


In the era of Transformer unification, is it still necessary to study the CNN direction of computer vision?
At the beginning of this year, OpenAI’s large video model Sora made the Vision Transformer (ViT) architecture popular. Since then, there has been an ongoing debate about who is more powerful, ViT or traditional convolutional neural networks (CNN).
Recently, Yann LeCun, Turing Award winner and Meta chief scientist who has been active on social media, has also joined the discussion on the dispute between ViT and CNN.

The cause of this incident was that Harald Schäfer, CTO of Comma.ai, was showing off his latest research. He (like many recent AI scholars) cue Yann LeCun's expression that although the Turing Award tycoon believes that pure ViT is not practical, we have recently changed our compressor to pure ViT. There is no quick gain and it will take longer. training, but the effect is very good.
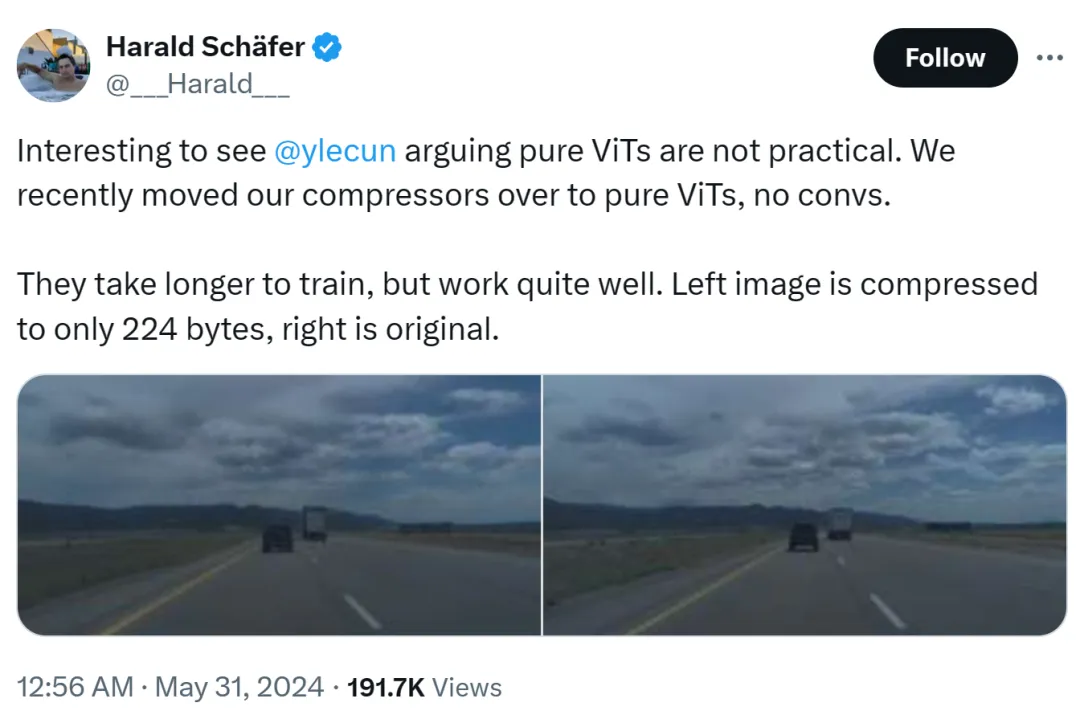
For example, the image on the left is compressed to only 224 bytes, and the right is the original image.
Only 14×128, which is very large for the world model used for autonomous driving, which means that a large amount of data can be input for training. Training in a virtual environment is less expensive than in a real environment, where agents need to be trained according to policies to work properly. Higher resolutions for virtual training will work better, but the simulator will become very slow, so compression is necessary for now.
His demonstration sparked discussion in the AI circle, and Eric Jang, vice president of artificial intelligence at 1X, replied that the results were amazing.
Harald continued to praise ViT: It is a very beautiful architecture.
Someone started to get angry here: Masters like LeCun sometimes fail to keep up with the pace of innovation.
