


The deep reinforcement learning team of the Institute of Automation, Chinese Academy of Sciences, together with Li Auto and others, proposed a new closed-loop planning framework for autonomous driving based on the multimodal large language model MLLM—PlanAgent. This method takes a bird's-eye view of the scene and graph-based text prompts as input, and uses the multi-modal understanding and common sense reasoning capabilities of the multi-modal large language model to perform hierarchical reasoning from scene understanding to the generation of horizontal and vertical movement instructions, and Further generate the instructions required by the planner. The method is tested on the large-scale and challenging nuPlan benchmark, and experiments show that PlanAgent achieves state-of-the-art (SOTA) performance on both regular and long-tail scenarios. Compared with conventional large language model (LLM) methods, the amount of scene description tokens required by PlanAgent is only about 1/3.
Paper information

As the core module of autonomous driving One, the goal of motion planning is to generate a safe and comfortable optimal trajectory. Rule-based algorithms, such as the PDM [1] algorithm, perform well in handling common scenarios, but are often difficult to cope with long-tail scenarios that require more complex driving operations [2]. Learning-based algorithms [2,3] often overfit in long-tail situations, resulting in performance in nuPlan that is not as good as the rule-based method PDM.
Recently, the development of large language models has opened up new possibilities for autonomous driving planning. Some recent research attempts to use the powerful reasoning capabilities of large language models to enhance the planning and control capabilities of autonomous driving algorithms. However, they encountered some problems: (1) The experimental environment was not based on real closed environment scenarios (2) Using a number of coordinate numbers to represent map details or motion status greatly increased the number of required tokens; (3) ) It is difficult to ensure safety by directly generating trajectory points from a large language model. To address the above challenges, this paper proposes the PlanAgent method.
The MLLM-based closed-loop planning agent PlanAgent framework is shown in Figure 1. This paper designs three modules to solve the problem of automatic Complex issues in driving:
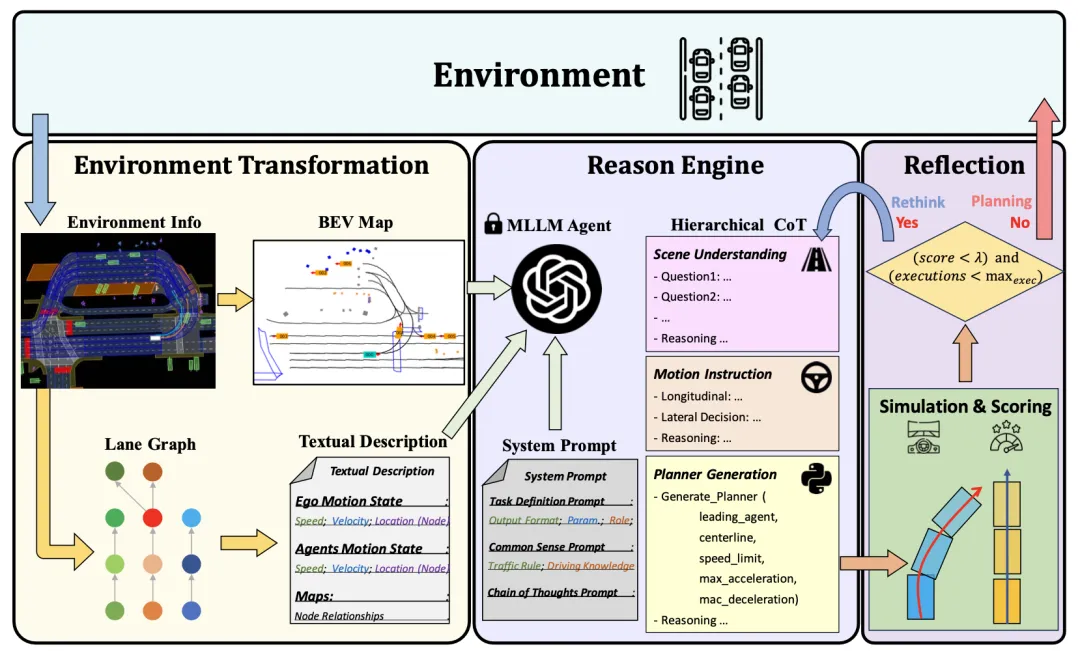
Figure 1 The overall framework of PlanAgent, including the scene information extraction/reasoning/reflection module
The prompt words (prompt) in the large language model have an important impact on the quality of the output it generates. In order to improve the generation quality of MLLM, the scene information extraction module can extract the scene context information and convert it into a bird view (BEV) image and text representation, making it consistent with the input of MLLM. First, this paper converts scene information into Bird Escape (BEV) images to enhance MLLM's ability to understand the global scene. At the same time, the road information needs to be represented graphically, as shown in Figure 2. On this basis, key vehicle motion information is extracted, so that MLLM can focus on the area most relevant to its own position.
