models can efficiently compute their output stores. However, when considering existing attention-based models (such as Transformers) as RNNs, these models lack the features commonly seen in traditional RNNs (such as LSTM and GRU). important attributes. It is worth noting that LSTM and GRU can effectively update themselves with new tokens in only O(1) constant memory and computation, in contrast to Transformer's The RNN view (see Figure 1b) handles new tokens by adding a new RNN with the new token as the initial state. This new RNN processes all previous tokens, requiring O(N) linear computation. In Perceiver, due to its architecture, latent variables (L_i in Figure 1c) are input-dependent, which means that their values are dependent on receiving new tokens. will change from time to time. As the initial hidden state (i.e. latent variables) of its RNN changes, Perceiver therefore needs to recompute its RNN from scratch, requiring a linear amount of computation of O (NL), where N is the number of tokens and L is the number of latent variables. Consider attention as a many-to-many RNNTo target these limitations , the authors propose to develop an attention-based model that leverages the power of the RNN formulation to perform efficient updates. To this end, the author first introduced an efficient parallelization method, using attention as a many-to-many RNN calculation, that is, a method of parallel calculation
Methods to calculate attention: By considering attention as an RNN, you can see different ways to calculate attention: loop calculation token by token in O (1) memory (i.e. sequential calculation) ;or computed in the traditional way (i.e. parallel computing), which requires linear O (N) memory. Since attention can be regarded as an RNN, the traditional method of calculating attention can also be regarded as an efficient method of calculating the output of the attention many-to-one RNN, that is, the output of the RNN takes multiple context tokens as input, but in At the end of the RNN, only one token is output (see Figure 1a). Finally, attention can also be computed as an RNN that processes tokens chunk by chunk, rather than fully sequentially or fully in parallel, which requires O(b) memory, where b is the size of the chunk. Consider existing attention models as RNNs. By treating attention as an RNN, existing attention-based models can also be viewed as variants of RNN. For example, the Transformer's self-attention is an RNN (Figure 1b), and the context token is its initial hidden state. Perceiver’s cross-attention is an RNN (Figure 1c) whose initial hidden state is a context-dependent latent variable. By leveraging RNN forms of their attention mechanism, these existing models can efficiently compute their output stores. However, when considering existing attention-based models (such as Transformers) as RNNs, these models lack the features commonly seen in traditional RNNs (such as LSTM and GRU). important attributes. It is worth noting that LSTM and GRU can effectively update themselves with new tokens in only O(1) constant memory and computation, in contrast to Transformer's The RNN view (see Figure 1b) handles new tokens by adding a new RNN with the new token as the initial state. This new RNN processes all previous tokens, requiring O(N) linear computation. In Perceiver, due to its architecture, latent variables (L_i in Figure 1c) are input-dependent, which means that their values are dependent on receiving new tokens. will change from time to time. As the initial hidden state (i.e. latent variables) of its RNN changes, Perceiver therefore needs to recompute its RNN from scratch, requiring a linear amount of computation of O (NL), where N is the number of tokens and L is the number of latent variables. Consider attention as a many-to-many RNNTo target these limitations , the authors propose to develop an attention-based model that leverages the power of the RNN formulation to perform efficient updates. To this end, the author first introduced an efficient parallelization method, using attention as a many-to-many RNN calculation, that is, a method of parallel calculation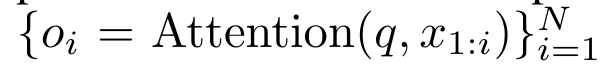 . To this end, the authors utilize the parallel prefix scan algorithm (see Algorithm 1), a parallel computing method that computes N prefixes from N consecutive data points via the correlation operator ⊕.This algorithm can efficiently calculate
. To this end, the authors utilize the parallel prefix scan algorithm (see Algorithm 1), a parallel computing method that computes N prefixes from N consecutive data points via the correlation operator ⊕.This algorithm can efficiently calculate 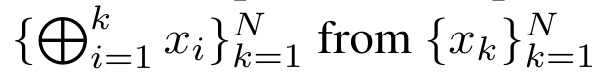 ##Review, where
##Review, where 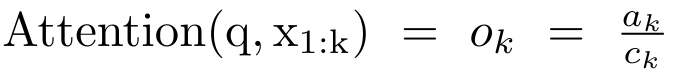
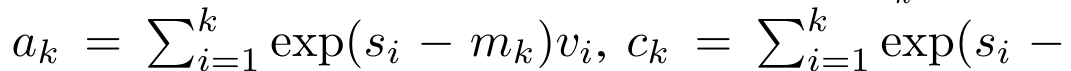 ,
, 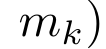 is for efficiency To calculate
is for efficiency To calculate 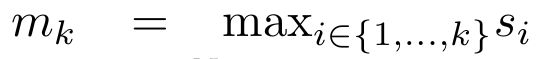 , you can calculate
, you can calculate  and
and 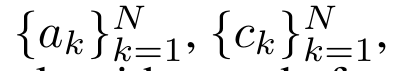 through a parallel scan algorithm, and then combine a_k and c_k to calculate
through a parallel scan algorithm, and then combine a_k and c_k to calculate  .