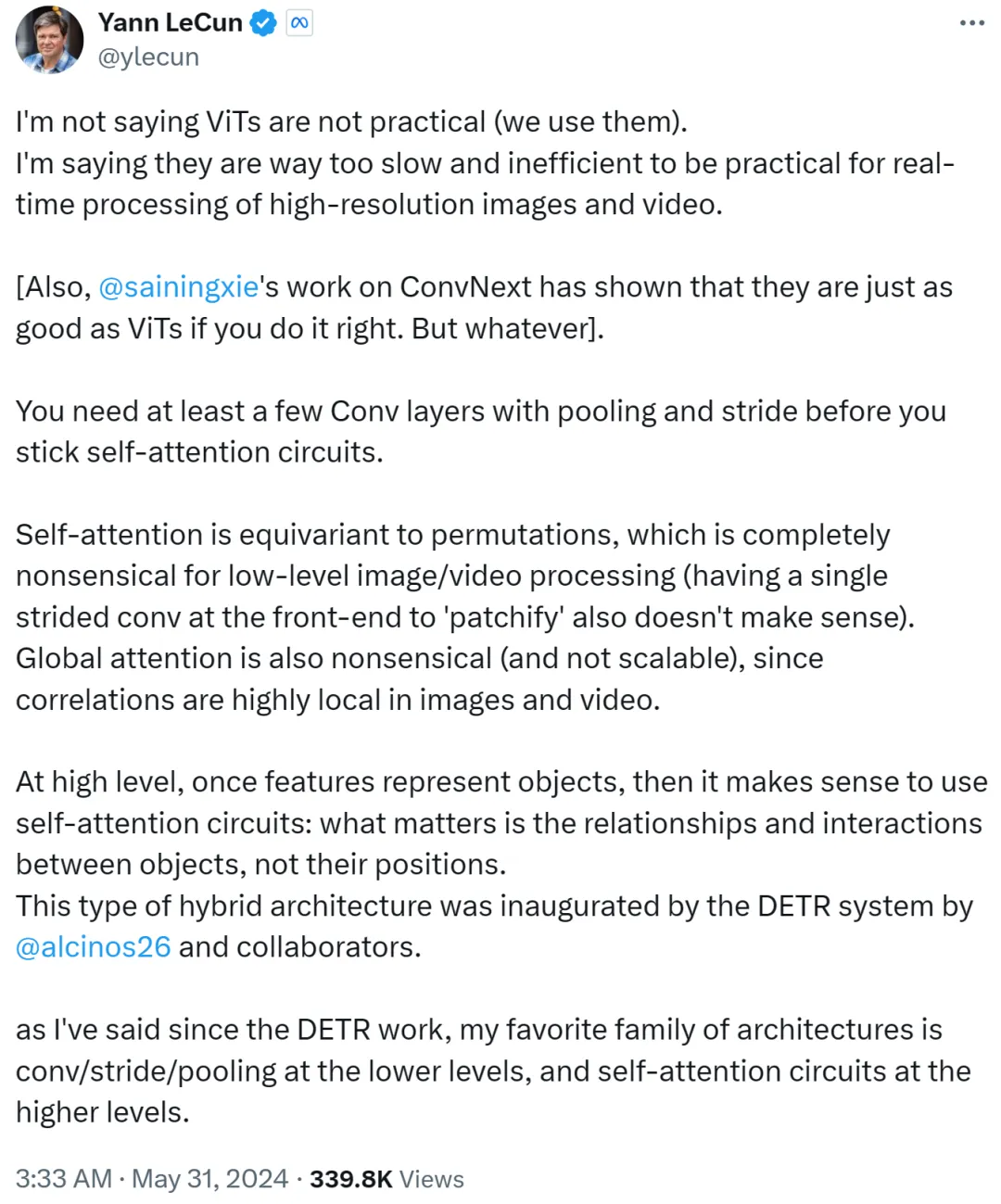
However, Yann LeCun quickly replied and argued that he was not saying that ViT is not practical, and everyone is using it now it. What he wants to express is that ViT is too slow and inefficient, making it unsuitable for real-time processing of high-resolution image and video tasks.
Yann LeCun also Cue Xie Saining, an assistant professor at New York University, whose work ConvNext proved that CNN can be as good as ViT if the method is right.
He goes on to say that you need at least a few convolutional layers with pooling and strides before sticking to a self-attention loop.
If self-attention is equivalent to permutation, it makes no sense at all for low-level image or video processing, nor does using a single stride for patchify on the front end. In addition, since the correlation in images or videos is highly concentrated locally, global attention is meaningless and unscalable.