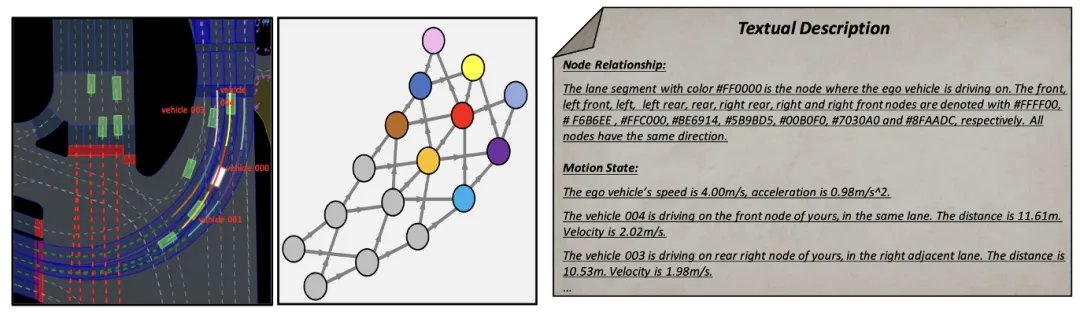
Figure 2 Text prompt description based on graph representation
How to introduce the reasoning capabilities of large language models into the autonomous driving planning process and realize a planning system with common sense reasoning capabilities is a key issue. The method designed in this article can take user messages containing current scene information and predefined system messages as input, and generate the planner code of the intelligent driver model (IDM) through multiple rounds of reasoning in the hierarchical thinking chain. As a result, PlanAgent can embed the powerful reasoning capabilities of MLLM into autonomous driving planning tasks through contextual learning.
Among them, the user message includes BEV coding and surrounding vehicle motion information extracted based on graph representation. System messages include task definition, common sense knowledge and thinking chain steps, as shown in Figure 3.

Figure 3 System prompt template
After getting the prompt information, MLLM will reason about the current scene from three levels: scene understanding, motion instructions and code generation, and finally generate the code of the planner. In PlanAgent, car following, center line, speed limit, maximum acceleration and maximum deceleration parameter codes will be generated, and then the instantaneous acceleration in a certain scene will be generated by IDM, and finally a trajectory will be generated.
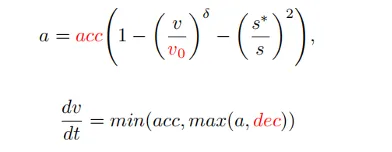
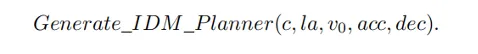
Pass the above two modules Strengthens MLLM's understanding and reasoning capabilities of scenarios. However, the illusion of MLLM still poses a challenge to the safety of autonomous driving. Inspired by human beings’ decision-making process of “thinking twice before leaping”, this article adds a reflection mechanism to the algorithm design. Simulate the planner generated by MLLM, and evaluate the planner's driving score through indicators such as collision likelihood, driving distance, and comfort. When the score is lower than a certain threshold τ, it indicates that the planner generated by MLLM is inadequate, and MLLM will be requested to regenerate the planner.
This paper conducts closed-loop planning experiments on nuPlan[4], a closed-loop planning platform for large-scale real scenarios, to evaluate PlanAgent performance, the experimental results are as follows.