.  To this end, the author proposes the following correlation operator ⊕, which acts on the form (m_A, u_A, w_A) A triplet, where A is a set of indices, ,
To this end, the author proposes the following correlation operator ⊕, which acts on the form (m_A, u_A, w_A) A triplet, where A is a set of indices, , 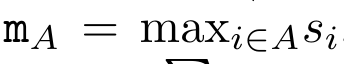
 ,
, 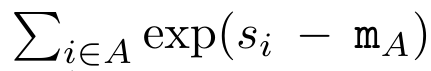
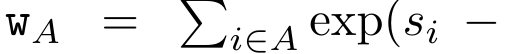 . The input to the parallel scan algorithm is
. The input to the parallel scan algorithm is 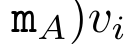 . The algorithm recursively applies the operator ⊕ and works as follows:
. The algorithm recursively applies the operator ⊕ and works as follows: 
, where 
 ,
, 
 .
.  After completing the recursive application of the operator, the algorithm outputs
After completing the recursive application of the operator, the algorithm outputs 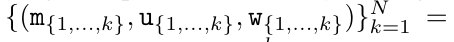
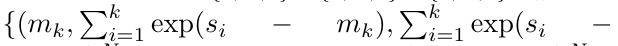
 . Also known as
. Also known as 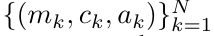 . Combining the last two values of the output tuple,
. Combining the last two values of the output tuple, 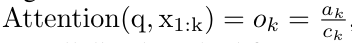 is retrieved resulting in an efficient parallel method of computing attention as a many-to-many RNN (Figure 3). ##Aaren:[A] attention [a] s a [re] current neural [n] etworkAaren's interface is the same as Transformer, that is, N inputs are mapped to N outputs, and the i-th output is the 1st to Aggregation of i inputs. In addition, Aaren is naturally stackable and can calculate separate loss terms for each sequence token. However, unlike Transformers that use causal self-attention, Aaren uses the above method of computing attention as a many-to-many RNN, making it more efficient. The form of Aaren is as follows:
is retrieved resulting in an efficient parallel method of computing attention as a many-to-many RNN (Figure 3). ##Aaren:[A] attention [a] s a [re] current neural [n] etworkAaren's interface is the same as Transformer, that is, N inputs are mapped to N outputs, and the i-th output is the 1st to Aggregation of i inputs. In addition, Aaren is naturally stackable and can calculate separate loss terms for each sequence token. However, unlike Transformers that use causal self-attention, Aaren uses the above method of computing attention as a many-to-many RNN, making it more efficient. The form of Aaren is as follows:
##Different from Transformer, the query in Transformer is input to attention One of the tokens, and in Aaren, the query token q is learned through backpropagation during the training process.