At a higher level, once features represent objects, then using a self-attention loop makes sense: it is the relationships and interactions between objects that matter, not their Location. This hybrid architecture was pioneered by the DETR system completed by Meta research scientist Nicolas Carion and co-authors.
Since the emergence of DETR work, Yann LeCun said that his favorite architecture is low-level convolution/stride/pooling, and high-level self-attention loop.
Yann LeCun summed it up in the second post: use convolution with stride or pooling at low level, and at high level Use a self-attention loop and use feature vectors to represent objects.
He also bets that Tesla Fully Self-Driving (FSD) uses convolutions (or more complex local operators) at low levels and combines more at higher levels Global loop (possibly using self-attention). Therefore, using Transformers on low-level patch embeddings is a complete waste.
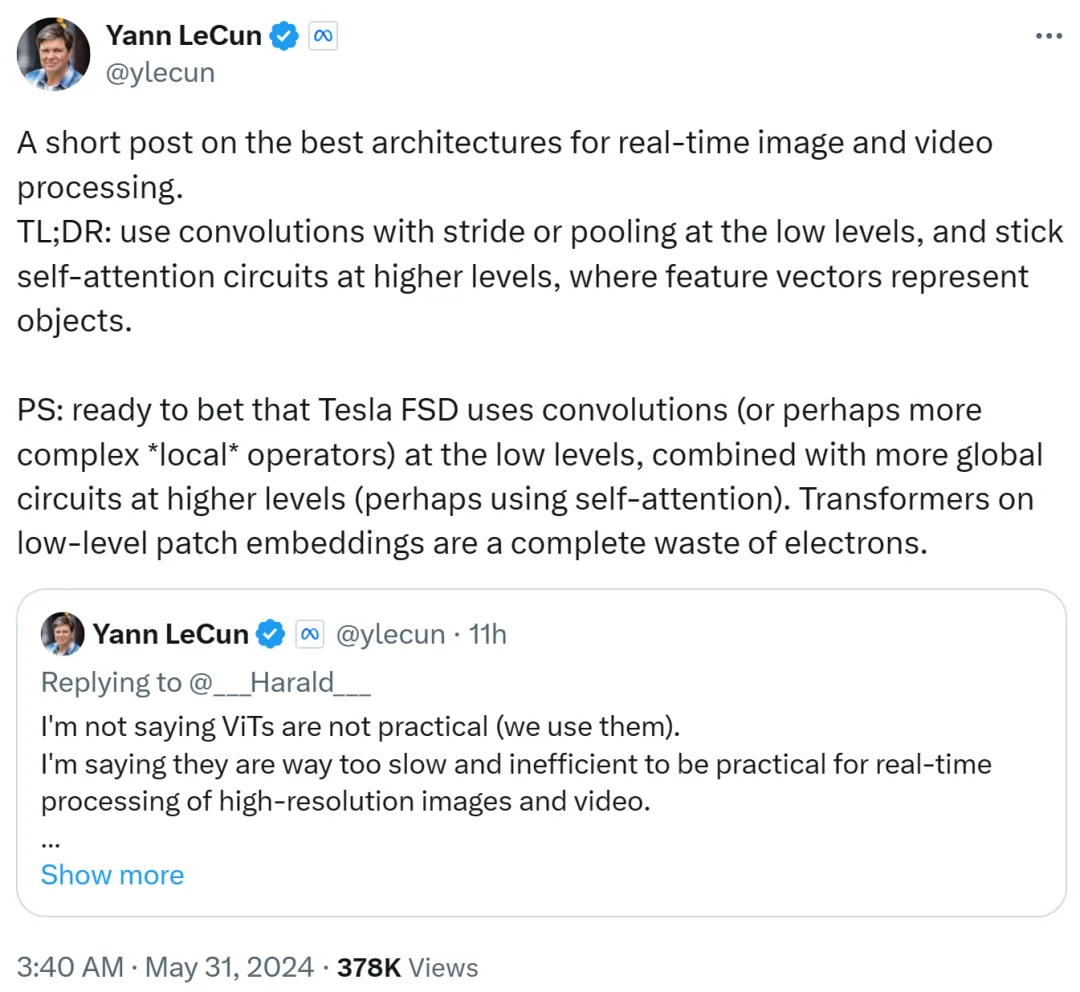
I guess that the archenemy Musk still uses the convolution route.