Table 1 Comparison between PlanAgent and other algorithms on nuPlan’s val14 and test-hard benchmarks
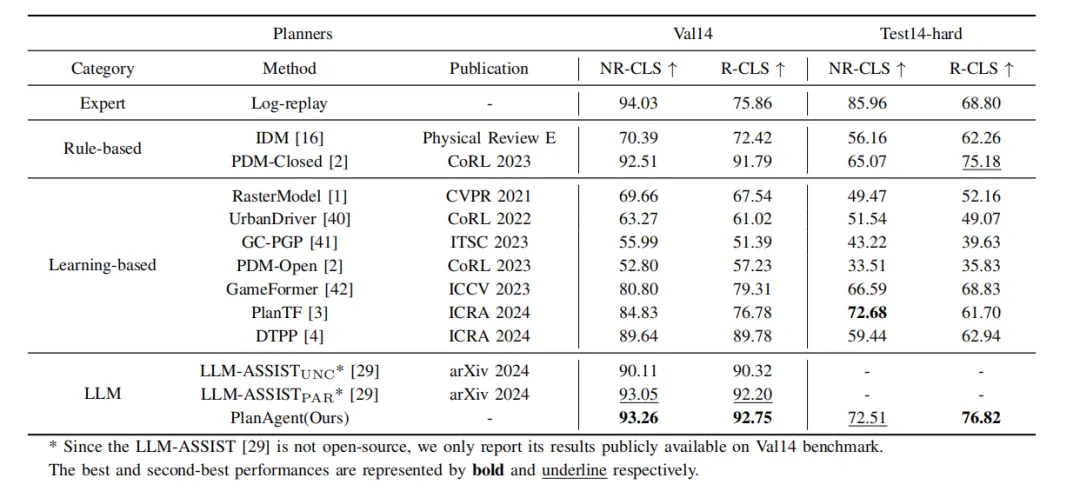
As shown in Table 1, this article compares the proposed PlanAgent with three types of cutting-edge algorithms, and compares the two of nuPlan Tested on benchmark val14 and test-hard. PlanAgent shows competitive and generalizable results compared with other methods.
Table 2 Comparison of tokens used by different methods to describe scenarios
# #At the same time, PlanAgent uses fewer tokens than other methods based on large models. As shown in Table 2, it only requires 1/3 of GPT-Driver[5] or LLM-ASSIST[6]. This shows that PlanAgent can describe the scene more effectively with fewer tokens. This is especially important for the use of closed-source large language models.
Table 3 Ablation experiment of different parts in the scene extraction module
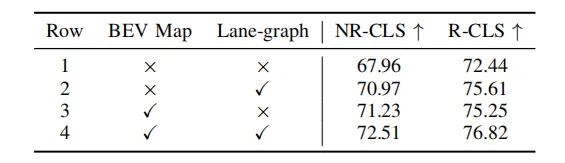
Table 4 Ablation experiments of different parts in the hierarchical thinking chain
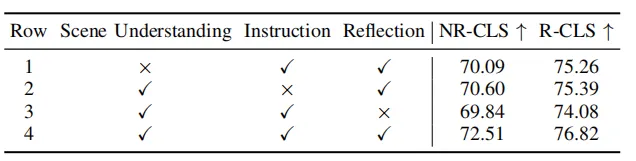
##As shown in Table 3 and 4. This paper conducts ablation experiments on different parts of the scene information extraction module and reasoning module. The experiments prove the effectiveness and necessity of each module. MLLM's understanding of the scene can be enhanced through BEV image and graph representation, and MLLM's reasoning ability for the scene can be enhanced through hierarchical thinking chains.
Table 5 Experiments of PlanAgent on different language models
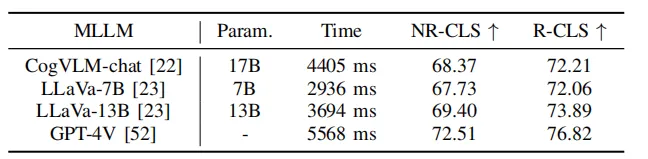
At the same time , as shown in Table 5, this article uses some open source large language models for testing. Experimental results show that on the Test-hard NR-CLS benchmark, PlanAgent using different large language models can achieve 4.1%, 5.1% and 6.7% higher driving scores than PDM-Closed respectively. This demonstrates PlanAgent’s compatibility with various multi-modal large language models.
PDM selects the outside lane as the centerline, and the vehicle drives on the outside lane. The vehicle got stuck while merging. PlanAgent determines that a vehicle is merging, outputs a reasonable left lane change command, and generates a lateral action to select the inner lane of the roundabout as centerline, and the vehicle drives on the inner lane.

PDM selected the traffic light category as the car following category. PlanAgent outputs reasonable instructions and selects the stop line as the car-following category.
This paper proposes a new MLLM-based closed-loop planning framework for autonomous driving, called PlanAgent. This method introduces a scene information extraction module to extract BEV images and extract the motion information of surrounding vehicles based on the graph representation of the road. At the same time, a reasoning module with a hierarchical structure is proposed to guide MLLM to understand scene information, generate motion instructions, and finally generate planner code. In addition, PlanAgent also imitates human decision-making for reflection, and re-plans when the trajectory score is lower than the threshold to enhance the safety of decision-making. The autonomous driving closed-loop planning agent PlanAgent based on the multi-modal large model has achieved SOTA performance in closed-loop planning on the nuPlan benchmark.
The above is the detailed content of Towards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