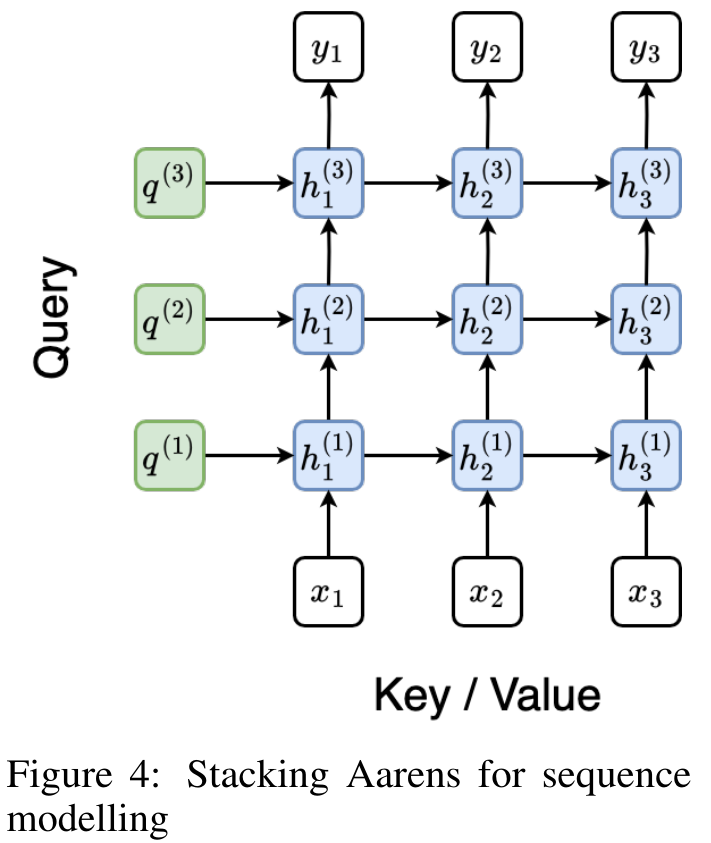
The following figure shows an example of a stacked Aaren model. The input context token of the model is x_1:3 and the output is y_1:3. It is worth noting that since Aaren utilizes the attention mechanism in the form of RNN, stacking Aarens is also equivalent to stacking RNN. Therefore, Aarens is also able to efficiently update with new tokens, i.e. the iterative computation of y_k only requires constant computation since it only depends on h_k-1 and x_k.
Transformer-based models require linear memory (when using KV cache) and need to store all Previous tokens, including those in the intermediate Transformer layer, but Aarens-based models only require constant memory and do not need to store all previous tokens, which makes Aarens significantly better than Transformer in computational efficiency. Experiment
The goal of the experimental part is to compare the performance and performance of Aaren and Transformer Performance in terms of resources (time and memory) required. For a comprehensive comparison, the authors performed evaluations on four problems: reinforcement learning, event prediction, time series prediction, and time series classification. Reinforcement Learning
The author first compared Aaren and Transformer in reinforcement learning Performance. Reinforcement learning is popular in interactive environments such as robotics, recommendation engines, and traffic control.
The results in Table 1 show that Aaren performs comparably with Transformer across all 12 datasets and 4 environments. However, unlike Transformer, Aaren is also an RNN and therefore can efficiently handle new environmental interactions in continuous computation, making it more suitable for reinforcement learning. Event prediction
Next, The authors compare the performance of Aaren and Transformer in event prediction. Event prediction is popular in many real-world settings, such as finance (e.g., transactions), healthcare (e.g., patient observation), and e-commerce (e.g., purchases).