Xie Saining also expressed his opinion. He believes that ViT is very suitable for low-resolution images of 224x224, but what should we do if the image resolution reaches 1 million x 1 million? At this time, either convolution is used, or ViT is patched and processed using shared weights, which is still convolution in nature.
Therefore, Xie Saining said that there was a moment when he realized that the convolutional network was not an architecture, but a way of thinking.
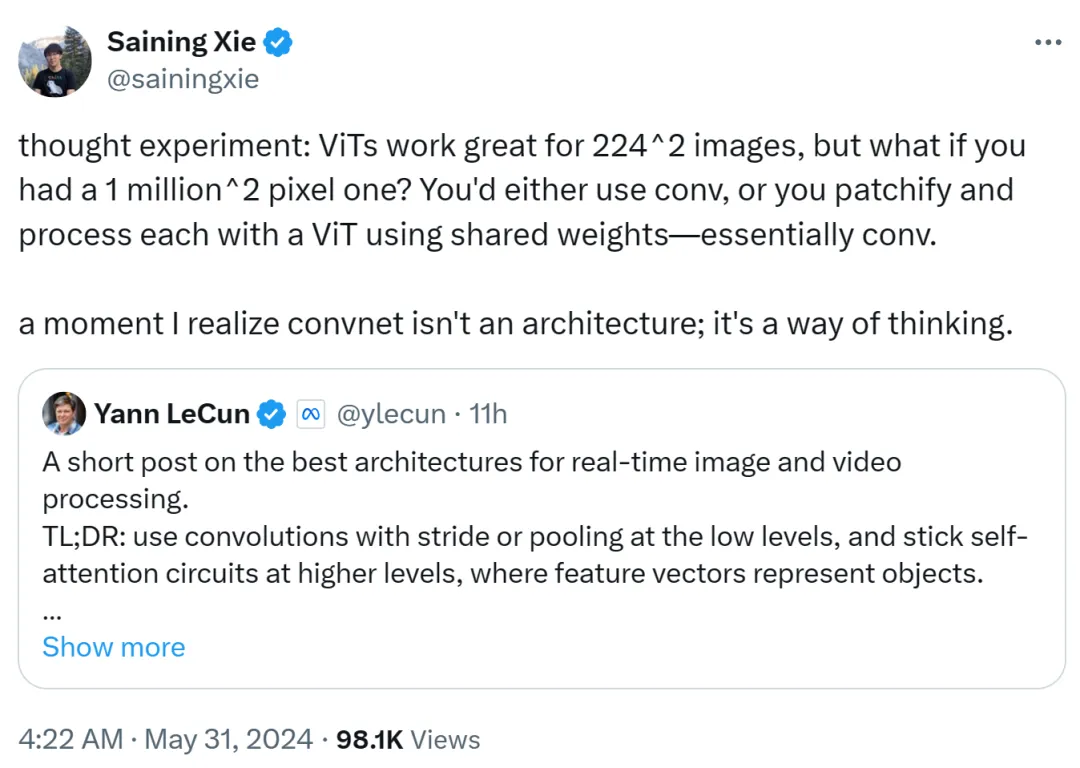
This view is recognized by Yann LeCun.

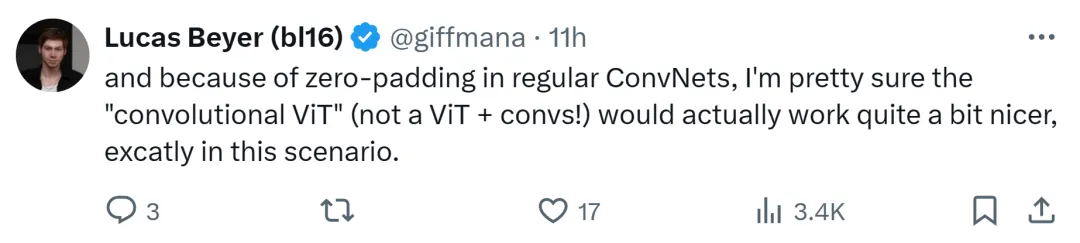
Google DeepMind researcher Lucas Beyer also said that thanks to the zero padding of conventional convolutional networks, he is very sure "Convolution ViT" (instead of ViT + convolution) will work well.
##It is foreseeable that this debate between ViT and CNN will continue until another update is made in the future. The emergence of powerful architecture.
The above is the detailed content of Yann LeCun: ViT is slow and inefficient. Real-time image processing still depends on convolution.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