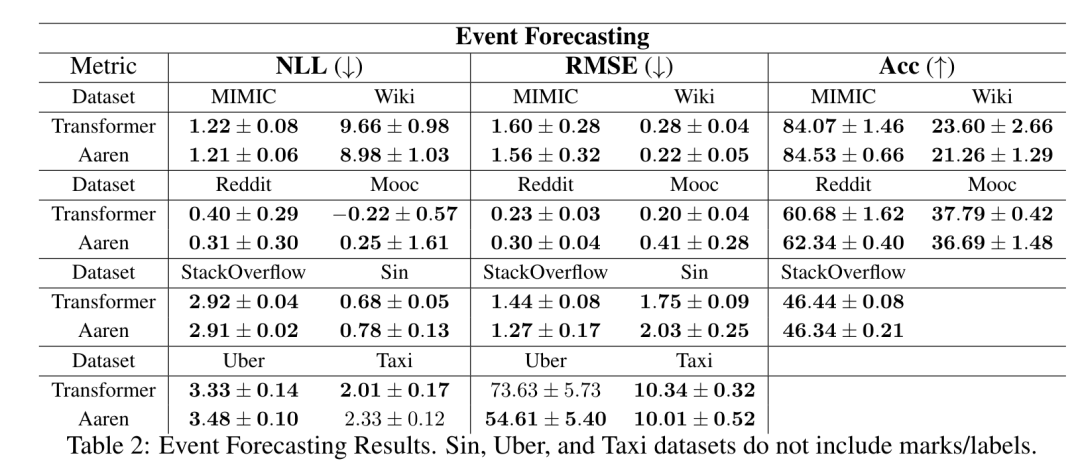
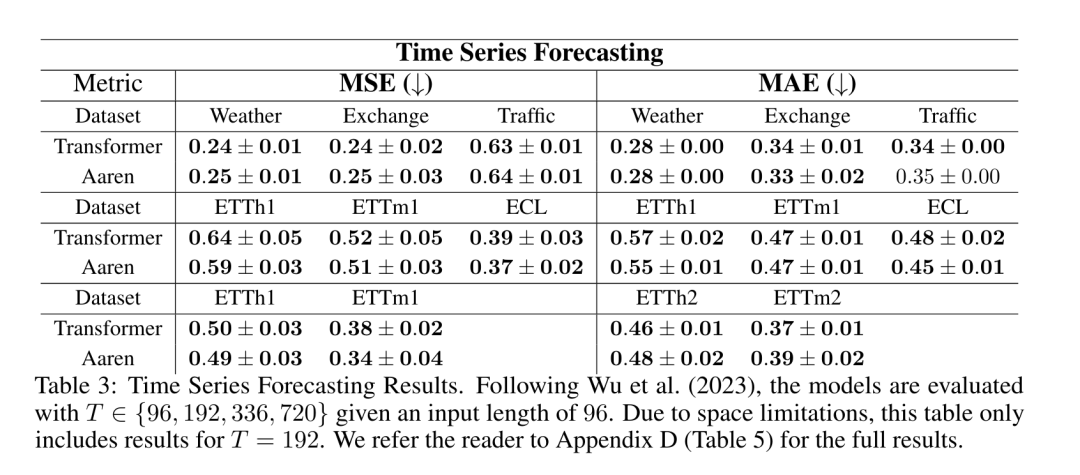
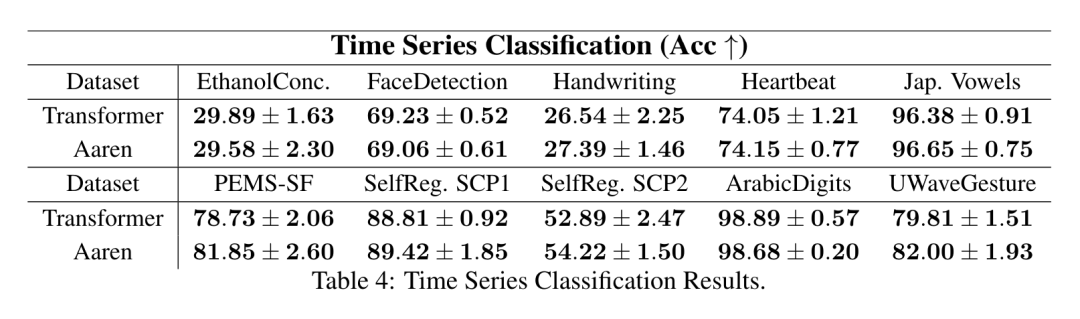
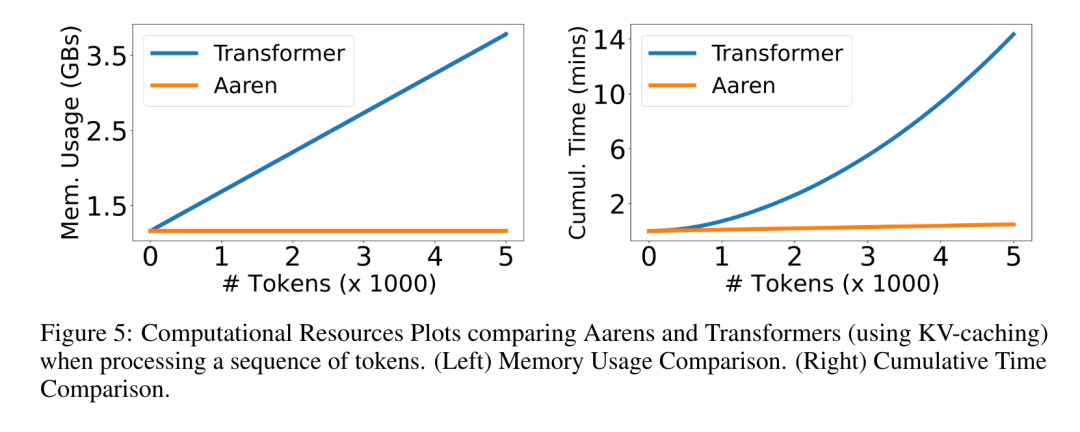
#The results in Table 2 show that Aaren performs comparably to Transformer on all datasets.Aaren's ability to efficiently process new inputs is particularly useful in event prediction environments, where events occur in irregular streams. Then, the author compared Aaren and Transformer in time series Performance in Forecasting. Time series forecasting models are commonly used in areas related to climate (such as weather), energy (such as supply and demand), and economics (such as stock prices). #The results in Table 3 show that Aaren performs comparably to Transformer on all datasets. However, unlike Transformer, Aaren can efficiently process time series data, making it more suitable for time series-related fields. Time series classificationNext, the author compared Aaren and Transformer in time Performance in sequence classification. Time series classification is common in many important applications, such as pattern recognition (e.g. electrocardiogram), anomaly detection (e.g. bank fraud) or fault prediction (e.g. power grid fluctuations). As can be seen from Table 4, the performance of Aaren and Transformer is comparable on all data sets. Finally, the author compares the resources required by Aaren and Transformer. Memory Complexity: In Figure 5 (left), the authors compare the memory usage of Aaren and Transformer (using KV cache) at inference time. It can be seen that with the use of KV cache technology, the memory usage of Transformer increases linearly. In contrast, Aaren only uses a constant amount of memory regardless of how the number of tokens grows, so it is much more efficient. Time complexity: In Figure 5 (right picture), the author compares the cumulative time required by Aaren and Transformer (using KV cache) to process a string of tokens in sequence. . For Transformer, the cumulative calculation amount is the square of the number of tokens, that is, O (1 + 2 + ... + N) = O (N^2). In contrast, Aaren's cumulative computational effort is linear. In the figure, you can see that the cumulative time required by the model has similar results. Specifically, the cumulative time required by Transformer increases quadratically, while the cumulative time required by Aaren increases linearly. Number of parameters: Due to the need to learn the initial hidden state q, the Aaren module requires slightly more parameters than the Transformer module. However, since q is just a vector, the difference is not significant. Through empirical measurements on similar models, the authors found that Transformer used 3, 152, 384 parameters. By comparison, the equivalent Aaren uses 3,152,896 parameters, a parameter increase of only 0.016%—a negligible price to pay for the significant difference in memory and time complexity.
The above is the detailed content of New work by Bengio et al.: Attention can be regarded as RNN. The new model is comparable to Transformer, but is super memory-saving.. For more information, please follow other related articles on the PHP Chinese website!




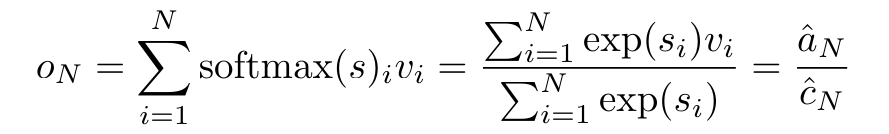


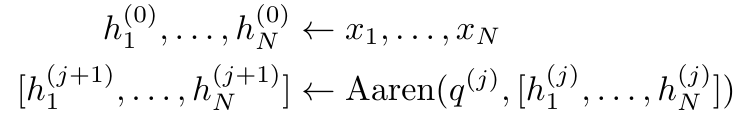

 How to install wordpress after downloading it
How to install wordpress after downloading it
 What does win11 activation status activity mean?
What does win11 activation status activity mean?
 Website creation software
Website creation software
 What are the regular expressions in php
What are the regular expressions in php
 The difference between array pointer and pointer array
The difference between array pointer and pointer array
 What are the cloud servers?
What are the cloud servers?
 python absolute value
python absolute value
 Implementation method of VUE next page function
Implementation method of VUE next page function








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



